글로벌 반도체 시장이 또 한 번 거대한 패러다임 시프트(Paradigm Shift)를 맞이하고 있습니다. 우리는 지난 몇 년간 인공지능(AI) 열풍 속에서 고대역폭 메모리, 즉 HBM(High Bandwidth Memory)이 가져온 전례 없는 초호황기를 목도했습니다. 엔비디아의 GPU 옆에 단단히 자리 잡은 HBM은 학습용 AI 시장의 절대적인 왕좌였습니다.
그러나 영원한 왕좌는 없습니다. 현재 AI 시장의 무게중심은 막대한 데이터를 집어넣고 학습시키는 ‘학습(Training)’ 단계에서, 전 세계 수억 명의 사용자가 시도 때도 없이 던지는 질문에 실시간으로 답을 내놓는 ‘추론(Inference)’ 단계로 급격히 이동하고 있습니다.
여기서 치명적인 병목 현상이 발생합니다. 바로 ‘전력 소모와 발열’입니다. HBM은 엄청나게 빠르지만 그만큼 막대한 전기를 잡아먹는 ‘헤비 드링커(Heavy Drinker)’입니다. 전 세계 데이터센터가 전기 고갈과 발열 문제로 비명을 지르기 시작하면서, 글로벌 테크 giants들과 반도체 제조사들은 차세대 첨단 저전력 메모리 개발에 사활을 걸었습니다.
오늘은 포스트 HBM 시대를 지배하기 위해 등장한 5가지 핵심 차세대 메모리 기술(HBC, SOCAMM, HBF, ZAM, PIM)을 엔지니어링 관점에서 낱낱이 해부하고, 어떤 기업이 제2의 HBM 신화를 재현하며 투자자들에게 도움이 될 포괄적인 투자 가이던스를 전해드립니다.
1. 배경: AI 패러다임의 변화와 폰 노이만 병목 현상
컴퓨터 아키텍처 역사를 돌이켜보면 PC 시대에는 ‘CPU 속도’가, 모바일 시대에는 ‘저전력 D램’이 시장을 지배했습니다. AI 초기 시장 역시 엄청난 매개변수(Parameter)를 가진 거대언어모델(LLM)을 한시라도 빨리 학습시켜야 했기에, 가격과 전력은 후순위였고 오직 대역폭(Bandwidth)만을 극대화한 HBM이 시장을 독식했습니다.
하지만 ‘추론’의 시대는 게임의 법칙이 완전히 다릅니다.
학습(Training): 대형 데이터 플러그를 꽂아두고 한 번에 몰아서 무거운 연산을 수행합니다.
추론(Inference): 수억 명의 전 세계 유저가 24시간 내내 모바일과 PC로 AI 서비스를 호출합니다. 데이터의 이동이 극도로 잦고 반복적입니다.
문제는 데이터가 메모리 저장소와 연산 장치(CPU/GPU) 사이를 오가는 과정에서 발생하는 전력 소모(Data Movement Power)가 전체 시스템 전력의 60~80%를 차지한다는 점입니다. 프로세서의 계산 속도는 광속으로 발전했지만, 메모리에서 데이터를 주고받는 버스(Bus)의 대역폭과 전력 효율이 이를 따라가지 못하는 ‘폰 노이만 병목 현상(Von Neumann Bottleneck)’이 한계에 다다른 것입니다.
결국 미래 AI 반도체 경쟁의 핵심 철학은 명확합니다. “누가 더 빠른가”가 아니라, “누가 데이터 이동을 최소화하여 전력을 아끼는가”의 싸움입니다. 이제 그 대안으로 떠오른 5가지 독자적인 생태계를 하나씩 뜯어보겠습니다.
2. 포스트 HBM을 노리는 5대 차세대 기술 심층 분석
① HBC (High Bandwidth Compute) : 퀄컴의 근접 연산과 3D 적층
기존 HBM 구조는 GPU ‘옆’에 인터포저(Interposer)라는 중간 기판을 두고 수평으로 데이터 통로를 연결합니다. 눈에 보이지 않을 만큼 미세하지만 물리적인 선로의 길이가 존재하며, 여기서 신호 손실과 전력 소모가 발생합니다.
모바일 AP 설계의 최강자인 미국 퀄컴이 제시한 HBC(고대역폭 컴퓨트)는 이 구조를 완전히 뒤집습니다.
엔지니어링 핵심: 근접 연산(Near-Memory Computing) 및 3D 로직-메모리 적층
구조적 특징: AI 연산을 담당하는 가속기(Logic Die) 바로 위에 저전력 D램(LPDDR)을 수직으로 다이렉트 적층(3D Stacking)합니다. 데이터가 이동하는 거리가 마이크로미터(㎛) 단위로 좁혀집니다.
성능 강점: 모든 데이터를 가속기 중심부로 보내지 않고, 메모리와 맞닿은 최단 거리에서 먼저 일부 계산을 처리한 뒤 꼭 필요한 결과만 상부로 전달합니다. 퀄컴은 이 방식을 통해 HBM 대비 와트당 대역폭(전력 효율성)을 무려 6배나 끌어올릴 수 있다고 발표했습니다. 모바일에서 갈고닦은 저전력 DNA를 서버 시장에 이식하겠다는 야심찬 구상입니다.
② SOCAMM (Small Outline Compression Attached Memory Module) : 엔비디아의 모듈 표준 파괴
스마트폰에 탑재되는 LPDDR(저전력 D램)은 전력 효율면에서 최상의 퍼포먼스를 보여줍니다. 하지만 치명적인 약점이 있었습니다. 메인보드에 직접 납땜(On-board)해야만 고속 신호의 무결성(Signal Integrity)이 유지된다는 점입니다. 이 때문에 서버 환경처럼 필요에 따라 슬롯에 꼈다 뺐다 하며 용량을 확장해야 하는 데이터센터에는 사용이 불가능했습니다.
이 한계를 깨부순 것이 바로 엔비디아가 주도하는 SOCAMM(소캠) 규격입니다.
엔지니어링 핵심: 소켓 압착 방식을 통한 LPDDR의 서버화
구조적 특징: 보드에 납땜하는 대신, 기판에 매우 얇은 소켓 형태로 메모리 모듈을 ‘압착’하여 연결합니다. 커넥터의 물리적 길이를 극한으로 줄여 LPDDR의 초저전력 특성을 고스란히 유지하면서도, 서버가 요구하는 고용량 확장성과 교체 편의성을 확보했습니다.
실제 적용: 엔비디아의 차세대 로드맵을 보면 매우 흥미로운 전략이 보입니다. 최고 속도가 필요한 GPU(루빈 등)에는 최첨단 HBM4를 탑재하지만, 대용량 데이터 제어와 효율성이 중요한 CPU(베라)에는 SOCAMM2를 채택했습니다. 비용과 전력을 모두 잡겠다는 계산입니다. 현재 국내 메모리 거두인 삼성전자와 SK하이닉스가 이 SOCAMM2 모듈을 개발하여 엔비디아 공급망에 진입해 있습니다.
③ HBF (High Bandwidth Flash) : 낸드플래시 기반 대형 보관함의 등장
컴퓨터 구조론에서 ‘레지스터-캐시-D램-저장장치(SSD)’로 이어지는 단단한 계층 구조(Memory Hierarchy)는 수십 년간 변하지 않는 진리였습니다. 하지만 LLM 추론 모델이 커지면서 수천억 개의 매개변수 데이터를 전부 비싼 D램(HBM)에 상주시키는 것은 가성비 측면에서 재앙에 가깝습니다. 여기서 등장한 파괴적 혁신이 HBF(고대역폭 플래시)입니다.
엔지니어링 핵심: 비휘발성 초고속 낸드 적층 및 하이브리드 계층화
구조적 특징: 전원이 꺼져도 데이터가 지워지지 않고, D램보다 동일 면적당 저장 용량이 수 배 이상 크며 가격은 저렴한 ‘낸드플래시’를 HBM처럼 수직으로 쌓아 올린 형태입니다.
비유와 협업: HBM이 AI 프로세서 바로 옆에서 데이터를 실시간으로 빠르게 주고받는 ‘작업대’라면, HBF는 그 바로 뒤에 위치한 ‘초대형 고속 보관함’입니다. 실시간 연산에 필요한 핵심 가중치는 HBM에 올려두고, 자주 꺼내 쓰지만 매 순간 대기할 필요는 없는 거대한 데이터 베이스는 HBF에 저장해 둡니다. 가상 메모리 스왑 속도를 극대화한 이 기술은 미국 샌디스크(웨스턴디지털)가 표준화를 이끌고 있으며, SK하이닉스가 연합군으로 참여해 생태계를 키우고 있습니다.
④ ZAM (Z-Angle Memory) : 인텔의 물리적 공정 우회 전략
HBM의 가장 큰 기술적 장벽이자 아킬레스건은 D램 칩 수천 개에 미세한 구멍을 뚫어 수직으로 연결하는 TSV(실리콘 관통 전극) 공정입니다. 수직으로 곧게 뚫린 통로를 통해 엄청난 양의 전류가 흐르다 보니, 칩 내부의 열이 밖으로 빠져나가지 못하고 상층부에 고여 칩이 오작동하는 ‘열 축적(Thermal Throttling)’ 문제가 끊임없이 발생합니다.
인텔과 소프트뱅크의 자회사 사이메모리가 공동 개발 중인 ZAM(Z-앵글 메모리)은 물리적 접근법을 바꿨습니다.
엔지니어링 핵심: 사선 실리콘 관통 전극 (Angled TSV)
구조적 특징: 건물의 엘리베이터처럼 수직으로만 통로를 뚫는 것이 아니라, 에스컬레이터처럼 비스듬한 사선 각도(Z-Angle)로 데이터 통로를 배치합니다.
기대 효과: 신호가 오가는 경로의 면적이 넓어지면서 자연스럽게 칩 내부의 열 발산 면적이 확대됩니다. 또한, 신호선끼리 수직으로 마주 볼 때 발생하는 전기적 간섭(Crosstalk)을 줄여 전력 효율을 개선할 수 있습니다. 다만, 딱딱한 실리콘을 사선으로 정밀하게 식각(Etching)하는 공정 난이도가 극악에 가깝기 때문에 양산성 검증이 향후 상용화의 가늠쇠가 될 것입니다.
⑤ PIM (Processing In Memory) : 폰 노이만 구조의 완벽한 종말
앞서 언급한 네 가지 기술이 메모리와 프로세서 간의 ‘거리’를 좁히거나 ‘통로’를 개선하는 방식이라면, PIM(프로세싱 인 메모리)은 컴퓨터의 패러다임 자체를 부정하는 가장 궁극적이고 혁신적인 개념입니다.
엔지니어링 핵심: 메모리 뱅크(Bank) 내 독립 연산기(ALU) 내장
구조적 특징: 기존 메모리는 오직 ‘저장’만 하고 계산은 CPU나 GPU가 도맡았습니다. PIM은 데이터가 저장되는 메모리 셀 내부 영역에 아주 단순한 계산이 가능한 연산 장치들을 곳곳에 심어 놓았습니다.
비유와 장점: 물건이 들어올 때마다 멀리 있는 본사 직원이 와서 분류하는 게 아니라, 창고(메모리) 안에 상주하는 직원이 그 자리에서 직접 물건을 분류(연산)해 결과만 보고하는 시스템입니다. AI 연산의 대부분을 차지하는 단순 반복 행렬 계산(GEMM)을 메모리가 직접 수행하므로, 데이터를 외부 버스로 전송할 필요가 전혀 없습니다. 데이터 이동 에너지가 ‘제로(0)’에 수렴하기 때문에 전력 효율면에서는 이론상 완벽한 종착지입니다. 현재 삼성전자와 SK하이닉스가 LPDDR 기반의 PIM 제품을 고도화하며 상용화를 앞당기고 있습니다.
3. 차세대 메모리 기술 한눈에 비교하기
기술 규격
핵심 구조 및 아이디어
주도 기업 / 진영
전력 절감 메커니즘
성숙도 및 상용화 시점
HBC
가속기 로직 다이 위에 LPDDR을 3D 수직 적층
퀄컴
패키징 다이렉트 연결로 이동 거리 최소화
프로토타입 공개 단계
SOCAMM
LPDDR 모듈을 소켓 압착 방식으로 서버 기판에 연결
엔비디아, 삼성전자, SK하이닉스
저전력 모바일 D램의 서버 확장
상용화 돌입 (베라 CPU 탑재)
HBF
초고속 낸드플래시를 수직 적층하여 서버 근접 배치
샌디스크, SK하이닉스
대용량 데이터의 계층 최적화 (가성비)
규격 표준화 진행 중
ZAM
D램 관통 전극(TSV)을 사선(Diagonal)으로 배치
인텔, 사이메모리
사선 배치를 통한 열 발산 및 간섭 저감
연구 개발 및 공정 검증 단계
PIM
메모리 내부 뱅크에 단순 연산 장치(ALU) 내장
삼성전자, SK하이닉스
데이터 이동 자체를 삭제 (버스 전력 0)
실증 테스트 및 생태계 확장 중
4. 투자 가이던스 (Investment Guidance)
기술의 우수성을 아는 것과 돈이 되는 기업을 고르는 것은 별개의 영역입니다. 주식 시장에서는 ‘가장 완벽한 기술’보다 ‘당장 대량 양산되어 밸류체인의 숫자로 찍히는 기술’이 먼저 가치를 인정받습니다. 시장의 자금 흐름과 기술 성숙도를 고려해 단기(1~2년)와 중장기(3~5년) 투트랙(Two-Track) 전략을 제시합니다.
💡 단기 관점 (1~2년): 매출 가시성이 확보된 ‘SOCAMM’ 공급망에 집중
현재 엔비디아의 서버 아키텍처에 채택이 확정되어 당장 올해와 내년 실적 턴어라운드를 이끌 영역은 단연 SOCAMM입니다. 데이터센터 전력지난은 당장 발등에 떨어진 불이기 때문에, 검증된 LPDDR 모듈 채택 속도는 상상을 초월할 것입니다.
최선호주 (Top Picks):SK하이닉스 & 삼성전자
서버용 고성능 LPDDR5X 및 LPDDR6 시장의 글로벌 점유율을 사실상 독점하고 있는 구조입니다. SOCAMM 모듈 공급이 본격화되면 레거시 D램 대비 압도적인 마진율 개선이 이루어집니다.
장비 및 부품 수혜주:첨단 후공정(OSAT) 및 패키지 기판사
커넥터 길이를 줄이고 미세 압착 기법을 적용해야 하는 고난도 모듈 가공 기술 특성상, 플 flip-chip 계열의 고부가 패키지 기판을 공급할 수 있는 삼성전기, 대덕전자 같은 기판 대형주와 후공정 검사 및 레이저 장비 공급사의 가치 재평가(Re-rating)가 강하게 나올 것입니다.
💡 중장기 관점 (3~5년): 판도를 바꿀 게임 체인저 ‘HBF’와 ‘PIM’ 선점
AI 추론 시장이 완전히 성숙하여 전체 AI 서버 수요의 80%를 넘어가는 시점이 오면, 단순히 D램을 튜닝하는 수준을 넘어 아키텍처 전반을 바꾸는 기업이 수조 원의 가치를 흡수합니다.
낸드(NAND)의 화려한 부활과 HBF 주도권:SK하이닉스 (솔리다임)
그동안 HBM에 밀려 적자를 면치 못했던 낸드플래시 사업부가 HBF 시장의 개화로 강력한 현금 창출원(Cash Cow)으로 변모할 것입니다. 특히 자회사 솔리다임을 통해 기업용 고용량 QLC SSD 시장을 선점한 SK하이닉스는 HBF 표준화 연합의 중심축으로서 장기 우상향 모멘텀을 확보했습니다.
폰 노이만 구조의 붕괴와 지식재산권(IP)의 가치:디자인하우스 및 반도체 IP 기업
PIM 구조로 가기 위해서는 메모리 내부에 연산 회로를 정밀하게 설계해야 합니다. 이는 메모리 제조사 단독으로 불가능하며, 팹리스 및 디자인하우스와의 긴밀한 생태계 협력이 필수적입니다. 국내 시장에서는 메모리 인터페이스 IP 원천 기술을 가진 오픈엣지테크놀로지나 삼성전자 파운드리의 핵심 디자인하우스인 가온칩스 같은 다크호스들이 중장기 텐배거(10배 주식) 후보군이 될 수 있습니다.
5. 결론: “데이터를 옮기는 시대는 끝났다”
“HBM이 AI 확산의 제1막(학습)을 화려하게 지배했다면, 제2막(추론)은 전력을 지배하는 자가 승리합니다.”
과거의 반도체 치킨게임이 ‘누가 더 셀(Cell)을 미세하게 깎아 대량 생산하는가’였다면, 앞으로의 AI 시대는 ‘소프트웨어의 특성을 이해하고 시스템 구조와 패키징으로 전력을 얼마나 아끼는가’의 아키텍처 전쟁입니다.
단기적으로는 엔비디아 공급망 내에서 확실한 숫자를 찍어줄 SOCAMM 및 첨단 후공정 밸류체인으로 포트폴리오의 하방을 단단히 지지하십시오. 그리고 중장기적으로는 낸드 업황의 패러다임을 바꿀 HBF와 궁극의 반도체라 불리는 PIM 관련 핵심 기술주들을 적립식으로 모아가는 전략을 추천합니다. 판이 바뀔 때 과감히 베팅하는 투자자만이 다가올 거대한 자산 증식의 기회를 잡을 수 있습니다.
1. 마이크론(MU) 2026 FY 3분기 실적 종합 분석: 숫자가 증명하는 공급자 우위 시장
2026년 6월 24일(미국 현지시간) 장 마감 직후 발표된 마이크론 테크놀로지(Micron Technology, NASDAQ: MU)의 2026 회계연도 3분기(5월 28일 마감) 실적은 전 세계 반도체 업계와 여의도 증가 전반에 그야말로 거대한 ‘지각변동’을 일으켰습니다. 최근 일각에서 고개를 들던 ‘AI 거품론’이나 ‘메모리 피크아웃(Peak-out) 우려’를 완벽하게 잠재우는 압도적인 어닝 서프라이즈(Earning Surprise)입니다.
이번 수치들은 단순한 일회성 호실적이 아닙니다. 반도체 미세공정의 물리적 한계(Scaling Limit)와 AI가 요구하는 초고대역폭(Bandwidth)의 격돌 속에서 메모리 제조사가 완벽한 가격 결정력(Pricing Power)을 쥐었다는 명백한 증거입니다.
1) 컨센서스를 파괴한 핵심 재무 지표
먼저 시장의 예상을 아득히 뛰어넘은 마이크론의 주요 재무 실적을 명확하게 정리해 보겠습니다.
매출액 (Revenue):414.6억 달러 기록. 이는 직전 분기(238.6억 달러) 대비 약 73.7% 급증한 수치이며, 전년 동기(93.0억 달러)와 비교하면 무려 4배 이상 폭발적으로 성장한 수치입니다. 월가 컨센서스였던 350억 달러를 18% 이상 상회했습니다.
Non-GAAP 순이익 & EPS: 일회성 비용을 제외한 비GAAP 기준 순이익은 288.6억 달러, 희석 EPS는 25.11달러입니다. 시장 전망치인 20달러 안팎을 25% 가까이 초월하는 괴물 같은 숫자가 찍혔습니다.
2) 제조업의 상식을 깨뜨린 매출이익률(Gross Margin)의 비밀
이번 발표에서 눈을 가장 의심케 한 지표는 바로 84.9%에 달하는 Non-GAAP 매출이익률(Gross Margin)입니다.
보통 대규모 장치 산업이자 대규모 감가상각비가 수반되는 메모리 제조업에서 80%가 넘는 마진율이 나온다는 것은 불가능에 가깝다고 여겨졌습니다. 가이던스였던 81% 안팎을 가볍게 뛰어넘은 이 서프라이즈의 배경에는 제품 믹스(Product Mix)의 고도화와 후술할 공정 건너뛰기(EUV Passing)에 따른 감가상각비 절감 효과가 강력하게 작용했습니다.
사업부 명칭
3분기 매출액
매출이익률(Gross Margin)
핵심 성장 동력 및 특징
클라우드 메모리 (Cloud)
137.7억 달러
83%
글로벌 빅테크의 AI 서버향 고용량 D램 공급 폭증
핵심 데이터센터 (Data Center)
115.2억 달러
87%
HBM(고대역폭 메모리) 및 고성능 SSD 수요 견인
모바일 및 클라이언트 (Mobile/Client)
115.2억 달러
87%
온디바이스(On-Device) AI 탑재 기기 확대로 인한 스펙 상향
차량 및 임베디드 (Automotive)
46.3억 달러
79%
자율주행 및 인포테인먼트 시스템 고도화에 따른 주문 증가
전 사업부가 전 분기 대비 거의 두 배 가까운 외형 성장을 이룩했으며, 특히 고부가 가치 제품군이 몰려 있는 데이터센터와 모바일 사업부의 마진율이 87%에 육박했다는 점은 전례를 찾아보기 힘든 현상입니다.
3) 4분기 가이던스: 시장을 얼어붙게 만든 가속도의 서막
더욱 경이로운 점은 다음 분기 전망입니다. 마이크론이 제시한 2026 회계연도 4분기 가이던스는 다음과 같습니다.
[Micron 4Q FY2026 Guidance]
매출액 전망: 500억 달러 (±10억 달러)
매출이익률 전망: 약 86%
GAAP 희석 EPS 전망: 30.73달러 (±1달러)
월가 전문가들은 당초 432억 달러 수준의 매출을 예상하고 있었습니다. 그러나 마이크론은 이를 비웃듯 한 분기 만에 매출을 또다시 50억 달러 이상 올리겠다는 청사진을 던졌습니다. 매출 체급이 수백억 달러 규모인 글로벌 공룡 기업이 분기마다 이 정도 속도로 가속 페달을 밟는 구조는 과거 PC나 모바일 전성기 시절에도 목격하지 못했던 역사상 전무후무한 대호황입니다.
2. 핵심 이슈 분석: Anthropic과의 전략적 계약과 ‘빅 패키지’ 구조
이번 마이크론 실적 발표의 공식 타이틀에는 이례적으로 “전환적인 전략적 고객 계약(Strategic Customer Agreements)”이라는 문구가 전면에 배치되었습니다. 이는 실적 발표 이틀 전인 6월 22일 전격 공개된 글로벌 탑티어 AI 거대언어모델(LLM) 개발사 앤트로픽(Anthropic)과의 계약을 정조준하고 있습니다.
1) 계약의 골자와 엔지니어링적 이면
계약의 핵심은 마이크론이 앤트로픽의 인프라 구축에 필요한 고성능 데이터센터 포트폴리오(HBM, 고용량 DDR5, 최첨단 SSD 등) 전반을 장기 공급(Multi-year Supply)한다는 내용입니다.
동시에 마이크론은 자사의 핵심 반도체 설계, 제조 공정 제어, 공급망 관리 시스템 전반에 앤트로픽의 차세대 인공지능인 ‘클로드(Claude)’를 전면 도입하기로 결정했습니다. 반도체 미세화 공정에서 발생하는 수조 개의 로그 데이터를 AI를 통해 분석하여 수율(Yield) 향상 속도를 극한으로 끌어올리겠다는 정교한 계산입니다.
2) 시리즈 H 펀딩 라운드와 3대 제조사의 동거
주목해야 할 사실은 마이크론이 앤트로픽의 시리즈 H(Series H) 펀딩 라운드에 전략적 투자자로 참여했다는 점입니다. 흥미롭게도 이 라운드에는 마이크론뿐만 아니라 대한민국의 삼성전자, SK하이닉스, 그리고 빅테크 얼라이언스의 중심인 아마존(Amazon) 등이 대거 동참했습니다.
이로써 글로벌 HBM 시장을 100% 점유하고 있는 3대 메모리 거인(삼성, SK하이닉스, 마이크론) 모두가 단일 AI 기업의 지분을 나누어 가지며 동시에 ‘공급사’로 들어가는 기이하고도 강력한 구조적 동맹 체제가 구축되었습니다.
CEO 산자이 메로트라(Sanjay Mehrotra)가 언급했듯, 이러한 다개년 장기 계약은 메모리 업계의 고질적인 고통이었던 ‘경기 변동성(Cyclicality)’을 억제하고 재무 성과의 ‘지속성 및 예측 가능성’을 담보하는 강력한 록인(Lock-in) 효과를 발휘하게 됩니다.
3. 핵심 기술 심층 비교: 마이크론 1-베타 공정의 승리와 후공정의 한계
반도체 엔지니어의 시각에서 이번 마이크론의 호실적과 미래 비전을 매끄럽게 이해하기 위해서는, 이들이 선택한 하드웨어 공정의 특수성과 물리적인 한계 상황을 기술적으로 뜯어보아야 합니다.
1) 1-베타(1b) D램 공정의 승리: 노광 기술의 한계를 우회하다
현재 메모리 미세공정은 10나노급 단계에서 1x, 1y, 1z, 1alpha(1a)를 넘어 1beta(1b) 공정까지 도달해 있습니다.
여기서 경쟁사들과 마이크론의 운명을 가른 결정적 분기점이 존재합니다. 삼성전자와 SK하이닉스는 10나노 초반의 미세 회로를 그리기 위해 대당 수천억 원에 달하는 네덜란드 ASML의 EUV(극자외선) 노광 장비를 선제적으로 도입하여 라인을 셋업했습니다.
반면, 마이크론은 초기 투자 비용 부담과 수율 확보 실패 리스크를 회피하기 위해 1b 공정까지 EUV를 전혀 쓰지 않는 ‘EUV 패싱’ 전략을 취했습니다. 대신 기존의 DUV(심자외선) 액침(Immersion) 장비를 활용해 회로를 여러 번 겹쳐 그리는 멀티 패터닝(Multi-Patterning, Quadruple Patterning 등) 기술을 극한의 영역까지 쥐어짜 내 성공시켰습니다.
[엔지니어 노트]
EUV 장비를 도입하면 공정 단계(Step) 수는 줄어들지만, 천문학적인 장비 감가상각비가 매 분기 고정비로 인식됩니다. 마이크론은 DUV 기반 멀티 패터닝으로 공정 난이도는 극상으로 올라갔으나, 장비 도입에 따른 감가상각비를 대폭 절감했습니다. 이번에 양산 및 대량 출하를 시작했다는 마이크론의 HBM4가 바로 이 1-베타 D램을 기반으로 합니다. 이 영리한 우회 전략 덕분에 84.9%라는 비현실적인 마진율이 가능했던 것입니다.
2) HBM4 시장의 조기 개막과 인터페이스 혁신
HBM4는 이전 세대인 HBM3E와 비교했을 때 규격 자체가 완전히 리셋되는 기념비적인 세대입니다. 프로세서(GPU/TPU)와 데이터를 주고받는 통로인 인터페이스 버스 폭(Interface Bus Width)이 기존 1,024비트에서 2,048비트로 정확히 2배 넓어집니다.
마이크론이 1b 기반의 HBM4 제품을 주요 고객 플랫폼에 대량 양산 출하하고 있다는 고백은, 차세대 초고대역폭 메모리 규격 표준화 경쟁에서 마이크론이 결코 뒤처지지 않고 시장 주도권을 완벽히 안착시켰음을 시사합니다.
3) 공급 부족의 본질적 원인: ‘다이 사이즈 페널티(Die Size Penalty)’
산자이 메로트라 CEO는 실적 발표 중 컨퍼런스 콜에서 “중기적으로 고객 수요의 50%에서 3분의 2 정도만 충족할 수 있다”고 엄포를 놓았습니다. 공장이 없어서가 아닙니다. 반도체 웨이퍼 위에 칩을 새길 때 발생하는 ‘물리적 한계’ 때문입니다.
공간적 페널티: HBM은 초고속 데이터 전송을 위해 내부에 거대한 제어 회로와 TSV(관통 전극) 영역을 확보해야 하므로, 동일한 용량의 일반 범용 D램 대비 칩 크기(Die Size)가 최소 2배에서 2.5배 이상 큽니다.
웨이퍼 생산량 감소: 똑같은 300mm 웨이퍼 한 장을 투입하더라도 뽑아낼 수 있는 칩의 총개수(Net Die)가 절반 이하로 수직 낙하합니다.
적층 및 패키징 수율: 그렇게 뽑아낸 D램을 8단(8-Hi), 12단(12-Hi), 나아가 16단(16-Hi)으로 위로 쌓아 올리고 구멍을 뚫는 후공정(Advanced Packaging)을 거치면서 최종 불량률이 누적됩니다.
따라서 전 세계의 메모리 생산 라인을 24시간 풀가동하더라도, 시장에 공급되는 비트 성장률(Bit Growth)은 물리적으로 제한될 수밖에 없는 구조적 병목에 진입해 있습니다.
4. 글로벌 메모리 3사(SK하이닉스 vs 마이크론 vs 삼성전자) 기술 수준 비교
현재 글로벌 메모리 시장은 완벽한 3과점 체제입니다. 이 3사의 기술적 현주소와 핵심 무기를 냉정하고 정교하게 비교·분석해 드리겠습니다.
1) SK하이닉스: 수율과 첨단 패키징(Advanced Packaging)의 독보적 강자
핵심 기술 무기:MR-MUF (Mass Reflow Molded Underfill)
기술 분석: SK하이닉스는 D램 칩을 쌓아 올릴 때 칩 사이에 액체 형태의 보호재를 흘려 넣어 공간을 메우고, 이를 한 번에 구워 굳히는 MR-MUF 기술을 완성했습니다. 이 방식은 경쟁사 대비 열 방출(방열) 특성이 압도적으로 우수하며, 칩 적층 시 가해지는 압력을 분산시켜 불량률을 획기적으로 낮춥니다.
공정 성숙도: D램 미세공정(1b) 영역에서도 EUV 노광 장비를 가장 안정적으로 안착시켜 균일한 회로 선폭을 뽑아냅니다. 엔비디아(NVIDIA)의 AI 가속기 개발 초기 단계부터 협력해 온 덕에 ‘AI 메모리의 표준 가이드’를 쥐고 흔드는 절대적 지위를 유지하고 있습니다.
2) 마이크론: 영리한 공정 스킵과 기민한 추격자
핵심 기술 무기:EUV 패싱 기반의 원가 혁신 & HBM 12단(12-Hi) 적층 기습 선점
기술 분석: 마이크론은 과거 삼성이나 하이닉스 대비 기술 리더십에서 한 세대 뒤처져 있다는 평가를 받았습니다. 그러나 HBM3E와 HBM4로 넘어오는 변곡점에서 중간 단계를 과감히 생략하고 최신 미세공정인 1-베타(1b) 공정에 모든 자원을 올인했습니다. 앞서 언급한 DUV 기반 멀티 패터닝 기술력은 타의 추종을 불허합니다.
잠재적 숙제: 다만, 차세대 1-감마(1g) 공정부터는 선폭이 10나노 미만 급으로 좁혀져 마이크론 역시 결국 EUV 장비를 도입해야만 합니다. 장비 셋업 비용 증가와 초기 수율 제어 숙제를 어떻게 극복할지가 향후 2~3년 내 최대 시험대가 될 것입니다.
3) 삼성전자: 인프라와 총량의 거인, 반격을 준비하는 IDM의 저력
핵심 기술 무기:Advanced NCF (Non-Conductive Film) & 파운드리-메모리 턴키(Turn-key) 능력
기술 분석: 삼성전자는 전통적으로 D램 사이에 비전도성 필름을 레이어별로 배치한 뒤 열과 압력을 가해 접착하는 NCF 방식을 고수해 왔습니다. 이 방식은 적층 단수가 12단, 16단으로 높아지고 칩 두께가 얇아질수록 필름의 두께 제어나 열 방출 측면에서 난이도가 극상으로 치솟습니다. 이 때문에 최신 HBM 검증 테스트 진입 단계에서 경쟁사 대비 다소 늦어지며 고전(苦戰)을 면치 못했습니다.
반전의 열쇠: 하지만 순수 D램 미세공정 설계 역량과 평택·화성 중심의 세계 최대 규모 생산 인프라(Fab)는 타사가 감히 흉내 낼 수 없는 수준입니다. 특히 HBM의 맨 밑바닥에서 GPU와 데이터를 직접 주고받는 제어 칩인 ‘베이스 다이(Base Die)’를 자사의 첨단 파운드리(Foundry) 공정으로 직접 제작하고 패키징까지 일괄 처리할 수 있는 유일한 종합 반도체 기업(IDM)이라는 무시무시한 잠재력을 온전히 보유하고 있습니다.
5. 향후 유사 기업 및 기술 구도 발전 속도 전망 (2026~2028)
향후 메모리 전쟁의 패러다임은 “누가 회로를 더 미세하게 깎아 내는가”의 단편적 싸움에서 “누가 더 정밀하게 쌓고, 로직 시스템과 어떻게 커스텀(Custom) 연결을 이루어 내는가”의 고차원 패키징 싸움으로 완벽하게 전환됩니다. 특히 HBM4 세대부터는 베이스 다이를 메모리 공정이 아닌 TSMC나 삼성전자 파운드리의 5나노/4나노 이하 첨단 로직(Logic) 공정으로 제작하는 것이 표준 규격화되었습니다.
1) 단기 ~ 중기 구도 (2026년 ~ 2027년): SK하이닉스와 마이크론의 견고한 양강 체제
당분간 시장은 SK하이닉스와 마이크론의 굳건한 랠리가 지속될 것입니다.
마이크론은 이번 앤트로픽과의 계약과 역대급 가이던스를 통해 확보한 302억 달러의 막대한 현금 여력을 기반으로 미국 아이다호주 보이시(Boise) 및 뉴욕주 시러큐스(Syracuse) 메가 팹 건설에 속도를 낼 것입니다. 미국 정부의 전폭적인 보조금(CHIPS Act) 지원과 빅테크들의 ‘미국산 메모리(Made in USA)’ 선호 현상이라는 강력한 지정학적 순풍을 타고 고마진 독점 체제를 유지할 가능성이 매우 높습니다.
SK하이닉스 역시 엔비디아-TSMC-SK하이닉스로 이어지는 이른바 ‘AI 초밀착 삼각 동맹’의 결속력을 바탕으로 시장 점유율 1위를 수성할 것입니다. 오랫동안 축적된 MR-MUF 패키징 노하우는 단수가 극대화되는 16단 제품군에서도 안정적인 골든 수율을 확보하는 핵심 무기가 됩니다.
2) 장기 구도 변곡점 (2027년 이후 ~ HBM4E 세대): 삼성전자의 턴키(Turn-key) 역습
진짜 승부는 2027년 이후 전개될 HBM4E(HBM4 Extended) 세대에서 판가름 날 확률이 높습니다.
HBM4E 세대에 이르면 메모리는 더 이상 범용 저장장치가 아니라 주문형 반도체(ASIC)처럼 특정 고객사의 빅 모델에 최적화된 ‘맞춤형(Custom) 반도체’의 성격을 극단적으로 띠게 됩니다. 이때 빅테크 고객사(NVIDIA, AMD, Google, Amazon 등)는 메모리는 마이크론에 발주하고, 베이스 다이는 TSMC에 넘긴 뒤, 최종 후공정을 다시 외주 패키징 업체(OSAT)에 맡기는 복잡한 공급망 관리(SCM)에 심각한 피로감을 느낄 수 있습니다. TSMC의 첨단 패키징(CoWoS) 캐파가 병목에 걸리면 제품 출하 자체가 올스톱되기 때문입니다.
바로 이 지점이 삼성전자의 거대한 거인 아키텍처가 빛을 발하는 타이밍입니다. 삼성전자가 차세대 NCF 필름 기술의 안정화 혹은 하이닉스 방식의 장점을 흡수한 하이브리드 본딩(Hybrid Bonding) 기술을 완벽히 마스터한다면, 다음과 같은 ‘원스톱 솔루션(One-Stop Solution)’으로 판도를 단숨에 뒤집을 수 있습니다.
반면, 자체 파운드리 팹이 없는 마이크론은 베이스 다이 제작의 100%를 TSMC에 전적으로 의존해야 합니다. 향후 지정학적 리스크나 TSMC의 로직 라인 숏티지(Shortage)가 발생할 경우, 마이크론의 질주에 치명적인 제동이 걸릴 리스크가 상존합니다.
6. 국내외 관련 기업 밸류체인(Value Chain) 분석 및 수혜주 정리
마이크론의 역대급 실적과 가이던스는 결국 후방 산업을 지탱하는 소재·부품·장비(소부장) 기업들에 대한 대규모 발주(CapEx) 폭발로 고스란히 연결됩니다. 투자 관점에서 반드시 포트폴리오에 편입해야 할 국내외 핵심 수혜 기업들을 정밀하게 분류해 드립니다.
1) 후공정(Advanced Packaging) 및 첨단 본딩 장비 기업 (★최대 수혜 주축)
D램을 정밀하게 위로 쌓아 올리는 패키징 공정은 HBM 수율의 핵심입니다. 공급 부족을 해결하기 위한 라인 증설의 낙수효과를 가장 직접적으로 흡수하는 포지션입니다.
한미반도체 (042700): SK하이닉스의 MR-MUF 공정에 필수적인 ‘듀얼 TC 본더(Dual TC Bonder)’를 공급하며 독보적인 지위를 다졌습니다. 마이크론 역시 적층 단수가 12단, 16단으로 높아짐에 따라 열 압착 제어 능력이 탁월한 하이엔드 본더 장비 도입이 시급하므로, 글로벌 탑티어 장비사로서 수주 모멘텀이 극대화될 것입니다.
HPSP (403870): 전 세계에서 유일하게 ‘고압 수소 어닐링 장비’를 독점 공급하는 기업입니다. D램 회로 미세화 및 HBM 적층 과정에서 실리콘 표면에 발생하는 미세 결함(Interface Trap)을 줄여 전체 칩의 신뢰성과 수율을 극대화하는 데 필수적입니다. 삼성, SK하이닉스, 마이크론 3사 모두 공급망 확대를 서두르고 있어 구조적 장기 성장이 담보되어 있습니다.
피에스케이홀딩스 (031980) / 디아이티 (110990): 후공정 수율 개선의 필수 관문인 ‘리플로우(Reflow)’ 장비 및 세정, 레이저 베이킹 장비를 보유한 강소 기업들로 HBM 캐파 증설에 따른 직접적인 수혜를 받습니다.
2) 전공정 미세화 및 EUV(극자외선) 생태계 핵심 기업
엔지니어 관점에서 짚어드렸듯 마이크론은 향후 1-감마(1g) 공정부터 EUV 노광 장비를 강제로 도입해야 하며, 삼성과 하이닉스는 이미 선단 공정 전반에 EUV 적용 비중을 크게 늘리고 있습니다.
ASML (ASML, 네덜란드): 반도체 초미세공정의 절대적 지배자이자 노광 장비(EUV) 독점 기업입니다. 마이크론이 이번 분기에 벌어들여 쌓아 올린 302억 달러의 거대한 현금 주머니 중 상당 부분이 향후 ASML의 EUV 장비 구매 대금으로 고스란히 흘러 들어갈 수밖에 없는 구조적 생태계가 짜여 있습니다.
에스앤에스텍 (034730) / 동진쎄미켐 (005290): EUV 공정 도입 확대 시 소모량이 급증하는 핵심 소재인 EUV 펠리클(Pellicle) 및 프리미엄 포토레지스트(PR) 분야의 기술 선두 주자들입니다. 전공정 투자 재개 시 실적 턴어라운드 탄력이 가장 가파를 자산들입니다.
3) 검사 및 계측(Inspection & Test) 장비 기업
HBM은 여러 개의 D램 칩을 수직으로 융합하는 구조이기 때문에, 상단에 쌓인 8단 혹은 12단의 칩 중 단 하나의 D램 회로에만 불량이 발생해도 패키지 전체를 폐기해야 하는 끔찍한 비용 손실이 발생합니다. 이에 따라 전수 검사(Wafer Test) 및 중간 단계 검사의 중요성이 과거 범용 D램 시절과는 비교할 수 없을 정도로 커졌습니다.
와이씨 (232140, 구 와이아이케이): 고속 메모리 웨이퍼 테스터 장비의 핵심 공급사로, 특히 삼성전자의 HBM 라인향 검사 장비 공급 모멘텀이 매우 강력하게 형성되어 있습니다. 삼성의 가시적인 HBM 캐파 확대 움직임이 포착될 때 주가가 가장 민감하게 선반영되는 특성을 지닙니다.
테크윙 (089030): HBM용 고속 핸들러(검사 대상 칩을 이송하고 온도를 제어하는 장비) 및 큐브 테스터 시장에서 글로벌 기술 격차를 벌려 나가고 있는 후공정 테스트 고도화의 핵심 수혜주입니다.
7. 투자 가이던스
지금의 시장 상황을 관통하는 한 문장은 이렇습니다. “과거의 시클리컬(Cyclical) 공포에 갇혀, 구조적 성장주(Structural Growth)로 탈바꿈하는 메모리의 체질 개선을 몰라보지 마라.”
과거의 반도체 사이클은 항상 제조사들의 눈먼 무모한 증설 경쟁(CapEx War)과 이로 인한 ‘공급 과잉’으로 한순간에 폭락하곤 했습니다. 그러나 지금의 AI 메모리 사이클은 공장을 짓지 않아서가 아니라, 앞서 구체적으로 짚어드린 ‘다이 사이즈 페널티’와 ‘TSV 공정 난이도’라는 물리적인 대자연의 법칙이 공급을 강제로 억제하고 있는 기이한 호황입니다. 수요는 폭발하는데 공급이 공급을 따라가지 못하는 강력한 낙관론의 근거입니다.
성공적인 자산 배분을 위해 다음과 같은 ‘포트폴리오 바벨 전략(Barbel Strategy)’을 제안합니다.
포트폴리오의 중심(Core)은 이기는 말에: 이미 확고한 엔비디아 공급망과 우수한 패키징 수율로 눈에 보이는 이익을 묵직하게 뽑아내고 있는 SK하이닉스와 미국 공급망 프리미엄을 온전히 독식하며 현금을 쓸어 담는 마이크론(MU)을 중심축에 두어 단기 상승 랠리의 과실을 편안하게 누리십시오.
역발상(Contrarian) 투자 기회로서의 알파 매수: 시장의 냉정한 외면 속에서 밸류에이션 리스크가 가장 적고, 차세대 HBM4 턴키 솔루션이라는 가장 강력한 반격의 카드를 숨겨두고 있는 삼성전자를 공포의 구간마다 분할 매수하여 중장기 변곡점을 느긋하게 기다리는 전략은 영리한 투자자의 전형입니다.
고래 싸움에 웃는 독점 소부장 선점: 완제품 3사의 HBM 주도권 경쟁이 치열해지면 치열해질수록, 이들 3사 모두에게 장비를 납품할 수밖에 없는 독점적 공급망 기업들(한미반도체, HPSP, ASML)은 리스크 없이 전방 산업 성장의 과실을 고스란히 나누어 가지게 됩니다. 변동성이 두려운 투자자에게는 가장 확실한 피난처입니다.
지금의 반도체 시장은 단순한 주식 매매의 영역을 넘어섰습니다. 인류의 인공지능 연산 능력을 무한대로 확장하는 ‘디지털 인프라 혁명’의 대서사시입니다. 단기적인 주가 호가창의 흔들림에 감정적으로 대응하지 마시고, 업황의 거대한 도도한 상방 흐름을 우직하게 믿고 포트폴리오를 유지하는 ‘엉덩이 무거운 투자자’가 결국 최후의 승리자가 될 것입니다.
[필독 및 면책 고지]
본 포스팅에 기술된 분석 내용은 시장의 객관적인 사실과 기술적 분석을 기반으로 작성된 개인적인 소견일 뿐입니다. 필자는 전문 투자 자문가가 아니며, 본 자료는 어떠한 경우에도 투자 결과에 대한 법적 책임 소지의 증빙 자료로 사용될 수 없습니다. 실제 투자 결정 시에는 반드시 추가적인 전문 자료를 폭넓게 검토하시고 본인의 책임하에 최종 판단을 내리시기 바랍니다.
2025년 3월 GTC 컨퍼런스에서 엔비디아(NVIDIA)가 공개한 실리콘 포토닉스 기반 네트워킹 스위치 플랫폼, ‘Spectrum-X Photonics’는 단순한 신제품 발표가 아닙니다. 이는 AI 데이터센터의 물리적 한계를 깨부수고, 수백만 개의 GPU를 하나의 초거대 컴퓨터처럼 묶겠다는 엔비디아의 야심찬 선전포고이자 전 세계 반도체 공급망을 재편하겠다는 거대한 마스터플랜입니다.
오늘 포스팅에서는 NVIDIA Spectrum-X Photonics의 핵심 기술부터 시작해 글로벌 빅테크들의 대항마 분석, 그리고 삼성전자와 SK하이닉스 등 국내 반도체 거인들의 미래 전망과 투자 전략까지 거품을 걷어내고 완벽하게 쪼개어 분석해 드리겠습니다.
1. NVIDIA Spectrum-X Photonics란 무엇인가?
🔷 개념 정의 및 탄생의 목적
NVIDIA Spectrum-X Photonics는 실리콘 포토닉스(Silicon Photonics, 규소 기반 광반도체) 기술을 엔드투엔드(End-to-End) 네트워킹 스위치 아키텍처에 직접 통합한 차세대 AI 인프라 플랫폼입니다.
쉽게 말해, 기존의 데이터센터가 칩과 칩, 서버와 서버 사이에서 데이터를 주고받을 때 ‘전기 신호’를 사용했다면, 이 플랫폼은 이를 ‘빛(광신호)’으로 변환하여 초고속·저전력으로 전송하는 기술입니다. 엔비디아가 이 플랫폼을 개발한 궁극적인 목적은 단 하나입니다. 바로 수백만 개의 GPU가 동시에 협업하는 ‘초대규모 AI 팩토리(AI Factory)’의 고질적인 네트워킹 병목 현상을 해결하고, 기하급수적으로 늘어나는 에너지 소비량과 운영 비용(OPEX)을 혁신적으로 절감하는 것입니다.
🔷 등장 배경: “네트워킹 인프라를 재발명하라”
엔비디아의 수장 젠슨 황(Jensen Huang) CEO는 Spectrum-X Photonics를 공개하며 다음과 같은 기념비적인 말을 남겼습니다.
“AI 팩토리는 과거의 일반적인 데이터센터와는 완전히 다른, 극도의 규모를 가진 새로운 클래스의 컴퓨팅 자산입니다. 따라서 네트워킹 인프라도 이에 맞춰 기초부터 완전히 재발명(Reinvented)되어야 합니다. 실리콘 포토닉스를 스위치에 직접 통합함으로써 하이퍼스케일 및 엔터프라이즈 네트워크의 기존 물리적 한계를 뛰어넘어, 백만 GPU 규모의 초대형 AI 팩토리로 가는 문을 마침내 열고 있습니다.”
이 발언의 이면에는 현재 데이터센터 인프라가 마주한 가혹한 현실이 숨어 있습니다. 거대언어모델(LLM)의 매개변수(Parameter)가 수조 개 단위로 커지면서, AI 연산은 단일 GPU나 단일 서버 랙 안에서 끝낼 수 없는 구조가 되었습니다. 수만, 수십만 대의 GPU가 서로 연산 결과(Gradient)를 실시간으로 주고받으며 싱크를 맞춰야 합니다.
이때 GPU의 연산 속도가 아무리 빨라도, 이들을 연결하는 ‘고속도로(네트워크)’가 막히면 전체 시스템의 효율은 바닥을 치게 됩니다. 즉, 현재 AI 성능의 병목은 연산 칩 자체가 아니라 ‘칩과 칩 사이의 통신(Interconnect Broadband)’에 있으며, 엔비디아는 이 문제를 정면 돌파하기 위해 빛의 힘을 빌리기로 결정한 것입니다.
2. 물리적 한계에 부딪힌 데이터센터: Power Wall과 Signal Integrity
30년 차 엔지니어 입장에서 볼 때, 기존의 구리선(Copper) 구조와 구형 플러그형 광트랜시버(Pluggable Transceiver) 방식은 이미 임계점에 도달했습니다. AI 팩토리 규모가 10만 대(100K)에서 백만 대(1M) GPU 규모로 확장되면서 데이터센터 설계자들은 두 가지 거대한 물리적 장벽에 가로막혔습니다.
① 전력의 장벽 (Power Wall)
기존 데이터센터는 랙 내부의 짧은 거리는 구리선(DAC 케이블)으로 연결하고, 거리가 조금 멀어지면 서버 외부에 광모듈을 꽂는 플러그형 트랜시버를 사용했습니다. 하지만 포트당 데이터 전송 속도가 1.6 Tb/s(테라비트 매 초) 수준으로 올라가면서 심각한 문제가 발생합니다.
구리선은 물리적인 내부 저항을 가지고 있습니다. 신호의 주파수가 높아질수록 저항에 의한 에너지 손실이 기하급수적으로 커집니다. 이 손실을 메우기 위해 신호를 강제로 증폭하는 리타이머(Retimer)나 이퀄라이저(Equalizer) 칩을 촘촘히 박아야 하는데, 여기서 소모되는 전력이 상상을 초월합니다.
데이터를 연산하는 데 써야 할 귀한 전기가 단순히 데이터를 ‘옆 동네로 보내는 행위’ 자체에 전부 낭비되는 것이죠. 배보다 배꼽이 더 커지는 ‘파워 월(Power Wall)’ 현상입니다.
② 신호 무결성의 붕괴 (Signal Integrity)
초고주파 전전기 신호는 거리가 수 센티미터(cm)만 멀어져도 선로 주변으로 신호가 새어나가거나 감쇄되는 현상이 일어납니다. 인접한 선로끼리 신호가 간섭을 일으키는 크로스토크(Crosstalk, 신호 간섭)와 노이즈가 극심해집니다.
이로 인해 데이터에 에러가 발생하면 시스템은 데이터를 처음부터 다시 전송(Retransmission)해야 하므로, 네트워크 레이턴시(Latency, 지연 시간)가 들쭉날쭉해지고 AI 학습 효율이 치명적으로 저하됩니다.
전기 신호의 물리적 특성상 속도를 높이면서 거리를 늘리는 것은 불가능한 영역에 도달했으며, 이를 타개할 유일한 탈출구가 바로 ‘저항이 없고, 간섭이 없으며, 빛의 속도로 달리는’ 광통신을 칩 레벨로 끌어들이는 것이었습니다.
3. 핵심 아키텍처 분석: Co-Packaged Optics (CPO)와 TSMC COUPE
NVIDIA Spectrum-X Photonics가 기존 네트워킹 장비와 차별화되는 핵심 혁신은 ‘광학 소자(Optics)를 스위치 ASIC(주문형 반도체)과 동일한 패키지 내부에 배치하는 아키텍처’, 즉 CPO(Co-Packaged Optics, 공동 패키징 광학) 기술입니다.
🔷 CPO (Co-Packaged Optics) 구조의 혁신
기존의 플러그형(Pluggable) 방식은 스위치 메인 칩에서 출력된 전기 신호가 기판(PCB)을 타고 길게 흘러가 장비 전면부의 포트에 꽂힌 광트랜시버 모듈에 도달한 뒤에야 빛으로 바뀌었습니다. 기판을 지나가는 그 긴 경로 동안 엄청난 전력 손실과 신호 왜곡이 발생했습니다.
반면 엔비디아가 채택한 CPO 방식은 스위치 ASIC 칩 바로 옆, 눈앞에 아주 가까운 거리에 실리콘 포토닉스 기반의 광 엔진(Optical Engine)을 바짝 붙여 하나의 칩처럼 패키징합니다.
이렇게 하면 전기가 이동하는 거리가 수십 센티미터(cm)에서 수 밀리미터(mm) 혹은 마이크로미터(㎛) 단위로 획기적으로 줄어듭니다. 전기가 아주 잠깐만 이동하고 곧바로 빛으로 전환되므로 기판에서의 신호 손실이 원천 차단됩니다. 그 결과, 기존 인프라 대비 네트워크 전력 효율은 5배 이상 향상되고, 높은 네트워크 복원력을 확보하며, AI 애플리케이션의 지속 실행 시간(Uptime) 역시 5배 이상 길어집니다.
🔷 패키징의 치트키: TSMC COUPE 플랫폼
이러한 초정밀 CPO 구조를 가능하게 만든 숨은 공신이자 핵심 기반 기술이 바로 파운드리 절대강자 TSMC의 실리콘 포토닉스 제조 플랫폼인 ‘COUPE(Compact Universal Photonic Engine)’입니다.
TSMC COUPE는 65nm(나노미터) 공정으로 제조된 전자 집적 회로(EIC, Electronic Integrated Circuit)와 빛을 제어하고 라우팅하는 광자 집적 회로(PIC, Photonic Integrated Circuit)를 TSMC의 최첨단 3D 패키징 기술인 SoIC-X(System on Integrated Chips) 기술로 결합합니다.
3D 하이브리드 본딩 (Hybrid Bonding): 과거에는 EIC와 PIC 칩을 미세한 솔더 범프(Solder Bump)를 이용해 연결했습니다. 범프의 크기 때문에 데이터 통로의 밀도를 높이는 데 한계가 있었죠. 하지만 TSMC COUPE는 범프 없이 구리(Cu)와 구리를 분자 결합 수준으로 직접 수직 접합해 버리는 ‘하이브리드 본딩’을 적용했습니다. 이 덕분에 접합면의 저항이 거의 제로(0)에 수렴하며, 데이터 전송 레이턴시가 절반으로 줄어들고 전력 효율성은 2.5배 이상 개선됩니다.
🔷 핵심 광학 소자: 마이크로 링 변조기 (Micro Ring Modulators)
실리콘 포토닉스의 고질적인 난제는 “어떻게 그 좁은 반도체 칩 다이(Die) 안에 수많은 빛의 채널을 밀어 넣을 것인가”였습니다. 엔비디아는 이 문제를 해결하기 위해 기존 데이터센터에서 범용적으로 쓰이던 대형 ‘마하젠더 변조기(MZM, Mach-Zehnder Modulator)’를 과감히 버리고, 차세대 ‘마이크로 링 변조기(Micro Ring Modulator)’ 기술을 도입했습니다.
마이크로 링 변조기는 지름이 수 마이크로미터에 불과한 미세한 원형 실리콘 도파로(Waveguide)를 활용합니다. 특정 파장의 빛만을 선택적으로 공진시켜 초고속으로 온/오프(On/Off) 신호를 만들어내는 소자입니다. 기존 MZM 대비 크기가 수십 분의 일에 불과하기 때문에, 제한된 스위치 패키지 내부 공간에 엄청난 수의 광학 채널(Wavelength Division Multiplexing, 파장 분할 다중화)을 집적할 수 있게 되었습니다. Spectrum-X Photonics가 초고대역폭을 구현할 수 있었던 일등 공신이 바로 이 마이크로 링 기술입니다.
4. Spectrum-X Photonics의 파괴적인 성능 지표 분석
엔비디아가 제시한 사양표를 보면, 하드웨어 엔지니어로서 소름이 돋을 정도의 압도적인 수치들이 나열되어 있습니다. 기존의 이더넷 및 광통신 규격을 아득히 초월하는 주요 성능 지표들을 정밀하게 해부해 보겠습니다.
📊 주요 성능 지표 요약 및 해석
항목
수치 및 성능 향상 폭
기술적 가치와 엔지니어링 의미
포트당 대역폭
1.6 Tb/s (Terabit per Second)
기존 400Gb/s 및 800Gb/s 세대를 단숨에 뛰어넘는 속도로, 단일 포트가 초당 테라바이트급 데이터를 뿜어냅니다.
전력 효율
기존 대비 3.5배 향상
동일한 데이터를 전송할 때 소모되는 전력이 3분의 1 이하로 줄어들어, 데이터센터의 최대 적인 발열과 전력 공급 문제를 해결합니다.
신호 무결성
기존 대비 63배 향상
전기 신호의 감쇄와 노이즈(크로스토크)를 빛으로 대체함으로써 비트 에러 레이트(BER)를 기하급수적으로 낮췄습니다.
네트워크 복원력
기존 대비 10배 향상
선로 장애나 패킷 손실 발생 시 하드웨어 레벨에서 즉각적으로 경로를 재배정(Rerouting)하여 시스템 다운타임을 차단합니다.
배포 속도
기존 대비 1.3배 빠름
CPO 공정 최적화 및 간소화된 광 커넥터 구조를 통해 데이터센터 인프라 구축 및 셋업 시간을 대폭 단축합니다.
필요 레이저 수
기존 대비 4분의 1 수준
하나의 광원에서 여러 파장의 빛을 동시에 쪼개어 쓰는 고도화된 다중 파장 기술을 도입하여 단가와 고장 확률을 낮췄습니다.
이 표에서 가장 눈여겨보아야 할 수치는 단연 ‘신호 무결성 63배 향상’과 ‘전력 효율 3.5배 향상’입니다. 이 두 수치는 단순히 실험실 안의 가상 수치가 아닙니다. 수십만 대의 GPU가 거대한 행렬 연산을 수행할 때, 단 하나의 패킷 에러로 인해 전체 연산이 멈추고 이전 체크포인트로 돌아가야 했던 현상(Tail Latency 및 Sync Bottleneck)을 근본적으로 제거할 수 있음을 뜻합니다. 인프라 운영자 관점에서는 수백억 원의 전기세를 아끼는 동시에 AI 학습 완료 시간을 수주일 앞당길 수 있는 치명적인 상업적 무기입니다.
🔷 상용 제품 구성 및 라인업
Spectrum-X Photonics 스위치는 초대형 하이퍼스케일러부터 중형 엔터프라이즈까지 커버할 수 있도록 유연한 총 대역폭 구성을 지원합니다.
100Tb/s(테라비트) 총 대역폭 구성: * 128포트 X 800Gb/s 아키텍처
512포트 X 200Gb/s 아키텍처
400Tb/s(테라비트) 총 대역폭 구성:
512포트 X 800Gb/s 아키텍처
2,048포트 X 200Gb/s 아키텍처
단일 스위치 장비 하나가 무려 400Tb/s의 데이터를 처리한다는 것은, 전 세계 모든 인류가 동시에 동영상을 스트리밍해도 감당할 수 있는 수준의 고속도로가 칩 패키지 안에서 구현된다는 것을 의미합니다.
5. 글로벌 동맹군: 파트너 생태계(Ecosystem) 분석
엔비디아가 아무리 뛰어난 반도체 설계 역량을 가졌다고 해도, 빛(Optical)의 영역은 전통적인 실리콘 반도체 공정과 메커니즘이 완전히 다릅니다. 빛을 생성하는 레이저 다이오드(Laser Diode) 제조 기술, 광섬유를 정밀하게 정렬하는 패키징 기술 등은 독점할 수 없는 영역입니다.
그렇기 때문에 엔비디아는 전 세계 반도체, 광학, 부품 탑티어 기업들을 끌어모아 강력한 ‘Spectrum-X 파트너 생태계’를 구축했습니다. 주식 투자자라면 이 생태계에 포진한 기업들의 면면을 반드시 주목해야 합니다.
Lumentum (루멘텀): 광통신용 인듐인화물(InP) 및 갈륨비소(GaAs) 기반 화합물 반도체 레이저 분야의 글로벌 리더입니다. Spectrum-X 플랫폼의 심장이라 할 수 있는 ‘외부 광원(ELS, External Laser Source)’ 모듈을 독점 공급하며 기술 협력을 진행 중입니다. CPO 구조에서는 열에 취약한 레이저를 칩 내부가 아닌 외부에 배치하므로, 고출력·고안정성 외장 레이저를 공급할 수 있는 루멘텀의 위상은 독보적입니다.
Coherent (코히어런트): 실리콘 포토닉스 및 첨단 광학 소재의 최강자입니다. 엔비디아와 함께 차세대 광학 트랜시버 아키텍처 및 PIC 설계 자조를 공동 개발하며 생태계의 한 축을 담당하고 있습니다.
TSMC: 말할 필요도 없는 글로벌 파운드리 1위 기업입니다. 앞서 언급한 COUPE 3D 패키징 플랫폼과 SoIC-X 공정을 전량 책임지며, 엔비디아가 설계한 Spectrum-X 스위치 칩을 실물 반도체로 찍어내는 유일한 생산 기지입니다.
Corning (코닝): 특수 유리 및 광섬유 분야의 제왕입니다. CPO 패키지 내부와 외부 네트워크 케이블을 손실 없이 연결해 주는 초고집적 광섬유 어레이(Fiber Array) 및 초정밀 커넥팅 기술을 제공합니다.
Foxconn (폭스콘): 세계 최대의 전자제품 제조 전문 기업(EMS)으로, 엔비디아의 스위치 보드 및 시스템 전체를 조립하고 양산 인프라를 구축하는 역할을 맡았습니다.
SENKO (센코 Advanced Components): 광 커넥터 분야의 숨은 강자로, CPO 모듈에 특화된 초소형·저손실 광학 인터페이스 및 미세 커넥터를 공급하여 신호 손실을 최소화하는 데 기여하고 있습니다.
이처럼 엔비디아는 [설계(NVIDIA)->제조/패키징(TSMC) -> 광원(Lumentum/Coherent) -> 연결재(Corning/SENKO) -> 최종 조립(Foxconn)]으로 이어지는 강력한 광반도체 수직 계열화 및 공급망을 완성했습니다. 이는 후발 주자들이 쉽게 침범할 수 없는 거대한 진입 장벽(Economic Moat) 역할을 합니다.
6. 스케일 확장 기능의 핵심: Spectrum-X Multiplane
네트워크 스위치 성능이 아무리 좋아도 수십만 대의 GPU를 하나로 묶으려면 독창적인 토폴로지(Topology, 연결 구조)와 프로토콜이 필요합니다. 엔비디아는 이를 위해 ‘Spectrum-X Multiplane’ 기능을 도입했습니다.
🔷 단일 플레인의 한계를 극복하는 멀티플레인 아키텍처
전통적인 데이터센터 네트워크는 하나의 선로(Single Plane)로 모든 데이터를 주고받았습니다. 하지만 GPU 규모가 10만 단위를 넘어가면 단일 네트워크 라우팅 경로는 포화 상태에 이르고, 특정 구간이 막히는 ‘핫스팟(Hotspot)’ 현상이 발생합니다.
Spectrum-X Multiplane은 각 GPU에 장착된 초고속 네트워크 카드인 ‘SuperNIC’을 2개 이상의 완전히 독립된 네트워크 플레인(Network Plane)에 분산시켜 병렬로 연결하는 기술입니다.
예를 들어, 도로망으로 치면 경부고속도로 하나만 쓰던 방식에서 상행선 전용, 하행선 전용, 우회 고속도로를 동시에 개통하여 차들을 분산시키는 것과 같습니다. 이 멀티플레인 아키텍처 덕분에 단일 플레인이 가졌던 대역폭과 확장성의 한계를 가볍게 뛰어넘을 수 있습니다.
🔷 2계층(2-Tier) 구조에서 12만 8천 개 GPU 확장
놀라운 점은 복잡한 3계층(3-Tier) 구조를 거치지 않고, 단 2계층(2-Tier) 네트워크 구조만으로 최대 12만 8천 개(128K)의 GPU를 하나의 클러스터로 확장 가능하다는 사실입니다. 이는 기존 단일 플레인 이더넷 네트워크 대비 무려 64배나 더 큰 규모입니다.
네트워크 계층(Tier)이 줄어든다는 것은 데이터가 목적지까지 가기 위해 거쳐야 하는 스위치 장비의 단계가 줄어든다는 뜻입니다. 이는 곧 ‘레이턴시의 극적인 감소’와 ‘장비 구입 비용 및 전력 소모 감소’로 직결됩니다. Spectrum-X Multiplane은 하이퍼스케일러들이 최소한의 인프라 비용으로 가장 효율적인 백만 GPU 규모의 AI 팩토리를 구축할 수 있도록 만들어주는 핵심 소프트웨어 및 하드웨어 연동 기술입니다.
7. 시장의 또 다른 축: 글로벌 빅테크의 CPO 대항마 솔루션 분석
“엔비디아와 TSMC가 저렇게 판을 짜면, 브로드컴이나 인텔, 시스코 같은 기존 네트워크의 제왕들은 손 놓고 구경만 하고 있을까?” 절대 아닙니다. 이들은 오히려 어떤 면에서는 엔비디아보다 실리콘 포토닉스 분야에서 훨씬 깊은 내공과 칩 설계 역량을 가지고 있습니다. 엔비디아의 독점 체제를 막으려는 ‘반(反)엔비디아 연합군’의 무기들을 시원하게 분석해 드리겠습니다.
① 브로드컴 (Broadcom) – “네트워크 스위치 시장의 진짜 주인”
엔비디아가 AI GPU로 세상을 지배하기 전, 전 세계 데이터센터 네트워크 스위치 칩(ASIC) 시장의 80% 이상을 틀어쥐고 있던 절대강자는 브로드컴입니다. 브로드컴은 엔비디아의 공습에 맞서 ‘Tomahawk 5-CPO’ 및 차세대 ‘Bailley’ 플랫폼을 내놓았습니다.
기술적 차별점 (2.5D SiP 방식): 엔비디아의 Spectrum-X가 TSMC의 COUPE라는 아주 최신의, 그러나 아직은 양산성이 완전히 검증되지 않은 3D 하이브리드 본딩 공정에 전적으로 의존한다면, 브로드컴은 조금 더 안정적이고 시장 검증이 끝난 2.5D SiP(System-in-Package) 방식을 씁니다. 중앙의 대형 스위치 ASIC 주변에 실리콘 포토닉스 광 엔진을 독립된 다이(Die) 형태로 배치하고, 유기 기판(Substrate) 위에서 고밀도 배선으로 연결하는 방식입니다.
엔지니어의 한줄평: 기반 네트워킹 기술력, 패킷 라우팅 알고리즘, 그리고 기존 데이터센터 인프라와의 호환성 면에서는 솔직히 엔비디아보다 브로드컴의 역량이 한 수 위입니다. 브로드컴은 이미 구글, 메타 같은 메이저 빅테크에 CPO 스위치를 공급한 실전 경험(Track Record)이 풍부합니다.
② 인텔 (Intel) – “15년 동안 빛만 연구한 실리콘 포토닉스의 원조 맛집”
최근 인텔이 파운드리나 CPU 부문에서 고전하고 있다는 뉴스가 많지만, ‘실리콘 포토닉스’라는 단일 기술 분야만큼은 인텔이 전 세계에서 가장 오랜 기간 공을 들였고, 가장 강력한 IP(지식재산권)를 보유한 숨은 고수입니다. 인텔의 무기는 ‘OCI (Optical Compute Interconnect) 칩렛(Chiplet)’입니다.
기술적 차별점 (인패키지 레이저 통합 기술): 엔비디아나 브로드컴의 가장 큰 약점은 빛을 만들어내는 레이저 광원 소자를 칩 내부에 넣지 못해 외부 외주사(Lumentum 등)에서 공급받아 케이블로 연결해야 한다는 점입니다. 하지만 인텔은 레이저 광원 자체를 실리콘 웨이퍼 위에 직접 성장시키고 통합(In-package Integrated Laser)하는 독보적인 원천 기술을 가지고 있습니다. 자사 파운드리 공정에서 전자 회로, 광자 회로, 그리고 레이저 소자까지 원칩(One-chip) 형태로 한 번에 찍어낼 수 있는 유일한 내재화 수준을 갖춘 기업이 바로 인텔입니다.
③ 시스코(Cisco) & AMD 연합 – “개방형 표준(Open Ecosystem)으로 대동단결”
엔비디아의 Spectrum-X는 성능은 뛰어나지만, 기본적으로 자신들의 NVLink 인프라와 SuperNIC, 그리고 CUDA 소프트웨어 생태계에 종속되는 ‘폐쇄형(Proprietary) 무기’입니다. 데이터센터 운영사들(마이크로소프트, 메타 등)은 특정 기업에 자사 인프라 전체가 종속(Lock-in)되는 것을 극도로 싫어합니다.
이에 반발해 시스코, AMD, 메타, 구글 등은 UALink(Ultra Accelerator Link)와 UEC(Ultra Ethernet Consortium)라는 거대 연합체를 결성했습니다.
기술적 차별점 (개방형 CPO 스위치 및 UEC 표준): 시스코는 자사의 고성능 ‘Silicon One’ 스위치 칩셋을 기반으로 CPO 기술을 결합하고 있습니다. 이들의 전략은 엔비디아처럼 폐쇄적인 요새를 짓는 것이 아니라, “전 세계 누구나 가져다 쓸 수 있는 표준 규격의 빛의 고속도로를 개방형 이더넷 표준 위에 구축하겠다”는 것입니다. 가격 경쟁력과 범용성을 무기로 엔비디아의 영토를 잠식해 들어오고 있습니다.
📊 글로벌 CPO/광반도체 핵심 기업 기술 비교
구분
NVIDIA (Spectrum-X)
Broadcom (Bailley)
Intel (OCI)
Cisco-AMD 연합 (UEC)
핵심 아키텍처
TSMC COUPE (3D 하이브리드 본딩)
2.5D SiP (칩렛 기판 배치)
인패키지 융합 (On-Chip 레이저)
개방형 CPO / 범용 이더넷 적용
최대 강점
GPU(B200/X100) 생태계와의 완벽한 소프트웨어 직결
스위치 시장 압도적 점유율, 양산 안정성 최고
레이저 광원 자체 생산 능력, 15년 축적된 IP
특정 기업 종속 없음, 뛰어난 가성비와 호환성
약점 및 한계
TSMC 파운드리 캐파(CapEx)에 100% 종속됨
자체 GPU 생태계가 없어 고객사(빅테크) 선택에 의존
파운드리 공정 리더십 약화로 인한 상용화 지연
연합체 특성상 빠른 의사결정 및 기술 통합 속도 저하
레이저 광원
외주 공급 (Lumentum, Coherent)
외주 공급 (Lumentum 등)
자체 실리콘 통합 생산
외주 및 표준 광원 모듈 채택
8. 기술적 분수령: ‘소모품’에서 ‘칩 내부’로 이동하는 빛의 여정
30년 전 제가 처음 광통신을 접했을 때는, 광케이블이란 데이터센터 건물과 건물 사이, 혹은 도시와 도시 사이의 거대한 전송망(Long-haul)에만 쓰이는 머나먼 기술이었습니다. 그러던 것이 어느새 서버 랙과 랙 사이를 연결하는 데이터센터 내부망(Short-reach)으로 들어오더니, 이제는 스위치 칩 바로 옆(CPO)까지 진격해 왔습니다.
그렇다면 이 ‘빛의 여정’의 다음 최종 종착지는 어디일까요? 엔지니어로서 단언컨대, 그것은 바로 “칩 내부(On-Chip) 및 HBM 메모리 인터커넥션”입니다. 이 발전 단계를 이해해야 향후 10년의 반도체 투자에서 승리할 수 있습니다.
현재 엔비디아의 Spectrum-X나 브로드컴의 Bailley가 보여주는 CPO 기술은 2단계에 와 있습니다. 스위치 장비의 전력과 신호 손실을 막기 위해 칩 바로 옆에 빛의 엔진을 붙인 형태죠.
여기서 한 단계 더 진화하면 3단계: Optical Chiplet 시대로 진입합니다. GPU 연산 코어와 HBM(고대역폭 메모리) 사이를 연결하는 미세 구리선(TSV)마저도 모조리 빛(광배선)으로 바꿔버리는 단계입니다. HBM의 대역폭이 극도로 높아지면, 칩 내부의 미세 구리선마저도 발열과 저항 때문에 타버리거나 신호가 뭉개지기 때문입니다. 바로 이 3단계 영역이 대한민국의 삼성전자와 SK하이닉스가 사활을 걸고 준비 중인 진짜 승부처입니다.
9. 대한민국 반도체의 운명: 삼성전자와 SK하이닉스의 기술 수준 및 대응 현황
NVIDIA와 TSMC가 견고한 ‘대만-미국 동맹’을 맺고 실리콘 포토닉스 생태계를 선점해 나가자, 글로벌 메모리 절대강자인 삼성전자와 SK하이닉스 역시 사활을 걸고 이 시장에 뛰어들고 있습니다.
광반도체 기술은 이제 단순히 네트워킹 스위치 장비에만 머무는 것이 아니라, 차세대 메모리(HBM4, HBM5 및 CXL)의 대역폭 확장과 생존에 필수 불가결한 핵심 요소이기 때문입니다. 두 기업의 냉정한 기술 수준과 주가 모멘텀을 분석해 보겠습니다.
① 삼성전자 (Samsung Electronics) – “세계 유일의 종합 반도체(IDM) 턴키 솔루션으로 대반격을 노린다”
삼성전자는 메모리, 파운드리, 그리고 AVP(첨단 패키징) 사업부를 모두 한 회사 안에 보유한 전 세계 유일무이한 종합 반도체 기업(IDM)입니다. 삼성은 이 이점을 극대화하여 TSMC-NVIDIA 동맹의 틈새를 파고드는 전략을 취하고 있습니다.
파운드리 본격 진입: 삼성전자 파운드리 사업부는 최근 300mm 웨이퍼 기반의 실리콘 포토닉스 공정 설계 키트(PDK) 개발을 완료하고 고객사 수주 준비를 마쳤습니다. 광신호를 결합하는 커플러, 빛의 통로인 도파로(Waveguide), 빛을 전기로 바꾸는 광다이오드(Photodiode) 등 핵심 광학 소자의 실리콘 검증을 끝낸 상태입니다.
강점과 약점 분석: * 약점: TSMC-NVIDIA 동맹처럼 당장 광학 칩을 대량으로 찍어내 줄 대형 앵커 고객사(Anchor Customer) 확보 측면에서는 출발이 늦은 것이 사실입니다.
강점: 그러나 향후 시장이 앞서 말한 ‘3단계(Optical Chiplet)’로 진화하여 HBM 메모리와 광학 엔진을 하나로 묶어야 할 때가 오면 이야기가 달라집니다. TSMC는 메모리(HBM)를 직접 만들지 못하므로 SK하이닉스나 마이크론에서 받아와야 하지만, 삼성전자는 [자사 고성능 HBM + 자체 파운드리의 광학 EIC/PIC 제조 + 자체 첨단 패키징]을 하나의 라인에서 단일 단가로 제공하는 ‘원스톱 턴키(Turn-key) 서비스’가 가능합니다. 이는 빅테크 기업들이 비용을 절감하고 공급망을 다변화하고자 할 때 엄청난 매력으로 작용할 것입니다.
② SK하이닉스 (SK Hynix) – “철저한 오픈 생태계 우군 확보 및 첨단 패키징 1위 수성”
SK하이닉스는 HBM 시장을 장악했던 방식과 유사하게, 자신들이 잘하는 분야에 날카롭게 집중하고 부족한 파운드리 영역은 글로벌 탑티어 기업들과의 연합으로 돌파하는 ‘오픈 생태계 및 가상 통합(Virtual IDM)’ 전략을 구사하고 있습니다.
SiP(System in Package) 기반 CPO 개발: SK하이닉스는 고유의 차세대 첨단 패키징 기술력(MR-MUF 등에서 축적된 하이브리드 본딩 기술)을 활용하여, 시스템 기판 위에 대형 로직 칩과 광 모듈을 초정밀로 병렬 배치하는 형태의 CPO 패키징 기술 개발에 집중하고 있습니다.
HBM-광 인터커넥트 연계: SK하이닉스는 6세대 HBM(HBM4E) 및 그 이후 단계에서 GPU와 HBM 간의 데이터 전송에 구리선 대신 빛을 쓰는 ‘광배선 HBM’ 표준을 선점하기 위해 미국의 글로벌 광통신 소자 기업들 및 TSMC와의 공동 연구를 극비리에 진행 중입니다. 엔비디아라는 확실한 핵심 고객사를 등에 업고 있기 때문에, 기술 표준 제정 과정에서 목소리가 매우 크다는 것이 강력한 무기입니다.
10. 엔지니어 시각에서의 냉정한 총평: 수율(Yield)과 신뢰성이라는 거대한 벽
이쯤에서 30년 차 엔지니어로서의 차가운 이성을 발휘해 보겠습니다. 엔비디아가 제시한 수치들(전력 효율 3.5배, 신호 무결성 63배 향상 등)은 이론적, 실험실 레벨에서는 인류 반도체 역사에 남을 대단한 도약이 맞습니다. 하지만 이를 실제 데이터센터 현장에 대량으로 깔아 실적을 내기까지는 두 가지 거대한 기술적 지뢰밭이 버티고 있습니다.
① 조립 수율(Assembly Yield)의 혹독한 현실
반도체는 기본적으로 ‘전자(Electron)’를 다루는 학문입니다. 전자는 선이 조금 비뚤어져도 길만 연결되어 있으면 흐릅니다. 하지만 ‘광자(Photon)’는 성질이 완전히 다릅니다. 빛은 직진성이 강하기 때문에, 광섬유와 칩 내부의 도파로(Waveguide)가 마이크로미터(㎛) 혹은 나노미터 단위로 정확하게 일렬 정렬(Alignment)되지 않으면 빛이 밖으로 다 새어 나가 버립니다(광 손실 발생).
현재 독립 리서치(SemiAnalysis 등)와 업계 내부 분석에 따르면, 65nm PIC와 로직 EIC를 3D 하이브리드 본딩으로 결합하는 초기 공정의 조립 수율은 20% 미만인 것으로 파악됩니다. 칩 10개를 만들면 8개는 불량으로 폐기해야 한다는 뜻입니다. 엔비디아가 Spectrum-X Photonics의 출시를 2026년으로 예고했음에도 불구하고, 본격적인 대량 양산(Mass Production) 및 대규모 인프라 적용 성숙기는 2028년~2029년은 되어야 도달할 수 있을 것으로 보는 이유가 바로 이 지독한 수율 문제 때문입니다.
② 패키지 내부 열팽창으로 인한 파장 뒤틀림 (Thermal Drift)
AI GPU와 스위치 ASIC은 연산할 때 섭씨 100도에 육박하는 엄청난 열을 뿜어냅니다. 반도체 패키지 내부의 온도가 이렇게 널뛰기를 하면, 물질의 미세한 열팽창이 일어납니다.
문제는 앞서 언급한 핵심 소자인 ‘마이크로 링 변조기’가 특정 온도의 미세한 파장에 극도로 민감하다는 점입니다. 열 때문에 링의 직경이 아주 미세하게 늘어나면 공진 파장이 틀어져 신호가 끊기거나 데이터 에러가 발생합니다. 이 열 문제를 해결하기 위해 정밀한 온도 조절 장치(Micro-Heater)를 칩 안에 심어야 하는데, 이것이 또 다른 전력 소모와 설계 복잡성을 유발합니다. 이 기술적 난제를 완벽하게 제어하는 기업만이 광반도체 시대의 진정한 승자가 될 것입니다.
11. 최종 투자 분석 및 사업 전망: 누가 빛의 판을 지배할 것인가?
30년 차 애널리스트 및 경제 블로거로서, 하드웨어 데이터와 거시 경제 환경을 종합한 ‘최종 투자 분석 및 자산 배분 전략’을 도출해 드리겠습니다.
🔷 단기적 관점 (1~2년): 공급망 병목과 ‘성장의 성장통’
단기적으로 이 시장은 혁신적인 기술이 주는 환호와 ‘낮은 초기 수율’이라는 냉정한 현실이 공존하는 변동성 장세가 될 것입니다.
브로드컴(Broadcom)의 단기 판정승 가능성: 엔비디아의 기술이 가장 진보적(3D 융합)이지만, 향후 1~2년간 데이터센터 현장에서는 안정적인 2.5D SiP 방식을 채택해 비용 효율성과 수율을 먼저 확보한 브로드컴의 솔루션이 시장 점유율을 방어하거나 오히려 실적 면에서 앞서갈 가능성이 높습니다.
단기 투자 최선호주 (Top Picks): * Lumentum (루멘텀) / Coherent (코히어런트): 엔비디아 진역과 반(反)엔비디아(브로드컴/시스코) 진영이 어떤 아키텍처 싸움을 벌이든, CPO 모듈에 필수적으로 들어가는 레이저 광원(InP/GaAs 기반 원천 소자)의 수요는 무조건 폭발합니다. 플랫폼 종속성이 없는 핵심 글로벌 부품사에 단기 모멘텀이 가장 확실하게 집중될 것입니다.
SK하이닉스: HBM3E 및 HBM4 초기 시장에서 독점적 지위를 유지하는 가운데, 엔비디아-TSMC 동맹과의 끈끈한 첨단 패키징 협력 관계를 통해 메모리 프리미엄을 계속 누릴 것입니다.
🔷 중장기적 관점 (3~5년): 밸류체인 재편과 최종 승자
2028년 이후 기술적 성숙기에 진입하면, 시장은 ‘종속형(NVIDIA-TSMC)’ vs ‘개방형(UEC-Broadcom-Cisco)’의 이분법적 구도로 재편되며, 빛의 영역은 마침내 HBM과 칩 내부(On-Chip) 영역으로 완전히 확장됩니다.
빅테크의 ‘반(反)엔비디아 연합’ 강화: 하이퍼스케일러(구글, 메타, MS 등)들은 인프라가 엔비디아에 통째로 종속(Lock-in)되는 것을 막기 위해, UEC 표준 기반의 개방형 이더넷 CPO 스위치를 강제로 채택해 균형을 맞출 것입니다. 이 시점에는 가격 경쟁력과 호환성이 높은 브로드컴 및 시스코-AMD 진영의 인프라가 전체 물량의 과반을 차지할 것으로 전망합니다.
중장기 투자 최선호주 (Top Picks):
삼성전자: 단기적으로는 파운드리 및 HBM 진입 지연으로 고전할 수 있으나, 2028~2030년 ‘Optical Chiplet’ 단계에 진입하면 판도가 바뀝니다. 삼성전자는 메모리 프리미엄과 파운드리, 패키징을 수직 계열화한 유일한 기업이기에, 공급망 다변화를 간절히 원하는 빅테크들에게 TSMC의 가장 매력적인 대안이자 파트너로 떠오를 것입니다. 삼성이 가진 종합 IDM 턴키 솔루션의 진가가 발휘되는 시점입니다.
인텔 (Intel): 자체 실리콘 통합 레이저 광원 기술을 보유하고 있으므로, 파운드리 공정 성숙도가 궤도에 올라오면 장기적인 IP 라이선싱 및 특수 목적 광학 칩렛 제조 분야에서 엄청난 잠재적 가치를 폭발시킬 수 있는 리스크 대비 보상이 큰 다크호스입니다.
12. 💡결론
NVIDIA의 Spectrum-X Photonics가 글로벌 자본 시장에 던진 메시지는 명확합니다.
“이제 반도체 기업의 몸값(멀티플)을 결정하는 것은 단순히 연산 속도를 높이는 능력이 아니라, 전력 장벽을 깨고 ‘빛을 자유자재로 다루는 능력(Optical Capability)’이다.”
지금 당장은 화려한 스포트라이트를 받는 엔비디아와 독점 제조사인 TSMC 동맹이 판을 지배하는 것처럼 보이지만, 네트워킹 시장의 오랜 본질은 항상 ‘호환성’, ‘오픈 소스’, 그리고 ‘비용 효율성’이었습니다.
따라서 현명한 투자자라면 단기적으로는 독점적 생태계를 구축해 당장 매출을 뽑아내고 있는 엔비디아와 핵심 광원 공급사(루멘텀)에 올라타되, 중장기적으로는 반(反)엔비디아 진영의 핵심 브레인인 브로드컴, 그리고 결국 ‘빛의 메모리’ 시대의 최종 포식자가 될 대한민국의 삼성전자와 SK하이닉스의 첨단 패키징 및 실리콘 포토닉스 로드맵 달성 여부를 분기별로 추적하며 저평가 구간마다 비중을 점진적으로 확대해 나가는 ‘바벨 전략(Barbell Strategy)’을 강력히 추천합니다.
빛의 시대는 이제 막 동이 트기 시작했습니다. 이 거대한 패러다임 시프트의 초입에서 흔들리지 않는 기술적 지식으로 무장하고 현명한 자산 배분을 이어가시길 응원합니다.
2026년 6월, 대한민국 테크 씬을 가장 뜨겁게 달군 사건은 단연 엔비디아(NVIDIA) 젠슨 황 CEO의 전격 방한이었습니다. 성수동 삼겹살 소맥 회동부터 야구장 시구, 홍대 PC방 깜짝 방문까지 그야말로 파격적인 행보의 연속이었습니다. 대중 매체와 커뮤니티는 그의 일거수일투족을 가십거리로 소비하기 바빴고, 여의도 증권가는 관련 수혜주 타이틀을 달기 위해 급급했습니다.
이번 방한은 단순한 비즈니스 미팅이나 친목 도모가 아닙니다. 과거 한국 기업들이 엔비디아의 단순한 ‘메모리 공급처(Supplier)’에 불과했다면, 이제는 현실 세계를 지배하려는 엔비디아의 ‘피지컬 AI(Physical AI) 및 온디바이스(On-device) 생태계의 핵심 파트너’로 지위가 격상되었음을 알리는 명확한 패러다임 시프트(Paradigm Shift)입니다.
동시에 시장은 무서운 변동성을 보여주며 개미들을 혼란에 빠뜨리고 있습니다. 오늘 포스팅에서는 기술 엔지니어링 관점의 깊이와 애널리스트의 냉철한 시각을 결합하여, 단기 변동성 진단, 삼성을 둘러싼 오해와 진실, 그리고 중장기 메가 트렌드에 따른 기업별 발전 방향을 해부해 드리겠습니다.
1. 단기적 관점: ‘재료 소멸’ 잔혹사와 옥석 가리기의 시작
“소문에 사서 뉴스에 팔아라 (Buy the rumor, sell the news).”
투자 시장의 이 오랜 격언은 이번에도 한 치의 오차 없이 증시를 관통했습니다. 젠슨 황 CEO의 방한 소식이 구체화되던 5월 말부터 국내 증시는 피지컬 AI, 로보틱스, 온디바이스 AI 수혜주라는 타이틀을 단 기업들의 주가가 가파르게 달아올랐습니다.
그러나 막상 젠슨 황 CEO가 입국한 6월 5일을 기점으로 LG, 네이버, 두산로보틱스 등 주요 기업들의 주가는 일제히 차익실현 매물이 쏟아지며 단기 조정을 겪고 있습니다. 전형적인 ‘모멘텀 소멸’이자 ‘재료 소멸’ 국면입니다.
단기 시장 진단: 스마트 머니는 이동하고 있다
이번 방한은 과거 그 어느 때보다 대중적 관심이 극대화되었습니다. 4대 그룹 총수 및 네이버 의장과의 성수동 회동, 예능 출연, 게이머들과의 스킨십 등 광폭 행보가 이어지며 기대감은 정점을 찍었습니다.
하지만 기관과 외국인 등 ‘스마트 머니(Smart Money)’의 시계는 대중보다 한발 빠릅니다. 그들은 이미 가치(Value)에 선반영된 밸류에이션 리스크를 털어내며, 이제는 막연한 ‘기대감’의 영역에서 ‘확인된 실적(숫자)’의 영역으로 넘어가길 원하고 있습니다.
냉정한 단기 투자 전략
현재 구간에서의 섣부른 추격 매수는 대단히 위험합니다. 주가의 높은 변동성을 경계해야 하는 구간입니다. 실질적인 공급 계약 공시, 구체적인 R&D 합작 법인(JV) 설립, 혹은 정부 및 과학기술정보통신부와의 구체적인 GPU 밸류체인 구축 등 ‘숫자와 계약서로 증명되는 모멘텀’이 나오기 전까지는 철저히 관망하거나, 조정기를 활용한 분할 매수(Accumulation) 접근이 유효합니다. 이제는 진짜와 가짜를 가려내는 ‘옥석 가리기’의 시간입니다.
2. 중장기적 관점: 가상 세계를 넘어 ‘피지컬 AI’와 ‘로보틱스’로
엔비디아가 바라보는 컴퓨팅의 다음 종착지는 명확합니다. 거대언어모델(LLM)이 거주하는 모니터 속 가상 세계를 넘어, 우리가 발을 디디고 있는 현실 세계와 실시간으로 상호작용하는 ‘피지컬 AI(Physical AI)’와 ‘로보틱스’입니다.
젠슨 황 CEO는 방한 일성으로 이렇게 공언했습니다.
“한국은 세계 최고 수준의 하이테크 제조 역량, 정밀 메카트로닉스, 그리고 독자적인 AI 인프라를 모두 갖춘 전 세계에서 몇 안 되는 완벽한 로보틱스 허브(Hub)다.”
이 발언의 행간을 읽어야 합니다. 텍스트를 생성하고 이미지를 그리는 AI 소프트웨어는 전력과 인프라 비용의 한계(Infra Cost Bottleneck)에 직면해 있습니다. 이를 돌파하기 위해 엔비디아는 AI에게 ‘육체’를 부여하고 전력, 물리적 역학(Physics), 지연 시간(Latency)을 통제하는 시스템을 구축하고자 합니다.
그리고 그 육체(하드웨어 디바이스)를 가장 잘 만드는 나라가 바로 대한민국입니다. 이는 국내 IT, 반도체, 자동차, 로봇 생태계 전반에 단순 부품 납품을 넘어선 거대한 중장기적 구조적 성장(Structural Growth)과 막대한 낙수효과를 예고하는 대전환점입니다.
3. 삼성을 둘러싼 오해와 진실: ‘패싱론’인가, ‘진짜 게임’의 시작인가?
이번 방한 기간 중 대중 매체와 소셜 미디어를 가장 뜨겁게 달군 논란은 “왜 삼성이 보이지 않는가?”였습니다. 첫날 성수동 삼겹살 소맥 회동에 최태원 SK 회장, 정의선 현대차 회장, 구광모 LG 회장, 이해진 네이버 의장 등 거물들이 총출동했음에도 불구하고 이재용 삼성전자 회장의 모습은 보이지 않았기 때문입니다. 이를 두고 언론에서는 “삼성이 엔비디아 생태계에서 소외되거나 패싱당한 것 아니냐”는 자극적인 분석을 쏟아냈습니다.
결론부터 말씀드리겠습니다. 삼성은 ‘빠진 것’이 아니라 미팅의 성격과 스케줄의 우선순위가 완전히 달랐을 뿐이며, 무대 뒤 물밑에서는 가장 거대하고 냉혹한 판이 짜이고 있습니다. 전면에서 보이지 않았던 진짜 이유를 완벽히 알려 드리겠습니다.
① 이재용 회장의 부재와 탑다운 전략의 미공개 이면
일부 지라시나 루머에서는 “이재용 회장이 방한 수주일 전 캘리포니아에서 젠슨 황과 단독 만찬을 가졌고 이를 젠슨 황이 직접 밝혔다”고 떠돌아다니지만, 이는 완전한 사실무근(Fact Check Fail)입니다.
진짜 팩트는 이번 젠슨 황 방한 기간에 이재용 회장은 사전에 계획된 중요한 글로벌 해외 출장 스케줄을 소화 중이었다는 점입니다. 오너가 자리를 비운 상황에서, 엔비디아와의 핵심 협상은 비즈니스 실무를 총괄하는 사령탑에게 자연스럽게 위임된 것입니다.
② 실무 사령탑의 교체: 전영현 부회장 체제와의 냉혹한 ‘독대’
친목 도모 성격이 짙었던 첫날 단체 회동에 삼성이 참여하지 않은 진짜 실무적 이유는, 최근 삼성전자 반도체(DS) 부문의 사령탑이 전영현 부회장 체제로 전격 교체된 시점과 맞물려 있습니다. 지금 삼성 DS부문은 친목을 다질 여유가 없습니다. 철저하게 실리와 기술적 돌파구를 찾아야 하는 엄중한 시기입니다.
젠슨 황 CEO는 월요일(6월 8일) 신라호텔에서 전영현 삼성전자 DS부문장(부회장)을 비롯한 고위 실무진과 별도의 비공개 독대 및 기술 회동을 가졌습니다. 시장 분위기에 휩쓸리는 파티 참석보다, 양사에게 가장 시급한 현안인 차세대 AI 가속기 ‘베라 루빈(Vera Rubin)’ 플랫폼에 탑재될 HBM 공급선 다변화, 퀄 테스트(Quality Test) 통과 시점 조율, 그리고 파운드리 및 첨단 패키징을 아우르는 핵심 비즈니스를 테이블 위에 올려놓고 밤새 도면을 보며 주판알을 튕긴 것입니다.
③ 공급망 진입의 팩트: 3사 모두 HBM4 퀄 통과 완료
이번 방한에서 가장 강력한 팩트는 젠슨 황 CEO가 입국 직후 기자회견에서 “삼성전자, SK하이닉스, 마이크론 등 메모리 3사 모두 우리의 차세대 HBM4 퀄리피케이션(수용성 테스트)을 통과하여 양산 및 공급 단계에 진입했다”고 공식 선언한 점입니다.
그동안 시장을 지배했던 “삼성이 퀄 테스트에서 고전하고 있다”는 우려를 엔비디아 수장이 직접 불식시킨 것입니다. 이제 시장의 프레임은 ‘삼성 패싱론’이 아니라 ‘삼성이 본격적으로 공급 경쟁 체제에 진입했다’로 완전히 수정되어야 마땅합니다.
④ 엔비디아의 생존 전략: TSMC 독점 타파를 위한 ‘거대한 고래’ 삼성
엔비디아 입장에서도 현재 대만의 TSMC에만 파운드리와 패키징을 전적으로 의존하는 구조는 거대한 지정학적 리스크이자 공급 부족(Shortage)의 원인입니다. 엔비디아는 이 독점 체제를 깨뜨릴 강력한 카드가 절대적으로 필요하며, 전 세계에서 그 대안이 될 수 있는 유일한 기업이 바로 삼성전자입니다.
구분
SK하이닉스 체인
삼성전자 체인
HBM 공급
HBM3E 독점적 지위 확보 및 HBM4 고도화
HBM4 퀄 통과 완료로 본격적인 물량 경쟁 진입
공정 구조
메모리 설계 전문 + 베이스 다이는 TSMC 협력
메모리 + 파운드리 + 패키징 원스톱 턴키(Turn-key)
엔비디아 전략
견고한 ‘깐부’ 동맹 유지 (First Vendor)
공급망 다변화 및 가격 협상력 확보 (Dual Sourcing)
삼성은 전 세계에서 유일하게 Memory(HBM4) + Foundry(첨단 로직 공정) + Advanced Packaging을 한 지붕 아래에서 원스톱으로 제공할 수 있는 IDM(종합 반도체 기업)입니다. 최근 GTC 무대에서도 젠슨 황이 삼성 부스를 직접 찾아 HBM4 웨이퍼에 사인을 남기며 극찬한 이유가 여기에 있습니다.
결론적으로 지금의 공백은 패싱이 아니라 ‘철저히 계산된 기술 실무 집중’입니다. 하반기 공급 계약의 구체적인 숫자가 찍히는 순간, 시장의 평가는 180도 뒤바뀔 것입니다.
4. 핵심 참여 기업별 기술적 내면 및 중장기 발전 방향
“하드웨어 없는 소프트웨어는 허상(Ghost)이고, 소프트웨어 없는 하드웨어는 고철(Iron)에 불과하다.”
엔지니어 출신인 제가 늘 가슴에 새기는 격언입니다. 엔비디아라는 거대한 가상 세계의 ‘운영체제(OS)’가 현실 세계라는 하드웨어 하체에 이식되는 과정에서, 국내 핵심 기업들이 어떤 기술적 칼자루를 쥐고 있는지 현미경 분석해 드리겠습니다.
① SK그룹 (SK하이닉스 / SK텔레콤) — 완벽한 ‘AI 깐부’의 기술적 굳히기
⚙️ 핵심 기술 분석: MR-MUF 공정 노하우와 초고속 인터커넥트
SK하이닉스가 HBM3E 시장을 지배하고 HBM4에서도 강력한 지위를 유지할 수 있는 일등 공신은 Advanced MR-MUF(Mass Reflow Molded Underfill) 공정 기술입니다. 반도체 칩을 쌓을 때 열을 가해 수천 개의 미세 돌기(범프)를 한 번에 연결하고, 칩 사이의 공극을 액체 형태의 보호재로 채워 굳히는 기술입니다. 경쟁사들의 NCF(비전도성 필름) 방식에 비해 열 방출 효율이 2.5배 이상 뛰어나며, 공정 압력도 낮아 칩의 휘어짐(Warpage) 현상을 완벽하게 제어합니다. 엔비디아 가속기가 뿜어내는 무시무시한 열 밀도(Thermal Density) 문제를 하드웨어 단에서 해결해 준 핵심 열쇠입니다.
🚀 중장기 발전 방향 및 기대 요소
하반기 본격화될 차세대 가속기 물량 공급은 물론, 엔비디아가 노트북 및 모바일 에지 단을 겨냥해 내놓은 초소형 칩 ‘RTX 스파크(Spark)’ 생태계에서 초저전력·고대역폭 모바일 메모리(LPDDR5X, LPCAMM2) 수요가 폭증할 것입니다. SK텔레콤 역시 엔비디아의 AI 인프라를 국내 및 아시아 지역의 제조·물류 피지컬 AI 실증 기지에 이식하는 핵심 서비스 파트너로서 협력을 심화하며 실적의 장기 우상향 궤도를 그릴 것으로 전망됩니다.
② LG그룹 — 자율주행 및 가전 피지컬 AI의 탑티어 하드웨어 파트너
⚙️ 핵심 기술 분석: Zonal ECU 통합 아키텍처 및 로우 그레이드 비전 AI
LG전자는 더 이상 단순한 세탁기, 냉장고 제조사가 아닙니다. 미래 모빌리티와 스마트 홈을 관통하는 전장(VS) 및 AI 가전의 핵심 하드웨어 아키텍처를 쥐고 있습니다. 미래의 자동차와 로봇은 수십 개의 독립된 ECU(전자제어유닛) 대신, 하나의 강력한 중앙 집중형 컴퓨터가 차량 전체를 제어하는 SDV(소프트웨어 중심 자동차) 구조로 진화합니다. LG전자는 엔비디아의 드라이브 토르(Drive Thor) 고성능 칩셋을 받아 실제 가전과 차량의 로우레벨 통신(CAN/LIN) 및 오토사(AUTOSAR) OS 레이어와 결합하는 시스템 통합(SI) 기술력에서 글로벌 탑티어 수준입니다.
또한, 자율주행과 로보틱스의 눈 역할을 하는 LG이노텍의 비전 AI 카메라 시스템을 주목해야 합니다. 단순히 이미지를 캡처하는 것을 넘어, 야간이나 어두운 터널 등 로우 그레이드(Low-grayscale) 이미지 데이터 환경에서도 노이즈를 극한으로 제어하고 엔비디아의 이미지 처리 장치(ISP)와 다이렉트로 연동되는 고성능 패키징 기술을 보유하고 있습니다.
🚀 중장기 발전 방향 및 기대 요소
구광모 회장과의 연쇄 회동을 통해 협력은 더욱 구체화되었습니다. 특히 LG그룹이 최근 공개한 휴머노이드 로봇 ‘CLOiD(클로이드)’가 엔비디아의 로봇 개발 플랫폼인 ‘아이작(Isaac)’을 통해 가상 시뮬레이션 학습을 거치고 엔비디아의 최신 로봇 전용 칩셋을 탑재하고 있다는 사실이 확인되었습니다. 단기 주가는 테마성 수급으로 출렁였으나, 엔비디아의 로봇·모빌리티 생태계에 LG의 하드웨어 제조 역량이 깊숙이 이식되면서 전장 부문의 리레이팅(가치 재평가)이 중장기적으로 진행될 것입니다.
③ 현대자동차그룹 — 스마트 팩토리 ‘디지털 트윈’과 자율주행의 고도화
⚙️ 핵심 기술 분석: 옴니버스(Omniverse) 기반 가상 공장 실증 및 SDV 전환
정의선 회장과의 성수동 삼겹살 회동에서 논의된 핵심 이면은 단순히 차량에 AI 칩을 몇 개 넣느냐의 수준이 아닙니다. 제조 공장 자체를 하나의 거대한 AI 로봇으로 진화시키는 ‘디지털 트윈(Digital Twin)’과 자율주행 하이퍼 컴퓨팅의 결합입니다.
현대차그룹은 이미 싱가포르 글로벌 혁신센터(HMGICS)에서 가상 공간에 실제 공장과 1:1로 매칭되는 디지털 트윈을 구축하고, 엔비디아의 옴니버스(Omniverse) 플랫폼을 통해 AI 시뮬레이션으로 공정 최적화 및 로봇 동선을 테스트하는 아키텍처를 세계 최초 수준으로 실증해 냈습니다.
🚀 중장기 발전 방향 및 기대 요소
일부에서는 이번 방한을 두고 새로운 대규모 투자 발표를 기대했으나, 현대차그룹이 엔비디아와 맺은 3조 원 규모의 자율주행 및 스마트 팩토리 하이퍼 컴퓨팅 인프라 투자 MOU는 이미 지난 2025년 10월에 체결되어 가동 중인 사안(Fact Check)입니다. 이번 만남은 해당 프로젝트의 중간 점검 및 양산 차량으로의 소프트웨어 이식 속도를 높이기 위한 다지기 단계입니다. 현대차의 자율주행 합작법인 모셔널(Motional)의 하드웨어 플랫폼 위에 엔비디아의 풀스택 소프트웨어를 결합하여 레벨 4 자율주행의 상용화 시점을 글로벌 경쟁사보다 앞당기는 발판이 마련되었습니다.
④ 네이버(NAVER) — 빅테크 독점에 맞서는 ‘소버린(Sovereign) AI’ 동맹
⚙️ 핵심 기술 분석: 네모트론(Nemotron)과 하이퍼클로바X의 이종(Heterogeneous) 모델 최적화
미국 빅테크 중심의 AI 생태계가 전 세계를 잠식하는 가운데, 국가별 문화, 종교, 법적 규제와 언어 장벽을 방어하려는 ‘소버린 AI(Sovereign AI)’ 열풍은 네이버에게 거대한 독점적 기회입니다. 젠슨 황 CEO가 이해진 의장과 심야 회동을 가진 본질적인 이유도 여기에 있습니다.
기술적으로는 엔비디아의 가벼운 오픈 LLM인 ‘네모트론(Nemotron)’ 아키텍처 인프라 위에, 네이버가 독자적으로 구축한 한국어 및 아랍어 등 비영어권 특화 고품질 데이터셋과 정렬(Alignment) 기술을 하이브리드 파이프라인으로 결합하는 전략입니다. 또한, AI 모델을 칩에 올리기 위해 필수적인 모델 경량화(Quantization) 및 하이바인딩 소프트웨어 최적화 기술이 핵심입니다.
🚀 중장기 발전 방향 및 기대 요소
엔비디아의 초대형 AI 가속기 클러스터(DGX SuperPOD)를 중동이나 아시아 국가에 수출할 때, 이를 효율적으로 제어하고 분산 학습(Distributed Training)을 최적화하는 거대 플랫폼 소프트웨어를 네이버클라우드가 패키지 형태로 결합하여 공동 진출하는 비즈니스 모델이 가시화되고 있습니다. 네이버는 이를 통해 국내 내수 기업이라는 한계를 극복하고, 글로벌 소버린 AI 동맹의 중추적인 소프트웨어 파트너로 도약할 모멘텀을 확보했습니다.
⑤ 두산로보틱스 — 로봇 공학의 비약적 도약과 실시간 토크 제어
⚙️ 핵심 기술 분석: 아이작 매니퓰레이터(Isaac Manipulator)와 로우레벨 펌웨어 정렬
젠슨 황 CEO의 장녀이자 엔비디아 로보틱스 부문의 핵심 임원인 매니 황(Madison Huang)이 두산 연구소를 직접 찾고, 뒤이어 박정원 회장과의 야구장 회동으로 이어진 동선은 대단히 상징적입니다. 가상 세계에서 아무리 강력한 AI 인공지능이 판단을 내려도, 현실 세계에서 물건을 정밀하게 잡고(Grasping) 부드럽게 옮기는 ‘물리적 액추에이터 및 감속기 제어 기술’이 없으면 피지컬 AI는 미완성에 그치기 때문입니다.
엔비디아의 로봇 가속 플랫폼인 ‘Isaac’의 비전 AI 알고리즘이 내린 고차원 명령을 받아, 두산로보틱스의 정밀 감속기 및 모터 제어 보드가 1mm 이하의 오차 범위 내에서 실시간(Real-time)으로 반응하도록 로우레벨 펌웨어 레이어를 통합하는 작업이 핵심 기술 협력의 본질입니다.
🚀 중장기 발전 방향 및 기대 요소
단순히 공장에서 지정된 궤적만 반복하는 1세대 협동로봇을 넘어, 변화하는 환경을 스스로 인식하고 사람과 안전하게 협업하는 ‘지능형 서비스 및 휴머노이드 로봇’ 시장의 개막을 앞당길 것입니다. 엔비디아의 강력한 소프트웨어 우산 아래에서 두산의 하드웨어 경쟁력이 결합되며 글로벌 표준(Standard)을 선점할 수 있는 기회입니다.
⑥ 게임 업계 (크래프톤 / 엔씨소프트) — 온디바이스 AI PC 시장의 개막과 인게임 SLM
⚙️ 핵심 기술 분석: 엔비디아 ACE(Avatar Cloud Engine)의 로컬 런타임 최적화
젠슨 황 CEO가 홍대와 강남의 PC방을 직접 순회하며 게이머들과 만난 행보는 단순한 쇼맨십이 아닙니다. 막대한 클라우드 서버 비용(Infra Cost)을 절감하기 위해 사용자 PC에 장착된 지포스(RTX) 그래픽카드의 텐서 코어(Tensor Core) 자원을 활용하려는 ‘온디바이스 AI 에이전트’ 생태계 확산을 위한 철저한 계산입니다.
게임 개발 과정에서 엔비디아의 ACE(Avatar Cloud Engine) 및 Audio2Face(음성 기반 안면 애니메이션 생성 기술)를 이식하면, 게임 프레임을 뽑아내는 메인 렌더링 루프(Rendering Loop)를 방해하지 않으면서도 사용자의 그래픽카드 여유 자원을 활용해 경량 인게임 소형언어모델(SLM)을 서버 통신 지연(Latency) 없이 완전히 로컬(Local) 단에서 구동할 수 있게 됩니다.
🚀 중장기 발전 방향 및 기대 요소
크래프톤이 데모로 선보인 것처럼, 배틀그라운드 게임 내에서 유저와 실시간 음성으로 전술을 짜고 상황에 맞춰 유기적으로 반응하는 ‘AI 동료(Co-playable character)’ 기술이 본격 도입될 것입니다. 이는 유저들에게 완전히 새로운 차원의 몰입감을 선사하며, 고사양 게이밍 기어 하드웨어 교체 주기와 맞물려 게임 타이틀 및 소프트웨어 매출의 거대한 새로운 업사이클(Up-cycle)을 견인할 것입니다.
5. 결론: 포트폴리오를 재편하라
“축제(Event)의 소음은 끝났습니다. 그러나 진짜 자본의 낙수효과는 하반기 공급망 가동과 함께 시작됩니다.”
대중들이 뉴스 헤드라인과 총수들의 회동 장소, 단기 주가 등락에 일희일비하며 패닉 셀(Panic Sell)이나 포모(FOMO)에 빠져 있을 때, 현명한 투자자는 차분하게 포트폴리오의 파이프라인을 정비해야 합니다. 이번 젠슨 황 엔비디아 CEO의 방한은 한국 IT·제조업이 단순한 하청 구조에서 벗어나 체질 개선(Structural Re-rating)을 이루는 명확한 신호탄입니다.
마지막으로 자산 배분 관점에서의 날카로운 바이블 전략을 제안해 드립니다.
포트폴리오의 닻(Anchor)은 대형 반도체주로: 단기적인 ‘퀄 테스트 논란’이나 소외론 등 노이즈로 인해 주가가 과도하게 눌리는 구간이 있다면, 이를 강력한 매수 기회로 삼아야 합니다. 엔비디아 공급망 다변화의 최대 수혜가 될 삼성전자와 확고한 독점적 지위를 다진 SK하이닉스라는 두 거대한 고래를 포트폴리오의 중심 축에 균형 있게 배치하십시오.
조정기마다 비중을 확대할 섹터: 엔비디아가 공언한 국내 R&D 센터 설립 및 과기부와의 핵심 밸류체인 구축 과정에서 실질적인 수혜를 입을 로보틱스(하드웨어 액추에이터, 감속기) 섹터와 현실 세계 데이터를 처리할 비전 AI 및 전장용 하드웨어 핵심 부품 섹터를 주목하십시오. 막연한 테마주가 아닌, 글로벌 리더들과 실제 협력 프로젝트 레퍼런스를 가진 기업들로 좁혀야 합니다.
가상 세계에만 갇혀 있던 인공지능이 우리의 삶과 산업 현장이라는 물리적 공간으로 쏟아져 나오는 ‘피지컬 AI 혁명’은 이제 막 서막을 올렸을 뿐입니다. 단기 수급 노이즈에 흔들리지 않고 기술의 본질과 실적 숫자를 추적하는 자만이 이 위대한 자본의 흐름 위에서 거대한 자산을 거머쥘 수 있을 것입니다.
타이베이 컴퓨텍스(COMPUTEX) 2026 현장의 생생한 단서들은 지금 자본 시장이 어디로 미친 듯이 몰려가고 있는지, 그리고 향후 수년간 어떤 기업이 거대한 부를 쥐게 될지 증명하는 강력한 선행 지표입니다.
올해 컴퓨텍스의 슬로건은 “AI Together”이지만, 투자자의 스크린에 투사된 진짜 본질은 “을(Supplier)의 초격차 무기와 갑(Buyer)의 종속”입니다. 설계 자산(IP)을 가진 빅테크들이 화려한 스포트라이트를 받으며 무대에 서지만, 이를 물리적 실체로 구현해 내는 하드웨어 인프라와 독점적 후공정 장비 공급망을 쥔 기업들이 가격 결정권(Pricing Power)을 완벽하게 장악했기 때문입니다.
엔지니어님의 기술 분석을 경제학적 밸류체인(Value Chain)과 자본의 역학 구조로 치환하여, 투자자가 반드시 거머쥐어야 할 ‘컴퓨텍스 2026 핵심 투자 바이블’을 아주 딥하게 전해드립니다.
1. Macro 관점의 판도 변화 및 투자 요약
시장의 판도가 요동치고 있습니다. 이번 컴퓨텍스 2026에서 드러난 거시적 변화는 크게 두 가지 타임라인으로 요약됩니다.
⏳ 단기적 관점 (6개월~1년): 메모리 쇼티지(Shortage)와 수율 통제력
엔비디아의 차세대 아키텍처 ‘베라 루빈(Vera Rubin, VR200)’의 본격 양산 스케줄이 당초 예상보다 빨라졌습니다. 이 거대한 가속기 랙 인프라가 요구하는 부품 수는 무려 200만 개에 달합니다.
그중에서도 가장 극심한 병목이 걸린 곳은 단연 6세대 고대역폭 메모리인 HBM4와 이종 집적 패키징을 위한 초정밀 후공정 장비입니다. 당장 올해 하반기부터 내년까지 실적의 숫자가 가장 확실하고 가시적으로 찍힐 밸류체인 최상위 포지션 기업에 자본을 압축 대응해야 하는 이유입니다.
🔭 중장기적 관점 (3년~5년): ‘Wintel’ 동맹의 해체와 물리적 에이전트의 대중화
엔비디아가 미디어텍과 손잡고 출시한 ‘RTX Spark’ 슈퍼칩은 단순한 신제품이 아닙니다. 지난 수십 년간 전 세계 PC 생태계를 지배해 온 ‘윈텔(Wintel: Windows + Intel)’ 동맹의 몰락을 알리는 서막입니다.
향후 온디바이스(On-device) 디바이스 시장은 ‘더 저렴한 프로세서’가 아니라, ‘OS 레벨에서 AI 에이전트를 독립적으로 구동할 수 있는 저전력 고효율 아키텍처’와 ‘이종 집적 패키징 역량’을 내재화한 진영이 헤게모니를 쥘 것입니다. 자본은 이 아키텍처 전환 과정에서 필수재를 공급하는 생태계 지배자들에게 장기 정착할 것입니다.
2. 반도체 양대 거인 분석: SK하이닉스 vs 삼성전자
엔비디아, 인텔, AMD의 화려한 연설 뒤에서 실제 주가를 움직이는 가장 큰 에너지는 한국의 메모리 반도체 밸류체인입니다. 젠슨 황 CEO가 직접 “루빈 플랫폼에 한국의 HBM4가 탑재된다”고 공식 확인해 주면서 양사의 주도권 싸움은 한층 더 격렬해졌습니다.
🥇 SK하이닉스(000660): 엔비디아-TSMC 삼각동맹의 절대적 수혜주
“Advanced MR-MUF 기반 16단 HBM4 선점으로 탑티어(Top-tier) 권력 수성”
💡 기술적 자산과 투자 가치
SK하이닉스가 세계 최초로 실물을 공개한 16단 HBM4(48GB)는 동사의 기술적 해자(Moat)가 얼마나 단단한지 보여줍니다. 6세대 HBM부터는 베이스 다이(Base Die)를 기존 메모리 공정이 아닌 TSMC의 최첨단 파운드리 공정(3나노 등)으로 제작해야 합니다.
이는 단순히 제품을 잘 만드는 것을 넘어, ‘TSMC-하이닉스-엔비디아’로 이어지는 삼각 원팀 동맹에 균열을 내기가 후발주자 입장에서 대단히 어렵다는 뜻입니다. 베라 루빈 초기 물량의 약 60~70%를 하이닉스가 선점할 것이라는 시장의 관측은 하반기 주가 리레이팅(Re-rating)의 강력한 촉매입니다.
⚠️ 재무적 리스크 및 모니터링 포인트
가장 큰 변수는 대규모 설비투자(CAPEX)의 효율성입니다. 칩이 얇아지면서 발생하는 휘어짐 현상과 발열을 잡기 위해 소재 비용이 상승하고 있습니다.
이번에 발표한 엔비디아 옴니버스 기반의 ‘디지털 트윈(Digital Twin) 팹’ 구축은 단순한 기술 자랑이 아니라, 수백 단계 공정의 병목을 가상 시뮬레이션으로 제어하여 초기 수율 리스크를 비용 측면에서 얼마나 방어해 내느냐가 핵심입니다. 수율 안정화 속도가 동사의 2026년 하반기 영업이익률의 스윗 스팟을 결정할 것입니다. [중장기 Buy & Hold 전략 유효]
🥈 삼성전자(005930): 턴키(Turn-key) 솔루션을 무기로 한 거대한 역습
“루빈 공급망 진입 확정과 7세대 HBM4E 선공개를 통한 판도 뒤집기”
💡 기술적 자산과 투자 가치
그간 시장에서 삼성전자를 짓누르던 HBM 검증 불확실성이 이번 컴퓨텍스 2026을 기점으로 완전히 해소되었습니다. 루빈 플랫폼 공급망의 약 25~30% 물량을 확보한 것으로 추정되는 가운데, 삼성은 시장의 예상을 깨고 2027년 출시 예정인 베라 루빈 울트라향 7세대 ‘HBM4E’ 샘플을 선제적으로 출하하며 전면에 전시했습니다. 이는 후발주자로서의 추격 속도가 무서운 수준에 도달했음을 의미합니다.
🌟 종합 반도체 기업(IDM)의 진가: 원스톱 패키지
삼성전자의 진짜 무서운 무기는 ‘종합 턴키(Turn-key) 솔루션’ 능력에 있습니다. 하이닉스 연합군과 달리 삼성은 다음을 자체적으로 해결할 수 있는 지구상 유일한 기업입니다.
메모리(HBM4) 제조
파운드리(베이스 다이) 생산
어드밴스드 패키징(I-Cube) 공정
글로벌 빅테크(CSP)들이 엔비디아의 독점을 깨기 위해 맞춤형(Custom) AI 가속기를 자체 설계할 때, 개발 기간을 극적으로 줄이고 비용(TCO)을 아낄 수 있는 삼성의 턴키 솔루션은 거부할 수 없는 대안이 됩니다.
더불어, 엔지니어님께서 강조하신 데이터센터의 용량 한계를 깨는 CXL 3.0/3.1 기반 메모리 모듈(CMM) 생태계 선점은 HBM 이후 삼성전자의 중장기 밸류에이션을 지탱할 거대한 캐시카우가 될 것입니다. [단기 트레이딩 펀더멘털 회복 및 중장기 비중 확대 전략]
3. 무대 뒤의 진짜 지배자: 국내 소부장 및 강소기업 정밀 분석
자본 시장에서 진짜 폭발적인 수익률(멀티플)은 모두가 아는 거인들이 아니라, 그 거인들의 손에 독점 작전 무기를 쥐여주는 ‘슈퍼 을’ 기업에서 나옵니다. 이번 컴퓨텍스 2026에서 글로벌 빅테크들의 러브콜을 받으며 밸류체인의 핵심 축으로 우뚝 선 국내 기업들을 정밀 해부합니다.
🚀 한미반도체(042700): HBM 패키징 공정의 대체 불가능한 지배자
“칩 면적 확대(Wide) 트렌드에 따른 ‘와이드 TC 본더’ 독점 공급망 장악”
📊 투자 핵심 요약
HBM4부터는 데이터 고속도로(I/O)가 2048개로 기존보다 2배 넓어집니다. 실리콘 다이의 면적 자체가 옆으로 넓어진다는 뜻입니다. 한미반도체가 이번 컴퓨텍스에서 최초로 공개한 ‘와이드 TC 본더(Wide Thermocompressor Bonder)’는 이 넓어진 칩을 마이크로미터 단위의 오차 없이 정밀하게 수직 적층하는 장비입니다.
📈 밸류에이션 및 아웃룩
하이닉스의 16단 HBM4 독점 공급망을 뒷받침하는 핵심 뼈대일 뿐만 아니라, 컴퓨텍스 현장에서 대만 TSMC의 최첨단 패키징 라인(CoWoS) 관계자들이 줄을 서서 미팅을 진행한 점에 주목해야 합니다. 현재 주가가 다소 높은 멀티플(PER)을 적용받고 있는 것은 사실이나, HBM의 단수 증가와 면적 확대에 따른 장비 교체 주기는 동사의 매출 패스를 가파른 우상향으로 이끌 것입니다. 시장의 조정을 받을 때마다 무조건 주워 담아야 할 0순위 장비주입니다.
🧠 딥엑스(DEEPX – 상장 준비 중): 피지컬 AI 시대의 엣지(Edge) 제왕
“전력 제약이 극심한 로봇 및 온디바이스 환경을 저격하는 독보적 가성비 NPU”
📊 투자 핵심 요약
엔비디아가 데이터센터라는 거대한 전력 괴물을 움직인다면, 딥엑스는 공장, 자율주행 로봇, CCTV 등 단 몇 와트(W)의 전력만 허용되는 가혹한 환경을 지배할 ‘DX-M1’ 칩을 보유하고 있습니다. 이번 컴퓨텍스 2026에 신설된 ‘AI 로보틱스 존’에서 30여 개 글로벌 기업과의 협력을 발표하며 현지 분위기를 뒤흔들었습니다.
📈 밸류에이션 및 아웃룩
이들의 핵심 자산은 인공지능 모델의 정확도 손실 없이 데이터 연산 정밀도를 낮추어 속도를 극대화하는 양자화(Quantization) 및 압축 알고리즘 기술력입니다. 가상 세계의 AI 에이전트가 현실 세계의 기기(Physical AI)로 튀어나오는 현시점에서 가장 가파른 성장 모멘텀을 가졌습니다. IPO(기업공개) 진행 시 공모주 청약은 물론, 프리 IPO 지분을 보유한 상장사나 관련 펀드까지 추적하여 포트폴리오에 반드시 편입해야 할 숨은 보석입니다.
💻 알세미(ALSEMI) & SK텔레콤(017670): 제조 공정용 ‘에이전틱 디지털 트윈’의 심장
“물리 법칙 기반 시뮬레이션과 LLM 에이전트 아키텍처의 결합”
📊 투자 핵심 요약
반도체와 디스플레이 공정은 눈에 보이지 않는 화학 반응과 유체역학 등 가혹한 물리 법칙의 지배를 받습니다. 인공지능 스타트업 ‘알세미’와 LG디스플레이가 연합하여 엔비디아의 ‘피직스니모(PhysicsNeMo)’를 이식해 만든 디지털 트윈 생산 시스템(DPS)은 단순한 모니터링 툴이 아닙니다.
“특정 챔버의 온도가 미세하게 변했을 때 회로막 수율이 어떻게 변하는지”를 실시간 시뮬레이션해 내는 소프트웨어 공학의 결정체입니다. 여기에 SK텔레콤의 ‘에이전틱 디지털 트윈 모델링’ 기술이 결합되어, 사람이 도면을 입력하지 않아도 AI 에이전트가 공장의 구동 데이터를 스스로 학습해 디지털 트윈 환경을 자동 업데이트합니다.
📈 밸류에이션 및 아웃룩
SK텔레콤은 이제 단순한 통신 배당주가 아닙니다. 엔비디아 오케스트레이션(Omniverse) 생태계 위에서 자율 제조 공장(Autonomous Factory)의 뼈대를 구축하는 ‘AI 인프라 프로바이더’로의 체질 개선(Valuation Multiple 격상)이 진행 중입니다. 수율 향상에 목마른 글로벌 반도체 Fab들이 대거 도입을 검토하고 있어, 기업향(B2B) AI 소프트웨어 부문에서 가장 먼저 대규모 매출 유입이 기대되는 확실한 모멘텀입니다.
📺 삼성디스플레이: AI PC 하드웨어 설계 마진의 구원투수
“울트라 슬림(Ultra Slim) OLED 패키징을 통한 물리적 공간 확보”
📊 투자 핵심 요약
인텔의 노바레이크(Nova Lake)와 엔비디아의 RTX Spark 등 온디바이스 AI 칩셋들의 성능이 폭발하면서 노트북 제조사들은 고질적인 문제에 직면했습니다. 발열을 잡기 위한 쿨링 솔루션(히트파이프, 대형 팬)과 고전력 소모를 버틸 대용량 배터리가 하판 공간을 가득 채워야 하기 때문입니다.
📈 밸류에이션 및 아웃룩
삼성디스플레이가 컴퓨텍스에서 선보인 ‘울트라 슬림 노트북 OLED’ 패널은 기존 양산품 대비 모듈 두께를 20% 이상 줄였습니다. 디스플레이 패널 두께를 극단적으로 깎아준 덕분에, 에이수스(ASUS), MSI 같은 PC 제조사들은 슬림한 디자인을 유지하면서도 고성능 쿨러를 박아 넣을 수 있는 ‘하드웨어 설계 마진’을 확보하게 되었습니다.
AI PC 시대로의 강제 전환 흐름 속에서 완제품의 승패와 무관하게 모든 글로벌 PC 제조사에 패널을 공급할 수 있는 독점적 지위를 가진 숨은 수혜주입니다. 모회사인 삼성전자 주가에 긍정적인 자회사 지분 가치로 반영될 핵심 트리거입니다.
4. 블루오션 집중 분석: ‘메모리 벽’을 깨는 CXL 생태계 투자 전략
30년 동안 시장의 사계절을 겪으며 제가 깨달은 자본 시장의 절대 진리는 하나입니다. “기술의 임계점(Bottleneck)이 발생하는 곳에 언제나 가장 큰 투자 기회와 폭발적인 멀티플이 존재한다”는 점입니다.
HBM 밸류체인(한미반도체 등)이 이미 거대한 멀티플을 받아 시장의 눈높이가 하늘 높이 가 있다면, 엔지니어님께서 무대 뒤의 핵심 열쇠로 짚어주신 CXL(Compute Express Link)과 메모리 풀링(CMM) 생태계는 이제 막 실적의 숫자가 찍히기 시작하는 ‘무릎’ 단계의 블루오션입니다.
HBM이 도로의 속도(대역폭)를 극한으로 올리는 기술이라면, CXL은 PCIe 인터페이스 슬롯을 활용해 서버의 메모리 용량을 테라바이트(TB) 단위로 유연하게 확장하고 공유하는 ‘용량과 자원 효율화’의 기술입니다. 가 비싼 GPU의 연산 부담을 메모리가 나누어 갖는 CMM-Ax 아키텍처는 데이터센터의 TCO(총소유비용)를 극적으로 낮출 수 있어 빅테크들이 목을 매고 있는 영역입니다.
CXL 밸류체인의 단기·중장기 투자 스크린을 낱낱이 파헤쳐 드리겠습니다.
❶ 네오셈(253590): CXL 테스터 시장의 글로벌 독점적 지위
“세계 최초 CXL 2.0 테스터 개발 완료 및 3.0/3.1 상용화의 최대 수혜주”
📊 투자 분석 (단기 주도주 & 중장기 실적주)
동사는 SSD 검증 장비 세계 1위 기업이자, CXL 상용화 가시성에서 가장 앞서 있는 명실상부한 대장주입니다. 삼성이 컴퓨텍스 2026에서 CXL 기반 CMM 라인업을 대거 쏟아내면서, 이 제품들을 전수 검사해야 하는 네오셈의 ‘CXL Gen5 테스터 장비’ 수주가 올해 하반기부터 실적으로 직결됩니다.
🎯 투자자 체크포인트
CXL 3.0/3.1 프로토콜로 전환될수록 고주파 신호 무결성(Signal Integrity) 테스트의 난이도가 기하급수적으로 올라갑니다. 글로벌 메모리 제조사 두 곳(삼성전자, SK하이닉스)을 모두 핵심 고객사로 두고 있어, 두 거인의 CXL 주도권 싸움에서 ‘누가 이기든 무조건 돈을 버는’ 가장 편안한 포지션에 있습니다.
❷ 엑시콘(092870): 삼성전자 핵심 파트너, 차세대 CXL 3.0 테스터 국산화
“삼성의 ‘턴키(Turn-key)’ 공세에 발맞춘 하드웨어 검증 동반자”
📊 투자 분석 (단기 모멘텀 및 가파른 턴어라운드)
삼성전자가 주도하는 CXL 컨소시엄의 핵심 협력사입니다. 메모리 내부에 연산 기능을 넣은 CMM-Ax 같은 차세대 지능형 메모리를 테스트하기 위해서는 컴포넌트 레벨의 고성능 테스터가 필수적인데, 동사가 이 국산화 밸류체인의 최전선에 서 있습니다.
🎯 투자자 체크포인트
그간 전방 산업의 디램(DRAM) 업황에 따라 실적 변동성이 컸으나, CXL 테스터 매출이 본격적으로 가세하는 2026년 하반기를 기점으로 이익 체력이 한 단계 레벨업(Re-rating)될 가능성이 매우 높습니다. 기술 난이도가 높은 차세대 3.0 스펙 장비의 샘플 공급 소식이 나올 때마다 강력한 단기 주가 촉매로 작용할 것입니다.
❸ 에이직랜드(445090) / 오픈엣지테크놀로지(394280): CXL 컨트롤러 및 IP의 심장
“TSMC 파운드리와 국내 메모리 생태계를 잇는 CXL 디자인하우스 및 IP 제왕”
📊 투자 분석 (중장기 성장의 핵심, Buy & Accumulate)
엔지니어님께서 “HBM4부터는 베이스 다이를 TSMC 파운드리 공정으로 제작하며 TSMC-하이닉스 동맹이 강해질 것”이라 간파하셨습니다. 바로 이 지점에서 에이직랜드의 가치가 폭발합니다. 동사는 국내 유일의 TSMC VCA(공식 가치사슬 협력사, 디자인하우스)입니다. 국내 팹리스나 메모리사가 CXL 컨트롤러 칩을 TSMC 공정을 통해 맞춤형으로 깎을 때 반드시 거쳐야 하는 관문입니다.
🎯 투자자 체크포인트
오픈엣지테크놀로지는 CXL 호스트와 메모리 간의 초고속 데이터 전송을 제어하는 CXL PHY 및 컨트롤러 IP를 자체 보유한 기업입니다. 기술적 진입장벽이 가장 높은 ‘설계 자산’ 영역을 담당하므로, 중장기적으로 CXL 시장이 성숙기에 접어들 때 러닝 로열티(Royalty) 구조로 매출 마진율이 극대화되는 매력적인 비즈니스 모델을 가졌습니다. 주가가 눌릴 때마다 수량을 모아가는 장기 적립식 투자가 유효합니다.
❹ 티엘비(356860): CXL 전용 고다층 기판(PCB)의 표준 선점
“DDR5 기반 CUDIMM 및 CXL 모듈용 High-layer 기판의 숨은 강자”
📊 투자 분석 (중장기 안정적 캐시카우)
CXL은 기존 메인보드의 PCIe 슬롯에 꽂히는 구조이기 때문에, 기판 자체의 적층 구조와 신호 왜곡을 막는 소재 기술이 완전히 달라집니다. 동사는 국내 최초로 CXL용 대용량 고다층 기판 개발에 성공하여 샘플을 공급 중입니다.
🎯 투자자 체크포인트
컴퓨텍스에서 언급된 PC용 CUDIMM(클럭 버퍼 내장 메모리)의 도입과 서버용 CXL 확산은 동사에게 쌍두마차 호재입니다. 메모리 폼팩터가 바뀔 때마다 기판의 판가(P)가 20~30% 이상 격상되므로, 변동성 리스크가 적으면서 안정적인 실적 성장을 바라는 보수적 자산가들에게 훌륭한 대안적 포트폴리오가 될 것입니다.
5. 리스크 매트릭스 및 투자자 가이드라인
현직 엔지니어님의 날카로운 아키텍처 경고령을 기반으로, 투자자가 자산을 지키기 위해 반드시 상시 모니터링해야 할 3대 리스크 매트릭스를 구성했습니다.
리스크 요인
핵심 모니터링 포인트
투자 대응 전략
인텔 18A 공정 수율 불확실성
PowerVia(후면 전력 공급) 및 RibbonFET 안정화 속도
인텔 파운드리 부문의 분기별 흑자 전환 시점 확인 전까지는 인텔 본주에 대한 접근은 보수적으로 제한. 반대로 인텔 가치사슬 내 국내 I/O 부품 벤더의 단기 모멘텀만 취하는 전략.
액체 냉각(Liquid Cooling) 표준화 지연
데이터센터 내 CPO(광집적 패키징) 및 액체 냉각 인프라 도입 속도
엔비디아 루빈 랙 인프라 도입 스케줄에 맞춰 국내 냉각 공조 솔루션 관련주(매니폴드, 퀵커넥터 기술 보유사)의 특허 및 공급 계약 체결 여부 선제 선점.
Wintel 해체에 따른 단기 변동성
RTX Spark 탑재 노트북의 2026년 하반기 실제 출하량 지표
x86 진영과 Arm 진영의 점유율 싸움 속에서, 어느 쪽이 이기든 필수적으로 들어가는 ‘대용량 통합 메모리(CUDIMM)’ 및 ‘울트라 슬림 OLED 패널’ 제공사로 자산 헤징(Hedging).
6. 결론
“글로벌 빅테크들이 ‘AI 에이전트’라는 화려한 신기루의 지도(소프트웨어)를 그릴 때, 자본 시장의 진짜 부는 그 지도를 따라 실제 도로를 닦고 콘크리트를 붓는 한국의 고하이엔드 후공정 장비 및 CXL 가치사슬로 부드럽게 흘러 들어오고 있습니다. 무대 위 젠슨 황의 화려한 프레젠테이션 뒤에 숨겨진 국내 필수재 기업들의 ‘가격 결정권’에 베팅하십시오.”
HBM에서 소외되었던 자본이 CXL과 이종 집적 패키징이라는 새로운 탈출구를 찾고 있는 지금이 가장 외롭고도 뜨거운 기회입니다.
💡 투자 시야를 더 넓혀줄 기술 검증 노트
이번 컴퓨텍스 2026에서 한국 반도체 생태계의 주도권 변화를 이해하는 데 결정적인 도움을 주는 현장 분석 영상을 공유합니다. 엔비디아 기조연설의 이면에 숨겨진 HBM4 수급 가이드라인과 글로벌 빅테크들의 물량 확보전 흐름을 아주 쉽게 정리해 줍니다.
최근 HBM(고대역폭 메모리) 시장의 기술 전환 속도는 가장 역동적입니다. AI 반도체 시장이 폭발하면서 메모리는 더 이상 단순한 ‘저장소’가 아니라 전체 시스템의 성능을 결정짓는 ‘핵심 열쇠’가 되었습니다.
최근 시장에서 가장 뜨거운 화두인 HBM4(6세대)와 HBM4E(7세대)는 단순히 세대 이름만 바뀐 마이너 업그레이드 수준이 아닙니다. 이것은 반도체 미세공정의 물리적 한계와 패키징 패러다임의 전면적인 대전환을 담고 있는 거대한 기술적 변곡점입니다. 특히 최근 삼성전자가 2026년 5월 업계 최초로 성공시킨 4나노 베이스 다이 기반 HBM4E 12단 샘플 출하 소식은 시장의 판도를 단숨에 뒤흔드는 메가톤급 이벤트입니다.
오늘 포스팅에서는 현업 엔지니어의 날카로운 기술적 시각과 으로 HBM4/4E의 구조적 차이, 극악의 공정 난이도, 삼성전자의 독보적인 신공법, 그리고 국내외 핵심 밸류체인 기업들의 투자 향방까지 단 한 글자도 놓칠 수 없는 깊이 있는 분석을 전해드립니다.
1. HBM4 vs HBM4E 기술적 핵심 차이와 대격변
기존 HBM3E까지의 패니그라피(Planography) 구조에서는 D램을 얼마나 안정적으로 많이 쌓아 올리느냐에 모든 역량이 집중되었습니다. 그러나 HBM4 세대부터는 칩의 패러다임 자체가 완전히 바뀝니다. AI 가속기(GPU, ASIC 등)와 최하단에서 직접 맞닿아 두뇌 역할을 보조하는 ‘베이스 다이(Base Die, 혹은 로직 다이)’ 설계가 기존의 D램 공정에서 파운드리 선단 공정으로 전환되는 대격변이 일어났기 때문입니다.
HBM4와 HBM4E는 이 강력한 파운드리 베이스 다이 체제 위에서 성능과 용량을 극대화한 구조적 차이를 가집니다. 두 제품의 핵심 사양을 직관적으로 비교해 드리겠습니다.
HBM4 vs HBM4E 기술 사양 비교
항목
HBM4 (6세대)
HBM4E (7세대)
인터페이스 대역폭
2,048-bit (HBM3E 대비 2배 확장)
2,048-bit 기반 최적화 및 속도 향상
핀당 데이터 전송 속도
최대 10~14 Gbps 수준
최대 16 Gbps 구현
단일 스택 최대 대역폭
초당 약 2.5TB ~ 3.0TB
초당 최대 3.6TB
용량 (12단 / 16단)
36GB / 48GB
48GB (12단) / 최대 64GB (16단)
적용 D램 미세공정
1c D램 (10나노급 6세대)
1c D램 기반 고밀도 설계 및 최적화
베이스 다이 공정
파운드리 4나노 (4nm) 공정 적용
파운드리 4나노 공정 고도화 및 저전력 설계
HBM4: ‘규격의 대전환’을 이룬 6세대 이정표
HBM4는 베이스 다이를 4나노 파운드리 선단 공정으로 전면 교체하고, 데이터를 주고받는 입출력(I/O) 통로인 인터페이스 폭을 기존 1,024-bit에서 2,048-bit로 정확히 2배 확장한 모델입니다. 도로의 차선이 2배로 넓어진 것과 같으므로, 데이터 병목 현상을 근본적으로 해결하는 구조적 초석이 됩니다.
HBM4E: 극한의 성능을 쥐어짜 낸 7세대 마스터피스
HBM4E는 안정화된 4나노 베이스 다이 생태계 위에서 내부 아키텍처를 극단적으로 튜닝한 확장형(Extended) 모델입니다. 핀당 속도를 무려 16Gbps까지 끌어올려 단일 스택 기준 초당 3.6TB라는 경이로운 대역폭을 완성했습니다.
특히 용량 측면에서의 도약이 압도적입니다. 초고밀도 설계를 통해 12단 적층만으로 기존 16단 수준인 48GB를 구현해 냈으며, 향후 등장할 16단 구조에서는 단일 패키지 기준 64GB라는 초대형 용량을 확보하게 됩니다. 이는 LLM(거대언어모델)을 구동하는 초거대 AI 데이터센터 인프라의 가동 효율을 극대화하는 핵심 스펙입니다.
2. 공정 난이도 분석: 왜 지옥의 레이스인가?
엔지니어 관점에서 HBM4와 HBM4E 공정이 ‘지옥의 레이스’라고 불리는 이유는 반도체 물리학이 허용하는 마지막 임계 영역에 도달했기 때문입니다. 제조사들은 크게 두 가지 거대한 기술적 장벽과 마주하고 있습니다.
① ‘두께의 한계’와 물리적 제어 (Warpage 문제)
국제반도체표준협협기구(JEDEC)의 표준 규격에 따르면, HBM 패키지 전체의 두께는 720㎛(마이크로미터) 이하로 엄격히 제한됩니다. 기존 HBM3E 8단이나 12단을 쌓을 때와 동일한 두께 규격 안에 HBM4/4E 공정에서는 12단, 나아가 16단의 D램을 구겨 넣어야 합니다.
이를 위해서는 단일 D램 칩의 두께를 수십 마이크로미터 수준으로 가공해야 합니다. 칩이 머리카락보다 얇아질 정도로 극단적으로 깎여 나가기 때문에 다음과 같은 치명적인 문제가 발생합니다.
Warpage, 휨 현상: 열팽창 계수 차이로 인해 웨이퍼와 칩이 종잇장처럼 휘어지는 현상이 극대화됩니다.
패턴 뒤틀림: 칩이 휘어지면서 수천 개의 미세 통로 위치가 뒤틀려 상하층 칩의 회로가 서로 어긋나는 불량이 속출합니다.
② 열 방출과 CMP(화학기계적 연마)의 한계
칩의 두께가 얇아지고 적층 수가 늘어나 밀도가 한계까지 치솟으면 발열 제어는 불가능에 가까워집니다. 전력 소비가 집중되는 베이스 다이 위에 D램 16층이 촘촘히 얹히면 내부에서 발생한 열이 외부로 빠져나가지 못하고 갇히게 됩니다. 이는 결국 소자의 신뢰성을 파괴하고 시스템을 멈추게 하는 서멀 스로틀링(Thermal Throttling) 현상으로 직결됩니다.
또한, 16단 이상의 구조에서는 기존의 미세 돌기(마이크로 범프) 방식으로 칩을 연결하는 데 한계가 있어, 칩과 칩의 구리(Cu) 패드를 분자 결합 수준으로 완전히 밀착시키는 하이브리드 본딩(Hybrid Bonding) 기술이 필수적으로 요구됩니다. 이 하이브리드 본딩을 성공시키려면 접합 표면의 평탄도가 원자 단위 수준으로 매끄러워야 합니다. 하지만 기존의 물리·화학적 연마 방식인 CMP(Chemical Mechanical Planarization) 공정은 이미 미세화의 물리적 한계치에 다다라 수율 확보의 거대한 걸림돌이 되어 왔습니다.
3. 삼성전자가 성공한 핵심 공법 분석
이러한 지옥 같은 난이도 속에서 삼성전자는 시장의 우려를 불식시키고 판도를 바꾸는 승부수를 던졌습니다. 바로 “원스톱 메모리-파운드리 융합 전략”과 “습식 ALE 공법을 통한 패키징 기술 혁신”입니다. 이 독창적인 돌파구를 통해 최근 세계 최초 HBM4E 12단 샘플 공급이라는 쾌거를 이루어냈습니다.
① ‘자체 4나노 베이스 다이’와 저전력 설계의 시너지 (IDM의 귀환)
경쟁사들이 설계 자산의 한계로 인해 베이스 다이 제조를 외부 파운드리(TSMC)에 전적으로 의존하는 구조적 약점을 가진 반면, 삼성전자는 세계 최고 수준의 메모리 기술(1c D램)과 파운드리 선단 공정(4나노)을 한 지붕 아래에서 동시에 수행할 수 있는 유일한 종합 반도체 기업(IDM)입니다.
삼성이 거둔 기술적 성과의 핵심은 다음과 같습니다.
전력 분배(Power Distribution) 아키텍처 최적화: 로직 다이 내부 전력 공급 선로를 혁신적으로 전면 재설계했습니다. 고부하 연산 시 특정 영역에 전력이 집중되어 발생하는 핫스폿(Hot-spot)을 근본적으로 분산했습니다.
에너지 효율 16% 개선: 최적화된 저전력 설계 덕분에 작동 전력을 전작 대비 16% 감축하는 데 성공했습니다.
열저항 특성 14% 이상 확보: 방열에 최적화된 내부 패키지 재료 기술과 설계를 접목하여, 12단·16단 구조에서도 스로틀링 없이 안정적으로 클럭을 유지할 수 있는 내구성을 확보했습니다.
② 신의 한 수: ALE(원자층 식각) 공법 도입을 통한 하이브리드 본딩 혁신
하이브리드 본딩 공정의 핵심은 구리(Cu) 전극 패드와 절연층(SiO2)의 표면 높이를 완벽하게 일치시키는 것입니다. 하지만 구리와 절연층은 물질의 단단함(경도)이 완전히 다릅니다. 이 때문에 기존처럼 기계적으로 문질러 깎아내는 CMP(연마) 공정에만 의존하면 심각한 부작용이 발생했습니다.
기존 CMP 공정의 고질적 한계: 디싱(Dishing) 현상
상대적으로 무른 구리 표면이 절연층보다 과도하게 파여 나가 밥그릇 모양으로 푹 꺼지는 디싱(Dishing) 현상이 발생합니다. 이 상태로 칩을 맞붙이면 구리 패드 사이에 미세한 빈틈(Void)이 생겨 전 신호가 끊기거나 접합 불량으로 이어져 초기 수율이 처참하게 무너집니다.
삼성전자는 연마 패드로 갈아내는 기계적 공정의 의존도를 획기적으로 낮추는 대신, 습식 ALE(Atomic Layer Etching, 원자층 식각) 기술을 세계 최초로 패키징 공정에 전면 도입하는 정면 돌파를 선택했습니다.
이 ALE 공법 도입이 반도체 패키징 역사에 남을 혁신인 이유는 세 가지입니다.
절연층 데미지 원천 차단: 거친 기계적 연마를 최소화하므로 연약한 초미세 절연막이 깨지거나 긁히는 손상을 완벽하게 방지합니다.
완벽한 표면 거칠기(Roughness) 제어: 구리 패드의 단면을 나노미터 단위 이하의 평탄도로 매끄럽게 다듬어 균일한 접합면을 형성합니다.
수율 확보와 소모품 비용 절감: 디싱 현상이 사라지며 하이브리드 본딩의 최대 약점이었던 접합 불량률을 획기적으로 낮추었습니다. 동시에 값비싼 초미세 연마 패드와 특수 슬러리(Slurry) 등 CMP 소모품 비용을 대폭 아낄 수 있게 되었습니다.
4. 자산운용가 관점: 돈의 흐름(Capital Flow)과 수혜 밸류체인 분석
투자자 관점에서 이 기술적 도약은 단순한 공학적 성과를 넘어, 수조 원의 자금이 어디로 이동할지 알려주는 완벽한 이정표입니다. 삼성전자의 HBM4E 12단 샘플 출하 및 합산 시가총액의 역사적 재평가는 시장의 주도권이 어디로 이동하고 있는지 명확히 보여줍니다.
① 삼성전자의 턴키(Turn-key) 역량 재평가
과거 HBM3E 시장에서 삼성전자가 고전했던 근본 원인은 수율 저하와 발열 제어 실패였습니다. 그러나 HBM4 세대부터 게임의 룰은 패키징 공정 단독 레이스에서 ‘파운드리 선단 공정과 설계 능력의 결합’으로 완전히 이동했습니다.
SK하이닉스는 HBM4용 베이스 다이를 제조하기 위해 대만 TSMC라는 외부 파운드리를 반드시 거쳐야 합니다. 이는 필연적으로 외주 가공 비용 증가와 지정학적 공급망 리스크(Geopolitical Risk)에 노출됨을 의미합니다. 반면 삼성전자는 자체 선단 파운드리를 가동하므로 공급 안정성과 마진율(OPM) 측면에서 비교할 수 없는 우위를 점하게 됩니다. 이번 HBM4E 샘플 출하 성공으로 양산성까지 검증되었으니, 메모리 패권 탈환은 시간문제입니다.
② ALE(원자층 식각) 도입이 가져올 장비 패러다임 변화
삼성의 “CMP 의존도 축소 및 ALE 도입”은 반도체 장비 생태계의 판도를 완전히 바꿉니다. 하이브리드 본딩 시대로 진입하면서 전통 후공정의 핵심이었던 와이어 본딩, 일반 리플로우, 전통 다이싱 장비의 투자 매력도는 정체될 것입니다. 반면, 원자 단위 제어가 가능한 전공정 개념의 식각/증착 장비와 초미세 검사 장비사들의 가치는 폭등할 수밖에 없습니다.
5. 수혜 기업 심층 분석 (Value Chain Search)
삼성전자의 HBM4E 독주 체제 및 ALE 기반 하이브리드 본딩 도입으로 직접적인 수혜를 입으며 대규모 낙수효과를 누릴 국내 핵심 기업들을 선별했습니다.
국산화 및 기술 패러다임 수혜 핵심 밸류체인
기업명 (종목코드)
관련 핵심 포트폴리오
투자자 관점 관전 포인트
삼성전자 (005930)
• HBM4/4E 자체 턴키 생산 • 세계 최초 HBM4E 12단 출하
• 대형주 Top-Pick. HBM 시장 패권 탈환 및 4나노 파운드리 가동률 상승 동시 수혜. • 엔비디아의 차세대 ‘베라 루빈 울트라(Vera Rubin Ultra)’ 탑재 가시화로 멀티플 재평가 진행 중.
원익IPS (032940)
• 반도체 증착 및 식각(Etch) 장비 제조 • 원자층 증착(ALD)/식각(ALE) 국산화 선두
• 삼성이 물리적 CMP 공정 비중을 줄이고 화학적·원자층 제어(ALE) 공정을 전면 확대할 때 가장 먼저 손을 잡는 독점적 전공정 파트너. • 기술 세대교체에 따른 장비 공급 단가(ASP) 상승 수혜 집중.
가온칩스 (394280)
• 파운드리 디자인하우스 (DSP) • 4나노 베이스 다이 설계 자산(IP) 관리
• 맞춤형(Custom) HBM4 시대에는 글로벌 빅테크(GPU 설계사)와 메모리 제조사 간의 미세 구조를 조율하는 디자인하우스의 역할이 필수적임. • 삼성 파운드리 4나노 생태계의 고성능 칩 수주 확대의 직접적 수혜주.
HPSP (403870)
• 고압 수소 어닐링 장비 • 미세 공정 계면 결함 제어 고압 장비
• 1c D램 미세화 및 4나노 베이스 다이의 초미세 트랜지스터 계면 결함을 치유하는 독점 장비 보유. • 하이브리드 본딩 시 구리-구리 접합부의 물리적 안정성을 극대화하는 열처리 공정에도 장비가 연결될 소지 다분.
6. SK하이닉스 vs 마이크론: 반격의 무기와 생태계 전략
삼성전자가 강력한 반격의 포문을 열었다고 해서, 지금까지 시장을 지배해 온 SK하이닉스가 무력하게 무너지거나 미국 정부의 전폭적인 지원을 받는 마이크론이 도태되지는 않을 것입니다. HBM4/4E 시대는 한 기업이 시장을 독식하기에는 AI 가속기 전체 시장의 파이 자체가 상상을 초월할 정도로 거대해졌기 때문입니다. 그들의 방어 전략과 밸류체인도 명확히 분석해야 균형 잡힌 투자가 가능합니다.
① SK하이닉스 (000660): “어제의 맹주, ‘TSMC-엔비디아 삼각동맹’의 저력”
SK하이닉스는 HBM3/3E 시장을 선점하며 쌓아 올린 탄탄한 현금 동원력과 굳건한 고객사 신뢰를 무기로 삼습니다. 비록 삼성의 4나노 선제공격에 일격을 당했지만, 그들에게는 ‘에코시스템(생태계) 동맹’이라는 강력한 카드가 있습니다.
TSMC와의 원팀(One-Team) 플레이: 하이닉스는 HBM4 베이스 다이 생산을 TSMC의 5나노/4나노 선단 공정에 전량 위탁합니다. TSMC 파운드리의 신뢰성과 엔비디아 GPU 패키징(CoWoS) 공정과의 정합성은 이미 완벽하게 검증되어 있습니다. 맞춤형(Custom) HBM의 세부 커스터마이징 영역에서는 이 연합군의 최적화 속도가 뛰어난 효율을 발휘할 수 있습니다.
어드밴스드 MR-MUF의 연장선: 하이닉스는 하이브리드 본딩으로 직행하기 전, 기존에 강점을 가졌던 액체 형태의 보호재를 주입하는 MR-MUF 공정을 극한으로 고도화하여 16단 적층까지 구현하는 투트랙 전략을 취하고 있습니다. 검증된 공정이기에 초기 양산 안정성 측면에서 리스크를 분산하는 효과가 있습니다.
⚠️ SK하이닉스계 진영 투자자 유의점
하이닉스 HBM 성장의 일등공신인 한미반도체(042700, 듀얼 TC 본더 공급사)와 피에스케이홀딩스(031980, 리플로우 및 디스컴 장비 강자)는 여전히 견고한 실적을 낼 것입니다. 다만, 시장의 장기 패러다임이 하이브리드 본딩과 ALE 공정으로 넘어가는 속도가 빨라질수록, 전통적 본딩 장비사들의 밸류에이션(멀티플) 둔화 압력은 감내해야 합니다.
② 마이크론 테크놀로지 (MU): “미국 헤게모니의 최대 수혜자, 지정학적 치트키”
마이크론은 미국의 반도체 자국주의(CHIPS Act) 보조금 수혜를 가장 크게 입으며 빅테크 기업들의 러브콜을 한 몸에 받고 있습니다.
지정학적 다변화(Dual-Sourcing) 수혜: 엔비디아를 비롯한 빅테크(CSP) 기업들 입장에서 지정학적 리스크가 있는 아시아(한국, 대만) 외에 미국 본토에 거점을 둔 메모리 공급선은 대안이 없는 필수 선택지입니다. 기술 완성도가 다소 밀리더라도 일정 수준의 대규모 물량을 보장받는 독점적 구조 속에 있습니다.
공정 건너뛰기의 명암: 마이크론은 1b 공정을 건너뛰고 HBM4부터 바로 1c D램 미세공정을 도입하겠다는 공격적인 로드맵을 제시했습니다. 성공 시 단숨에 격차를 좁히지만, 대만 파운드리에 베이스 다이를 위탁하는 구조적 복잡성 때문에 초기 수율 확보에 상당한 진통을 겪을 가능성이 큽니다. 리스크 테이킹 성향의 투자자라면 이오테크닉스(039030, 레이저 다이싱 장비)나 유진테크(084370, 전공정 ALD 장비) 등 마이크론 미세화 투자 낙수 기업 위주로 접근하는 것이 현명합니다.
7. 30년차 애널리스트의 최종 투자 의견 및 포트폴리오 전략
“단기적으로는 모멘텀 플레이, 중장기적으로는 기술 패러다임 전환(Shift)에 지갑을 열어라.”
현재 HBM 시장은 ‘삼성전자의 기술 혁신을 통한 대반격’, ‘SK하이닉스의 삼각 동맹을 통한 영토 수성’, ‘마이크론의 미국 퍼스트 기반 정치적 수혜’가 얽힌 거대한 삼국지입니다. 투자자는 한쪽에만 맹목적으로 올인하기보다, 철저하게 기술적 비교우위와 시장의 자금 이동 경로에 맞춰 포트폴리오를 구성해야 합니다.
HBM 삼국지 시대의 투자 전략 가이드
단기적 관점 (6개월 ~ 1년): 삼성전자 중심 비중 확대삼성전자의 HBM4E 12단 샘플 출하는 시장의 모든 의구심을 날려버리는 강력한 트리거입니다. 엔비디아의 차세대 초고성능 가속기 라인업인 ‘베라 루빈(Vera Rubin)’ 시리즈의 타임라인에 삼성이 가장 정교하게 맞물려 들어가고 있습니다. 주가가 단기 조정을 받을 때마다 삼성전자를 포트폴리오의 가장 든든한 축으로 적극 편입하는 전략이 유효합니다.
중장기적 관점 (3년 이상): 후공정의 전공정화(Middle-end)에 베팅하이브리드 본딩과 ALE(원자층 식각)의 도입은 후공정 패키징을 사실상 초미세 전공정 영역으로 흡수시켰습니다. 과거 HBM3E 단순 수혜주로 묶였던 리플로우나 일반 범핑 기업의 비중을 낮추십시오. 대신 원자층 수준의 제어력을 가진 전공정 식각/증착 장비사(원익IPS 등)와 파운드리 생태계 디자인하우스로 무게중심을 이동하는 ‘구조적 전환’을 지금부터 단호하게 실행해야 합니다.
반도체 시장에서 영원한 승자도, 영원한 패자도 없습니다. 삼성이 종합반도체기업(IDM)의 강력한 시너지와 ALE 공법이라는 확실한 기술적 무기를 들고나온 만큼, 이번 반등 사이클은 과거 그 어떤 턴어라운드보다 깊고 길게 전개될 것입니다. 확신을 가지고 자산을 재편하셔도 좋은 타이밍입니다.
인공지능(AI)과 거대언어모델(LLM)의 폭발적인 성장은 글로벌 데이터센터의 인프라와 반도체 아키텍처를 근본적으로 재정의하고 있습니다. 엔비디아(NVIDIA)를 필두로 한 빅테크 진영이 초거대 AI 연산 수요를 감당하기 위해 더욱 강력한 GPU를 출시함에 따라, 이에 동반되는 고대역폭 메모리(HBM)의 성능 고도화 압박 역시 물리적 한계점까지 밀어쳐지고 있습니다.
과정에서 직면한 가장 거대한 장벽은 다름 아닌 ‘발열(Heat Generation)’입니다. 3차원 초고적층 구조를 취하는 HBM 특성상, 내부에서 발생하는 열을 제때 배출하지 못하면 시스템 전체가 멈추는 써멀 스로틀링(Thermal Throttling)이 발생합니다.
이러한 상황에서 SK하이닉스가 발표한 iHBM(Integrated HBM) 기술은 단순한 냉각 솔루션의 추가가 아니라, 메모리 아키텍처의 패러다임을 바꿀 파괴적 혁신으로 평가받고 있습니다. 이 혁신 기술의 본질을 바닥까지 긁어 분석해 드리겠습니다.
1. AI 반도체의 아킬레스건, ‘발열 문제’의 핵심 범인을 검거하다
1.1. 흔한 오해: 원인은 코어 다이(DRAM)의 적층 두께가 아니다
대다수의 비전문가용 기술 매뉴얼이나 보도자료에서는 HBM의 열 문제를 “DRAM을 8단, 12단, 16단으로 높게 쌓아 올리면서 패키지 전체가 두꺼워져 열이 갇히기 때문”이라고 설명합니다. 하지만 실제 반도체 패키징 내부를 정밀 스캔하고 전력 거동을 관찰해 보면 진정한 열적 지옥(Hot-Spot)은 상부의 코어 다이가 아닙니다.
진짜 범인은 최하단에서 두뇌 역할을 하는 베이스 다이(Base Die 또는 로직 다이) 내부에 위치한 D2D PHY(Die-to-Die Physical Layer, 물리 계층 고속 인터페이스) 구간입니다.
1.2. D2D PHY 구간이 ‘용광로’가 되는 물리적 이유
D2D PHY 영역은 GPU와 HBM 간에 초당 수 테라바이트(TB/s)의 초고속 데이터를 지연 시간(Latency) 없이 전송하기 위해 미세 회로와 수천 개의 관통 전극(TSV) 전송 패드가 극도로 밀집된 공간입니다. 반도체 소자가 고속으로 온/오프(1과 0) 스위칭 운동을 할 때 발생하는 동적 소모 전력(P) 공식은 다음과 같습니다.
AI 연산 속도를 가속하기 위해 동작 주파수(f)를 기하급수적으로 끌어올림에 따라, 이 좁은 D2D PHY 구간에서 소모되는 전력이 폭발적으로 증가하며 이는 고스란히 고주파 열에너지로 치환됩니다. 마치 대도시의 수많은 지하철 노선이 교차하는 환승역에 병목 현상이 발생하고 인파의 열기로 가득 차는 것과 같은 이치입니다.
1.3. 기존 HBM 구조의 한계와 써멀 스로틀링의 악순환
기존의 HBM 아키텍처에서는 이 불덩어리 같은 PHY 영역에서 발생한 열이 상부의 얇게 갈아낸 DRAM 코어 다이들을 순차적으로 타고 올라가, 패키지 맨 위에 부착된 열 계면 재료(TIM)와 방열판(Heat Sink)을 통해 외부로 배출되는 방식을 취했습니다.
하지만 고온의 열이 수직으로 전달되는 과정에서 상부 DRAM 셀들의 캐패시터 전하 누설(Leakage Current)을 유발합니다. 데이터 유실을 막기 위해 메모리는 리프레시(Refresh) 주기를 강제로 단축해야만 하고, 이는 메모리 본연의 읽기/쓰기 효율을 저하시켜 결국 시스템 전체 성능이 급하강하는 써멀 스로틀링의 악순환을 낳았습니다.
2. iHBM 아키텍처의 핵심: ICE(Integrated Cooling Elements) 메커니즘 심층 분석
SK하이닉스가 고안해 낸 iHBM 아키텍처의 본질은 발열의 근원지인 D2D PHY 영역 바로 옆과 상부 코어 다이로 향하는 길목에 물리적인 ‘일체형 냉각 요소(ICE: Integrated Cooling Elements)’를 다이렉트로 이식하는 것입니다.
2.1. 재료공학적 혁신: 더미 실리콘(Dummy Silicon)의 묘미
ICE 소자의 핵심은 재료의 선택에 있습니다. SK하이닉스는 전기가 통하지 않는 전기적 부도체(절연체)이면서도, 일반적인 에폭시 수지 보호재보다 열전도율이 수십 배 이상 높은 고순도 실리콘 소자(Dummy Silicon)를 채택했습니다.
전기가 통하지 않기 때문에 미세 회로가 밀집된 인터페이스 바로 옆에 붙여도 신호선 간의 전자기적 간섭이나 크로스토크(Cross-Talk, 신호 왜곡)를 유발하지 않습니다. 그러면서도 열은 기가 막히게 흡수하는 구조적 스펀지 역할을 수행합니다.
2.2. 우회로가 아닌 직통 ‘열 고속도로’ 형성
기존 구조가 열을 위로 밀어 올리는 방식이었다면, iHBM의 ICE는 열이 상부의 민감한 DRAM 셀로 이동하기 전에 중간에서 열을 선제적으로 가로채는 ‘차단벽(Thermal Barrier)’ 역할을 합니다.
이렇게 흡수된 열은 ICE 소자를 타고 패키지 측면의 몰딩재 및 하부의 볼 그리드 어레이(BGA) 기판 유기물 방향으로 전방위 분산·배출됩니다. 패키지 내부에 가로, 세로 형태로 ‘열 전용 직통 고속도로’를 개통한 것과 같습니다.
2.3. 열저항($R_{th}$) 30% 감소가 갖는 엔지니어링적 대전환
반도체 패키징 공학에서 열저항(R_th, Thermal Resistance)이란 “열이 외부로 빠져나가는 길에 놓인 물리적 장애물의 크기”를 의미하며 단위는 ‘섭씨/와트’를 사용합니다. 즉, 1와트의 전력을 소비할 때 온도가 몇 도나 상승하는지를 나타내는 지표입니다. iHBM이 검증해 낸 ‘열저항 30% 이상 감소’는 엔지니어 관점에서 경이적인 수치입니다.
이 구조적 혁신을 통해 동일한 전력을 소모하더라도 칩 내부의 온도 마진을 최소 10~ 15도씨 이상 추가로 확보할 수 있게 되었습니다. 이는 GPU가 풀 로드(Full Load)로 클럭을 쥐어짜며 초대형 AI 연산을 수행하더라도, HBM 메모리가 과열로 뻗는 타이밍을 엄청나게 뒤로 늦추거나 원천 차단할 수 있음을 뜻합니다. AI 데이터센터의 무중단 운영 신뢰성에 직결되는 핵심 지표입니다.
3. 제조 및 양산 관점의 대전환: MR-MUF 공정 인프라의 완벽한 재활용
아무리 실험실에서 훌륭한 냉각 아키텍처를 개발했다고 한들, 실제 거대한 팹(Fab) 라인에서 높은 수율(Yield)로 찍어낼 수 없거나 천문학적인 신규 설비투자(CAPEX)를 요구한다면 비즈니스 관점에서는 실패한 기술입니다. iHBM 기술이 무서운 진정한 이유는 SK하이닉스가 기존에 완성해 놓은 전용 후공정 생태계인 ‘어드밴스드 MR-MUF(Mass Reflow Molded Underfill)’ 인프라를 그대로 재활용할 수 있도록 설계되었다는 점입니다.
3.1. Advanced MR-MUF 공정과의 화학적·기계적 조화
경쟁사들이 칩 사이에 필름 형태의 방열재를 끼워 넣고 압착하는 NCF(Non-Conductive Film) 방식을 고수하며 수율과 발열 문제로 고전할 때, SK하이닉스는 액체 형태의 보호재를 주입해 미세 틈새를 완벽히 메우는 MR-MUF 기술로 시장을 평정했습니다. iHBM 제조 프로세스는 이 안정화된 라인에 소자 배치 기하학(Geometry)만 매끄럽게 융합했습니다.
마이크로 범프 본딩 (Micro-Bump Bonding): 최하단 베이스 다이 위의 D2D PHY 최적 영역에 일반 DRAM 다이와 함께 물리적 ICE 소자를 나노미터 단위의 오차로 정렬하여 임시 접합합니다.
매스 리플로우 (Mass Reflow): 거대한 컨베이어 오븐 장비 내에서 정밀하게 제어된 프로파일 온도를 가해, 수만 개의 마이크로 범프를 단 한 번의 공정으로 완벽하게 솔더링(Soldering) 인터커넥트합니다.
몰디드 언더필 (Molded Underfill) 주입: 에폭시 수지에 마이크로 실리카(수정 가루) 필러가 고밀도로 혼합된 액체 상태의 보호재(MUF)를 주입하여 칩 사이와 ICE 주위의 미세한 공극(Void)을 완벽히 메웁니다.
ICE 인터록킹 (Interlocking) 및 경화: 고온 고압에서 보호재를 굳히면 액체 수지가 ICE 소자의 물리적 표면과 강력하게 밀착되어, 기계적 지지대 역할과 열적 전도 네트워크가 결합된 일체형 패키지가 완성됩니다.
3.2. 부가적 이점: 휨 현상(Warpage) 제어와 구조적 안정성
기존 MR-MUF에 사용되는 보호재는 실리카 필러 함량이 높아 자체 열전도율도 우수한 편이지만, 중간 중간에 통실리콘 블록인 ICE가 결합되면서 패키지 내부의 기계적 강성(Mechanical Stiffness)이 극대화됩니다.
이는 HBM5 이상에서 적층 단수가 16단, 24단 이상으로 증가하고 다이 두께가 극도로 얇아질 때 발생하는 물리적 뒤틀림(Warpage) 현상을 억제하는 Stiffener(보강재) 역할을 수행합니다. 결과적으로 추가적인 장비 도입 없이 기존 라인의 가동률과 수율을 최고조로 유지하면서 신제품을 양산할 수 있는 원가 경쟁력을 확보하게 된 것입니다.
4. 거시적 자본시장 분석: 메모리 3사의 가치평가(Valuation)와 주도권 향방
자본시장의 흥망성쇠를 분석하는 애널리스트 관점에서 이번 SK하이닉스의 iHBM 로드맵 발표를 냉정하게 평가해 보겠습니다. 이번 이슈는 단순한 기술 격차의 확인이 아니라, 향후 3~5년간 빅테크 기업들의 자본지출(CAPEX)이 어느 기업의 SCM(공급망 관리)으로 흘러 들어갈 것인지를 결정짓는 거대한 분수령입니다.
4.1. SK하이닉스 (투자 의견: Buy & Hold) – 기술적 해자의 공고화
주식시장이 가장 좋아하는 것은 ‘예측 가능한 성장’과 ‘비용 효율성’입니다. SK하이닉스는 차세대 HBM5(8세대) 시장까지 관통하는 발열 제어 마일스톤을 선제적으로 공개함으로써, 엔비디아를 비롯한 글로벌 핵심 하이퍼스케일러 기업들에게 기술적 안정성에 대한 확신을 주었습니다.
특히 새로운 기계를 대거 사들이지 않고 기존 MR-MUF 라인을 재활용해 성능을 올리겠다는 선언은 중장기적으로 대규모 감가상각비 부담 없이 고마진 구조를 유지하겠다는 뜻입니다. 판가 결정권(Pricing Power)을 지속적으로 쥐고 가겠다는 선언과 다름없으며, 타사 대비 프리미엄 멀티플($P/E$) 부여를 정당화하는 핵심 근거입니다.
삼성전자는 메모리, 파운드리, 어드밴스드 패키징(AVP)을 원스톱으로 처리할 수 있는 전 세계 유일한 ‘턴키(Turn-Key) 솔루션’ 능력을 최대 무기로 삼고 있습니다. “하이닉스가 단품 메모리 내부(iHBM)에서 열을 아무리 잘 잡아도, 결국 전체 칩(GPU+HBM) 레벨에서의 열 관리와 수율은 파운드리와 패키징을 통으로 쥐고 있는 우리가 유리하다”는 논리로 빅테크를 설득해 왔습니다.
하지만 하이닉스가 메모리 단품 단에서 열을 30%나 줄여버리는 iHBM을 들고나오면서 삼성의 논리가 일부 무색해질 위험이 생겼습니다. 삼성전자가 이 판도를 뒤집기 위해서는 HBM4 베이스 다이 영역에서 TSMC-엔비디아 연합전선을 뒤흔들 수 있는 압도적인 수율을 보여주거나, 차세대 적층 기술인 ‘하이브리드 본딩(Hybrid Bonding)’을 경쟁사보다 완벽한 수율로 조기 양산 성공해야 합니다. 그 전까지는 철저히 공급 계약 승인 뉴스를 확인하고 진입하는 확인 매수 관점을 추천합니다.
4.3. 마이크론 (투자 의견: Neutral) – 캐파 한계와 추격의 난제
마이크론은 1-beta 공정 기반의 미세화 효율성을 무기로 HBM3E 시장에서 깜짝 존재감을 드러냈으나, 원천적인 후공정 패키징 아키텍처 설계 능력과 절대적인 생산능력(CAPEX 규모) 면에서 한국의 두 거인에 비해 열세에 놓여 있습니다. 미국 정부의 보조금 동력이 유지되더라도, 대만과 미국으로 이원화된 생산 라인의 물류 비용 부담과 규모의 경제 한계로 인해 중장기 표준 경쟁에서 독자적인 주도권을 쥐기에는 체력적 한계가 존재합니다.
5. SCM 공급망 대부해: iHBM 생태계 확장에 따른 국내 소부장 수혜주 진단
영리한 투자자라면 대형주 자체의 등락에만 매몰될 것이 아니라, 이러한 구조적 아키텍처 변화가 일어날 때 하부 SCM에서 어떤 정밀 장비와 특수 소재의 소요량($Q$)과 단가($P$)가 급증하는지를 면밀히 추적해야 합니다. iHBM 구조가 본격화될 때 주식시장에서 가장 확실한 실적 성장을 보여줄 핵심 벨류체인을 진단해 드립니다.
5.1. 신규 도입 벨류체인: ICE 배치용 초정밀 본딩 및 특수 절연 소재
기존 HBM 공정에 없던 물리적 실리콘 소자(ICE)를 베이스 다이 위에 서브 마이크론 단위의 오차로 안착시키고 적층하는 공정은 완전히 새로운 고난도의 테크놀로지 영역입니다.
한미반도체 (TC 본더 지배력의 다각화): 하이닉스 HBM 신화의 일등공신인 한미반도체의 열압착(Dual TC 본더) 장비는 iHBM 시대에 이르러 그 가치가 더욱 격상될 것입니다. 일반 DRAM 다이 외에 ICE 소자까지 함께 초고속으로 파킹하고 열과 압력을 제어해야 하므로, HBM 패키지 하나당 본더 장비의 소요 시간과 대수 자체가 늘어나는 효과($Q$의 증가)를 기대할 수 있습니다.
고열전도성 및 특수 소재사 (SKC, 솔브레인 등): 고순도 실리콘 기반의 ICE 소자를 정밀 정형 가공하는 기술과, D2D PHY의 미세 회로 간 전자기적 간섭을 차단하면서도 열전도율을 최대로 끌어올려야 하는 특수 박막 재료, 하이엔드 화학 물질의 수요가 폭증할 것입니다. 가치 사슬 내에서 마진율이 가장 높은 화학/소재 섹터의 낙수효과를 주목해야 합니다.
5.2. 공정 고도화 벨류체인: 전/후공정 레이저 및 열처리 인프라
열저항을 30% 줄이기 위해 다이의 두께를 극한으로 얇게 슬리밍하고 가공하는 과정에서 가해지는 물리적 스트레스를 제어하는 장비 진영 역시 강력한 수혜를 입게 됩니다.
에이치피에스피 (HPSP): 고압 수소 중성화 이온 어닐링 장비를 독점 공급하는 기업으로서, 다이가 얇아지고 계면의 열화 현상이 심해질수록 실리콘 표면의 물리적 결함을 치유하는 고압 수소 공정의 중요성은 기하급수적으로 증가합니다. iHBM 공정에서도 수율 방어를 위한 필수 장비로 자리매김할 것입니다.
이오테크닉스: 레이저를 활용해 웨이퍼를 초정밀 그루빙(Grooving)하고 다이싱(Dicing)하는 기술력을 보유하고 있어, 패키지 내부에 ICE 소자가 들어갈 자리를 미세하게 파내고 마감하는 후공정 레이저 장비 부문에서 뚜렷한 실적 모멘텀을 맞이할 확률이 높습니다.
6. 결론: 대전환기 자본시장에서 승리하는 포트폴리오 전략
SK하이닉스의 iHBM 기술은 단순한 ‘냉각 장치 추가’가 아니라, 폭발하는 AI 연산 아키텍처의 물리적 장벽을 가장 지혜롭고 경제적인 방식으로 정면 돌파해 낸 후공정의 승리입니다. 자본시장 측면에서 이 뉴스는 향후 HBM5 시대까지 SK하이닉스 진영의 공급망 주도권과 고마진 구조가 굳건하게 유지될 것임을 시사하는 명확한 시그널입니다.
따라서 현 시점에서의 현명한 자산 배분 전략은 명확합니다. 향후 1~2년의 단기적 관점에서는 승기를 완벽히 잡고 SCM 확장성까지 입증해 낸 SK하이닉스와 그 핵심 벨류체인(한미반도체, 고도화 소재 기업)에 포트폴리오의 무게중심을 실어 안전하고 확실한 알파 수익률을 추구하는 것이 정석입니다.
동시에, 삼성전자가 칼을 갈고 반격을 준비 중인 HBM4 베이스 다이 양산 시점과 하이브리드 본딩의 수율 안정화 뉴스(2026년 말~2027년 예상)를 철저히 모니터링하며, 삼성이 시장의 신뢰를 회복하는 ‘주가 턴어라운드 트리거’가 포착되는 순간 포트폴리오의 비중을 재조정하는 역발상 전략이 자본시장에서 가장 승률이 높은 싸움이 될 것입니다. 변화하는 기술의 본질을 꿰뚫어 보는 혜안만이 거대한 반도체 대전환기 속에서 당신의 자산을 지키고 불려줄 유일한 무기입니다.
이번에 공개된 구글 I/O 2026 발표를 지켜보면서, 저는 실로 가슴이 웅장해지는 것을 느꼈습니다. 엔지니어의 시각에서는 기술적 완성도가 임계점을 넘었다는 확신이 들었고, 애널리스트이자 투자자의 시각에서는 자본 시장의 거대한 자금 흐름(Money Move)이 어디로 요동칠지 지도가 선명하게 그려졌기 때문입니다.
과거의 인공지능이 우리가 던진 질문에 단순히 답만 하던 ‘수동적인 계산기’에 불과했다면, 2026년의 AI는 스스로 목표를 분석하고 계획을 세워 실행하는 ‘자율적인 동료(Agentic AI)’로 패러다임이 완전히 전환되었습니다. 그리고 구글은 이 거대한 소프트웨어 혁신을 뒷받침하기 위해 밑바닥 하드웨어 인프라부터 최상위 서비스 레이어까지 완벽하게 통제하는 ‘수직 계열화’를 완성해 냈습니다.
현업 엔지니어가 전율하고 자본 시장이 들썩이는 이 순간, 우리는 화려한 기술의 이면을 쪼개어 분석하고 이를 통해 단기적 모멘텀과 중장기적 밸류에이션 변화를 짚어내야 합니다. 그래야만 다가오는 AI 상용화 시대의 핵심 수혜주를 선점할 수 있습니다.
오늘 포스팅에서는 구글 I/O 2026에서 발표된 핵심 기술 구조를 엔지니어링 관점에서 아주 쉽게 풀어드리고, 이 기술들이 자극할 가치 사슬(Value Chain)과 투자 관점에서의 유망 기업 및 리스크까지 상세하게 해부해 드리겠습니다.
1. 차세대 AI 모델 아키텍처: 경량화와 멀티모달의 극한 체제
구글이 이번 발표에서 모델 라인업을 다각화한 것은 단순한 구색 맞추기가 아닙니다. 이는 서비스 운영 비용(OPEX)을 극적으로 절감하면서도 사용자 경험(UX)을 극대화하기 위한 철저한 아키텍처 최적화 전략의 결과물입니다.
[구글의 AI 모델 최적화 방향]
├─ 제미나이 3.5 플래시: 지식 증류 & 양자화 ➔ 추론 비용 절감 (OPEX 획기적 개선)
└─ 제미나이 옴니: 네이티브 엔드투엔드 ➔ 정보 손실 제로 & 초저지연 멀티모달 구현
① 제미나이 3.5 플래시 (Gemini 3.5 Flash) – 비용과 속도의 파괴적 혁신
엔지니어링 심층 분석: 제미나이 3.5 플래시의 핵심은 ‘지식 증류(Knowledge Distillation)’와 ‘양자화(Quantization)’ 기술이 정점에 달했다는 점입니다. 수천억 개의 거대한 파라미터를 가진 울트라(Ultra) 모델을 상용 서비스에 그대로 올리는 것은 비용적으로 불가능에 가깝습니다. 구글은 거대 모델이 가진 핵심 추론 능력과 지식 엑기스만 골라내어 가벼운 모델에 이식(지식 증류)했습니다. 여기에 연산 정밀도를 낮추는 양자화 기술을 적용했습니다. 예를 들어, 기존에 컴퓨터가 1개의 데이터를 처리할 때 쓰던 16비트 부동소수점($FP16$) 연산을 8비트 정수형($INT8$) 데이터 포맷으로 변환하는 방식입니다. 이렇게 되면 데이터의 크기가 절반으로 줄어들어, AI 반도체의 고질적인 문제인 메모리 대역폭 병목 현상을 물리적으로 해결할 수 있게 됩니다.
투자자가 봐야 할 본질 (왜 대단한가?): 연산 데이터가 가벼워지니 속도가 무려 4배 빨라졌습니다. 이는 서버가 사용자 요청을 받아 처리하는 ‘추론 대기 시간(Latency)’이 급감했음을 뜻합니다. 더 놀라운 것은 가격이 절반 이하로 떨어졌다는 점입니다. 과거에는 비용 부담 때문에 감히 시도하지 못했던 ‘수백만 토큰의 긴 문서를 실시간으로 분석하고, 쉬지 않고 스스로 생각하는 실시간 에이전트 루프’를 이제는 매우 저렴한 비용으로 상시 가동할 수 있게 되었습니다.
② 제미나이 옴니 (Gemini Omni) – 진정한 네이티브 멀티모달의 탄생
엔지니어링 심층 분석: 기존의 AI 서비스들은 무늬만 멀티모달인 경우가 많았습니다. 사용자가 말로 질문을 하면, [오디오 ➔ 텍스트 변환(STT)] ➔ [텍스트 모델 추론] ➔ [텍스트 ➔ 오디오 변환(TTS)]이라는 복잡한 중간 변환 과정을 거쳤습니다. 각기 다른 모델들이 따로 놀며 중간에서 데이터를 기계적으로 번역해 주다 보니, 지연 시간이 길어지고 문맥이 꼬였습니다. 반면, 제미나이 옴니는 중간 과정이 완전히 배제된 ‘네이티브 엔드투엔드 멀티모달(Native End-to-End Multimodal)’ 구조입니다. 비디오의 픽셀(Pixel) 데이터와 오디오의 주파수(Frequency) 데이터가 인풋 단계에서부터 하나의 거대한 신경망 안에서 동시에 토큰화(Tokenization)되어 융합 처리됩니다.
투자자가 봐야 할 본질 (왜 대단한가?): 중간 번역 과정이 없으니 데이터의 정보 손실이 제로(0)에 가깝습니다. 사용자의 목소리 톤에 담긴 미묘한 감정이나, 비디오 영상의 시각적 분위기를 AI가 왜곡 없이 그대로 흡수합니다. 영상의 분위기를 파악해 그에 완벽히 어울리는 효과음을 AI가 자율적으로 생성해 집어넣거나, 배경을 자연스럽게 바꾸는 ‘비디오 리믹스’ 기능이 버벅거림(지연 시간) 없이 실시간으로 작동할 수 있는 비결이 바로 이 일체형 아키텍처 덕분입니다.
2. ‘AI 에이전트’ 서비스: 단발성 질문 답변을 넘어 ‘자율적 워크플로우’로
그동안 AI 투자를 망설이게 했던 가장 큰 요인은 “그래서 이걸로 무슨 돈을 버는데?”라는 ‘킬러 서비스의 부재’였습니다. 구글은 이번 I/O 2026을 통해 AI가 일회성 대화(Single-turn)를 나누는 장난감이 아니라, 인간의 업무 프로세스를 대신 수행하는 ‘자율적 루프(Reasoning Loop)’ 시스템임을 명확히 했습니다.
구글이 제시한 AI 에이전트의 작동 메커니즘은 다음과 같은 고도의 워크플로우를 가집니다.
[사용자 명령]–>[목표 분석 및 계획 수립]–>[API/도구 호출]–>[결과 검증 및 수정]–>[최종 완료]
① 구글 검색 개편 & 제미나이 스파크 / 데일리 브리프
엔지니어링 심층 분석: AI 에이전트가 인간 대신 업무를 처리하려면 두 가지 기술적 전제가 필수적입니다. 바로 외부 시스템과 상호작용할 수 있는 ‘도구 사용(Tool Use / Function Calling)’ 능력과, 과거의 맥락을 잊지 않는 대규모 ‘기억 장치(Context Window)’입니다. 구글은 자사의 유기적인 생태계인 구글 검색, 지메일(Gmail), 구글 캘린더, 구글 드라이브의 핵심 API를 AI 에이전트가 스스로 제어하고 판단하여 호출할 수 있도록 강력한 권한을 부여했습니다.
투자자가 봐야 할 본질 (왜 대단한가?): 새롭게 선보인 ‘데일리 브리프’ 기능을 예로 들어보겠습니다. 사용자가 자는 동안 AI 에이전트는 밤새 사용자의 메일함과 캘린더 API를 호출하여 쌓인 데이터들을 스스로 긁어옵니다. 그리고 비즈니스 중요도를 자체적으로 채점(Scoring)한 뒤, 오늘 해야 할 일의 우선순위를 직관적인 대시보드 형태로 알아서 조립해 둡니다. 이 복잡하고 정교한 워크플로우를 인간의 개입 없이 24시간 자율적으로 수행한다는 점에서, 진정한 인공지능 비서 시대의 상용화를 의미합니다.
② 유튜브에 질문하기 (Ask YouTube)
엔지니어링 심층 분석: 사용자가 수십 시간짜리 영상 파일을 올려두고 특정 내용을 질문할 때, AI가 매번 영상 전체를 처음부터 끝까지 실시간으로 돌려보며 분석하는 것은 천문학적인 연산 낭비이자 인프라 파멸을 불러옵니다. 구글은 이 문제를 인프라 단에서 우아하게 해결했습니다. 유튜브에 영상이 업로드되는 즉시, 비디오 픽셀과 오디오 스트림을 시각적·청각적 토큰으로 쪼갠 뒤 이를 고도로 구조화된 ‘인덱싱(Indexing)’ 작업을 통해 벡터 데이터베이스(Vector Database)에 미리 저장해 둡니다.
투자자가 봐야 할 본질 (왜 대단한가?): 사용자가 유튜브 영상에 대해 질문을 던지면, AI는 대용량 영상을 재생하는 것이 아니라 벡터 DB에서 고속 의미론적 검색(Semantic Search)을 수행합니다. 그리고 질문과 일치하는 정확한 장면의 ‘시간대(Timestamp)’를 밀리초 단위로 찾아내어 매칭해 줍니다. 이는 단순히 자막 텍스트를 요약하는 수준을 넘어, 영상 내의 ‘공간과 시간의 맥락’을 AI가 통틀어 완벽히 이해하고 있음을 보여주는 강력한 방증입니다.
3. 하드웨어 인프라: 최초의 ‘듀얼 칩’ TPU 8시리즈와 광학 혁명
아무리 뛰어난 소프트웨어 알고리즘과 에이전트 아키텍처가 존재하더라도, 밑바닥 하드웨어 인프라가 실시간 연산 압박을 견뎌내지 못하면 모두 공염불에 불과합니다. 구글은 엔비디아의 독점 체제에 맞서 하드웨어 전반을 뒤흔들 기막힌 신의 한 수를 던졌습니다. 바로 학습과 추론을 완전히 분리하여 각각의 효율성을 극대화한 ‘듀얼 칩 아키텍처(Dual-chip Architecture)’입니다.
구글이 제시한 최초의 듀얼 칩 인프라, TPU 8시리즈의 핵심 스펙과 엔지니어링 포인트를 테이블로 비교해 드리겠습니다.
구분
TPU 8t (Train)
TPU 8i (Inference)
주요 목적
거대 모델의 사전 학습(Pre-training) 및 파인튜닝(Fine-tuning)
사용자 요청에 대한 초고속 실시간 응답 처리
핵심 강점
초거대 클러스터 확장성 (단일 네트워크 내 100만 개 연동 가능)
극도로 낮은 지연 시간 (Low Latency) 및 비용 절감
엔지니어 팁
메모리 대역폭($HBM$)과 칩 간 초고속 인터커넥트($ICI$) 효율 극대화
연산 행렬 유닛($MXU$) 최적화 및 전력 소모 효율성 극대화
100만 개 클러스터가 가지는 진정한 파괴력과 OCS 기술
많은 이들이 ‘100만 개 칩 연동’이라는 숫자의 화려함에만 집중하지만, 엔지니어 관점에서 주목해야 하는 진짜 핵심은 ‘Optical Circuit Switches (OCS, 광학 회로 스위치)’ 기술의 전면 도입입니다.
기존의 구리선 기반 네트워크 케이블은 데이터 전송량이 늘어날수록 저항이 커지고 극심한 발열과 통신 병목 현상이 발생합니다. 반면 구글은 100만 개의 TPU 8t 칩을 순수 광케이블로 묶어, 빛의 속도로 데이터를 주고받으며 거대한 하나의 슈퍼컴퓨터처럼 작동하게 만들었습니다.
인프라 가동의 가장 큰 암초였던 ‘통신 병목’을 물리적인 광학 기술로 해결해 버린 것입니다. 그 결과, 과거에 6개월 이상 소요되던 초거대 LLM 모델의 가동 및 사전 학습 기간을 단 2~3주 만에 끝낼 수 있는 인프라를 완성했습니다. 이는 빅테크 간의 AI 모델 타임투마켓(Time-to-Market) 경쟁에서 구글이 압도적인 속도 패권을 쥐게 되었음을 시사합니다.
4. 스마트 안경 및 보안: 엣지 AI와 디지털 워터마크의 제도화
인프라와 모델이 완성되자 구글의 AI는 이제 거대한 클라우드 데이터센터의 장벽을 넘어, 사용자 몸에 직접 밀착되는 스마트 디바이스와 보안 영역으로 내려앉았습니다.
[Edge AI & Security]
├─ 구글 스마트 안경 ➔ 온디바이스 NPU + 클라우드 제미나이 플래시 (하이브리드 AI)
└─ 신스ID (SynthID) ➔ 암호학적 스테가노그래피 딥페이크 방어 (글로벌 표준화)
① 구글 스마트 안경 – 포스트 스마트폰 시대를 겨냥한 하이브리드 AI
엔지니어링 심층 분석: 이 얇고 가벼운 안경테 안에는 고성능 카메라, 상시 마이크, 그리고 초저전력 NPU(신경망처리장치)가 탑재되어 있습니다. 스마트 안경이 대중화되려면 배터리와 발열 문제를 잡아야 합니다. 따라서 구글은 ‘하이브리드 AI 아키텍처’를 채택했습니다. 사용자의 시선 앞의 간판을 실시간 번역하거나 내비게이션 경로를 띄우는 등 0.1초의 지연도 허용되지 않는 초고속 작업은 안경 내부에 탑재된 온디바이스(On-device) AI가 독립 처리합니다. 반면, 복잡한 시각적 맥락을 분석하거나 긴 문장을 추론해야 하는 무거운 연산은 클라우드에 대기 중인 ‘제미나이 3.5 플래시’로 데이터를 즉각 토스하여 처리하는 영리한 이원화 방식을 씁니다.
투자자가 봐야 할 본질 (왜 대단한가?): 구글의 스마트 안경 제시는 스마트폰 이후 펼쳐질 새로운 하드웨어 폼팩터 전쟁의 서막입니다. 시각과 청각 데이터를 상시 수집하고 인덱싱해야 하므로, 관련 부품의 단가가 올라가고 고부가가치화가 급격하게 진행될 것입니다.
② 신스ID (SynthID) – 생성형 AI 시대의 필수 불가결한 방어막
엔지니어링 심층 분석: 신스ID는 AI가 생성한 비디오 파일이나 오디오 주파수 픽셀 사이에 인간의 눈과 귀로는 절대 감지할 수 없지만, 컴퓨터 소프트웨어는 완벽하게 읽어낼 수 있는 ‘수학적 패턴(미세 노이즈)’을 고도로 삽입하는 기술입니다. 이 기술이 대단한 이유는 악의적인 사용자가 영상의 화질을 강제로 압축하거나, 일부분을 크롭(자르기)하여 변형하더라도 원본 속에 심어진 수학적 패턴이 깨지지 않고 유지되기 때문입니다. 고도의 암호학적 스테가노그래피(Steganography) 기술을 미디어 인프라에 녹여낸 결정체입니다.
투자자가 봐야 할 본질 (왜 대단한가?): 전 세계적으로 딥페이크를 활용한 금융 사기와 여론 조작이 심각한 사회적 문제로 대두되는 가운데, 신스ID는 딥페이크 방어선의 최전선 역할을 하게 됩니다. 향후 각국 규제 당국의 법제화와 맞물리게 되면, 이와 같은 디지털 워터마크 및 상호 검증 기술은 기업들의 필수 보안 표준(Protocol)으로 자리 잡으며 관련 시장이 폭발적으로 개화할 것입니다.
5. 개발자 생태계: 안티그래비티와 과학 전용 모델을 통한 플랫폼 락인(Lock-in)
플랫폼 전쟁에서 승리하려면 전 세계의 개발자들이 자사의 생태계 안에서 놀 수 있도록 강력한 도구를 쥐여주어야 합니다. 구글은 개발 환경을 혁신하여 개발자들을 끌어들이는 방식 또한 매우 치밀하고 영리하게 짰습니다.
① 안티그래비티(Antigravity) 연동과 자율 디버깅 루프
구글이 새롭게 선보인 ‘안티그래비티(Antigravity)’는 그 이름(무중력)의 의미처럼, 무겁고 복잡하게 꼬여 있던 기존의 프론트엔드 및 백엔드 빌드 패키징 과정을 ‘무중력 상태’처럼 가볍고 기민하게 만들겠다는 구글의 차세대 통합 웹/앱 프레임워크 또는 런타임 환경입니다.
개발자가 코드를 짜다가 에러가 발생해 막히면, AI 스튜디오가 브라우저의 DOM(문서 객체 모델) 구조와 안티그래비티 프레임워크 내부를 스스로 파악하여 자율 디버깅 루프를 돌립니다. AI가 에러 원인을 진단하고 코드를 직접 수정하여 자체 테스트까지 끝마친 뒤, “문제를 완벽히 해결했으니 코드 변경 사항을 확인해 보라”고 인간 개발자에게 역제안하는 수준에 도달했습니다. 개발자의 생산성을 수십 배 증가시켜 구글 생태계를 이탈하지 못하게 만드는 강력한 무기입니다.
② 제미나이 포 사이언스 (Gemini for Science Skill)
인류가 쌓아 올린 방대한 논문 데이터와 실험 데이터를 통틀어 학습한 과학·공학 특화 에이전트입니다. AI가 논문을 스스로 정독한 뒤 미진한 부분을 찾아 가설을 세우고, 컴퓨팅 아키텍처 내부에서 실험 시뮬레이션을 자율적으로 돌리는 ‘에이전틱 과학 워크플로우(Agentic Science Workflow)’를 수행합니다.
중요한 것은 구글이 이 강력한 모델을 오픈소스의 성지인 깃허브(GitHub)에 전격 풀었다는 점입니다. 이는 전 세계의 핵심 과학자, 공학 연구원, 데이터 사이언티스트 개발자들을 구글의 AI 인프라 생태계 아래 든든한 아군이자 종속 관계로 묶어두겠다는 고도의 전략적 포석입니다.
6. 직설적 투자 가치 사슬(Value Chain) 분석
현업 엔지니어가 기술의 화려함에 감탄할 때, 노련한 투자자는 “그래서 이 거대한 인프라가 깔리고 패러다임이 바뀔 때 당장 돈을 벌어들이는 공급망의 대장주는 누구인가?”를 찾아내야 합니다. 자본의 시각에서 철저하게 단기와 중장기로 쪼개어 수혜주들을 분석해 드리겠습니다.
[투자 시기별 핵심 가치 사슬]
├─ 단기적 관점 (1~2년): 브로드컴(ASIC 공동개발), SK하이닉스/삼성전자(HBM 공급), 루멘텀(OCS 광학부품), SaaS 기업(비용 절감)
└─ 중장기적 관점 (3~5년): 퀄컴(엣지 AI 칩), LG이노텍(스마트안경 카메라), 사이버 보안주, Vertiv/Constellation(전력 및 냉각)
1) 단기적 관점 (1~2년 내 실적 가시화 및 강력한 모멘텀)
단기적으로는 구글의 대규모 인프라 물량 공세에 따라 ‘당장 대규모 주문서(PO)가 찍히는 기업’과 모델 가격 인하로 인해 ‘비용을 극적으로 아껴 마진이 튀는 기업’에 돈이 몰립니다.
① 빅테크 인프라 공급망: 구글 자체 칩(TPU 8) 생태계의 숨은 지배자들
브로드컴 (Broadcom, 티커: AVGO): 구글 자체 AI 칩(TPU)의 핵심인 ASIC(주문형 반도체)을 구글과 함께 공동 개발하는 대체 불가능한 핵심 파트너입니다. 구글이 엔비디아 의존도를 낮추고 자체 TPU 8 시리즈 노선을 강화하며 천문학적인 인프라 투자를 감행할수록, 브로드컴의 ASIC 설계 수주 잔고와 로열티 매출은 가장 먼저, 그리고 가장 거대하게 우상향할 수밖에 없습니다.
SK하이닉스 & 삼성전자: 앞서 분석해 드렸듯 고성능 학습용 칩인 ‘TPU 8t’의 연산 병목을 해결하기 위한 핵심 원자재는 HBM(고대역폭 메모리)의 대량 탑재입니다. 구글의 공격적인 데이터센터 인프라 증설은 국내 메모리 반도체 양강 기업들의 하이엔드 제품(HBM3E, HBM4) 믹스 개선으로 전격 이어지며, 단기 마진 및 영업이익을 극대화하는 강력한 펀더멘털 동력으로 작용합니다.
루멘텀 (Lumentum, 티커: LITE) / 코히런트 (Coherent, 티커: COHR): 구글 100만 개 클러스터의 핵심 비밀이 광케이블로 묶는 OCS(광학 회로 스위치) 기술이라고 말씀드렸습니다. 이에 따라 대용량 광트랜시버 및 OCS 광학 컴포넌트 부품 수요가 폭발적으로 늘어납니다. 인프라의 최종 병목이 ‘전기 통신’에서 ‘광통신’으로 넘어가는 구간에서, 이들 광학 부품주들이 가장 탄력적인 단기 주가 랠리를 주도할 가능성이 매우 높습니다.
② 플랫폼 및 소프트웨어 서비스사: 추론 비용(OPEX) 급감의 최대 수혜주
주요 소프트웨어 SaaS 기업들 (Salesforce, HubSpot 등): 그동안 많은 SaaS 기업들이 매력적인 AI 에이전트 기능을 개발해 두고도, 고객이 기능을 호출할 때마다 발생하는 비싼 LLM API 비용 부담(마진 압박) 때문에 적극적으로 서비스를 확산시키지 못했습니다. 하지만 성능은 올라가고 가격은 절반 이하로 떨어진 ‘제미나이 3.5 플래시’의 등장은 이들의 잔혹한 비용 청구서를 반토막 내줍니다. AI 기능 탑재가 기존의 ‘돈을 갉아먹는 하마’에서 기업의 ‘순이익을 폭발시키는 가속기’로 전환되는 구간이므로, 다음 분기부터 영업이익률(OPM)이 즉각적으로 개선되는 구조적 턴어라운드를 보여줄 것입니다.
2) 중장기적 관점 (3~5년 패러다임 시프트 및 시장 재편)
중장기적으로는 서비스의 패러다임이 스마트폰을 넘어 ‘자율적 에이전트가 구동되는 온디바이스(엣지 AI)’와 ‘스마트 안경 폼팩터’로 완전히 넘어가면서 산업의 판도를 뒤바꿀 구조적 성장주를 선점해야 합니다.
① 온디바이스(On-device) AI 및 스마트 안경 밸류체인
퀄컴 (Qualcomm, 티커: QCOM): 스마트 안경을 비롯한 미래형 웨어러블 기기와 온디바이스 단말기에 탑재될 초저전력 엣지 AI 칩셋 시장의 독점적 지배자입니다. 구글이 제시한 하이브리드 아키텍처 인프라가 확산될수록 스마트폰 칩 공급사를 넘어 ‘모든 사물의 인공지능화’를 주도하는 핵심 팹리스로 장기 밸류에이션 리레이팅이 가능합니다.
글로벌 카메라 모듈 및 광학계 기업 (LG이노텍, 대만의 라간정밀 등): 스마트 안경 에이전트의 본질은 인간이 보는 세상을 실시간으로 ‘함께 보고’ 데이터베이스에 인덱싱하는 것입니다. 따라서 기기가 항상 켜져 있어도 배터리가 닳지 않는 ‘저전력 고성능 카메라 모듈’과 가상 이미지를 인간의 눈에 자연스럽게 투사해 주는 증강현실(AR) 글래스용 ‘웨이브가이드(광파도관)’ 핵심 광학 기술을 보유한 기업들이 장기적인 공급 계약을 독식하며 수혜를 누릴 것입니다.
② 보안 및 인프라의 새로운 표준: 신스ID (SynthID) 동맹
디지털 저작권 및 글로벌 사이버 보안 기업 (CrowdStrike, Palo Alto Networks, Adobe): 생성형 AI 컨텐츠의 무분별한 확산과 딥페이크 위협을 막기 위해, 구글의 신스ID 같은 공통 워터마크 프로토콜을 자사 플랫폼에 전면 이식하거나 이를 실시간으로 검증·차단해 주는 전문 보안 솔루션 업체들의 몸값이 천정부지로 솟구칠 것입니다. 특히 어도비(Adobe, 티커: ADBE)의 경우, 자체적으로 추진 중이던 ‘콘텐츠 진위 이니셔티브(CAI)’ 인프라와 구글의 신스ID 표준이 상호 연동되면서 저작권이 확보된 안전한 크리에이티브 플랫폼으로서의 독점 가치가 더욱 견고해질 것입니다.
7. 30년차 애널리스트가 던지는 냉혹한 투자 리스크 (Critical View)
노련하고 지혜로운 투자자라면 기술의 화려한 불꽃놀이 뒤에 숨겨진 그늘과 구조적인 한계점도 반드시 직시해야 합니다. 제가 보는 핵심 리스크는 다음 두 가지입니다.
첫째, 엔비디아(NVIDIA, 티커: NVDA)의 단기 멀티플(이익배수) 둔화 우려
구글이 학습과 추론을 완벽히 이원화한 TPU 8시리즈를 성공적으로 론칭하고 100만 개 클러스터 독립 선언을 한 것은, 독점적 권력을 쥐고 있던 엔비디아에게 매우 명확하고 강력한 경고등입니다. 물론 엔비디아가 구축해 놓은 개발 인프라 생태계(CUDA)의 벽은 여전히 견고합니다.
그러나 구글을 필두로 한 빅테크(메타, 마이크로소프트 등)들이 마진율을 방어하기 위해 자체 주문형 반도체(ASIC) 비중을 지속적으로 높여갈 것은 자명한 사실입니다. 결과적으로 엔비디아가 그동안 독점적으로 누려왔던 극단적인 프리미엄 마진율은 중장기적으로 하향 안정화될 리스크가 있으며, 이는 주가의 단기 멀티플 조정을 유발할 수 있습니다.
둘째, 인프라 확장을 가로막는 진짜 벽: 전력(Utility) 및 냉각 한계
구글이 발표한 100만 개 클러스터 가동의 진짜 무서운 적은 ‘칩의 연산 성능’이 아니라, 이를 돌리기 위한 ‘천문학적인 전력 공급’과 ‘막대한 발열 해결’입니다. 구글이 아무리 날고 기는 TPU 8 칩을 수백만 개 찍어내더라도, 데이터센터가 위치한 지역의 전력망(Grid)이 이를 버텨내지 못하거나 가동 효율을 높여줄 냉각 시스템이 공급되지 못하면 인프라 가동률은 처참하게 떨어집니다.
따라서 역발상적인 투자 관점에서 보면, 인프라 경쟁의 최종 국면에서는 빅테크 기업들보다 그들에게 안정적인 전력을 무한 공급해 줄 수 있는 원전 관련 전력 기업(Constellation Energy 등)이나, 데이터센터의 열을 식혀줄 필수 액체 냉각 솔루션 독점 기업인 버티브(Vertiv, 티커: VRT) 같은 기업들이 인프라 투자의 가장 확실하고 알짜배기인 중장기 수혜주가 될 것입니다.
8. 투자 관점 요약 대시보드 (핵심 요약 테이블)
바쁜 현대 투자자분들을 위해 오늘 분석한 핵심 내용을 한눈에 스캐닝할 수 있도록 직관적인 대시보드 테이블로 정리해 드립니다.
구분
핵심 키워드
추천 포지션 (단기 관점: 1~2년)
추천 포지션 (중장기 관점: 3~5년)
하드웨어
TPU 8, OCS, HBM
브로드컴(AVGO), SK하이닉스 ➔ 자체 칩 생태계 확장 및 인프라 수주 모멘텀
Vertiv (VRT), 퀄컴(QCOM) ➔ 인프라 가동의 필수재(전력 냉각) 및 엣지 AI 지배력
소프트웨어
Gemini 3.5, 에이전트
주요 SaaS 기업들 ➔ 추론 API 비용 감소로 인한 다음 분기 마진 개선
구글 (GOOGL) ➔ 인프라부터 서비스까지 락인(Lock-in)된 수직 계열화 완성 효과
신시장
스마트 안경, SynthID
글로벌 광학 부품주 ➔ 글로벌 빅테크향 스마트 안경 샘플 및 초기 공급 계약 모멘텀
사이버 보안주, 글로벌 원전주 ➔ 딥페이크 보안 제도화 수혜 및 데이터센터 필수 전력 편입
9. 결론: AI가 마침내 ‘돈을 쓰는 단계’를 지나 ‘돈을 버는 단계’로
결론적으로 이번 구글 I/O 2026의 본질은 아주 명확합니다. 인공지능 산업이 막연한 기대감으로 “돈을 쏟아붓고 쓰던 단계”를 완전히 지나, 인프라 효율화와 에이전트 상용화를 통해 “실진적으로 돈을 진정하게 버는 단계”로 진입했음을 증명해 낸 것입니다.
구글은 하드웨어 인프라(TPU 8)부터 운영체제 및 모델 레이어(Gemini 3.5), 그리고 최종 서비스(Search, 안경, 개발도구)까지 전부 다 직접 통제하는 완벽한 수직 계열화 제국을 선언했습니다. 이 견고한 거인들의 전쟁 속에서 길을 잃지 않는 가장 현명한 투자 전략은 다음과 같습니다.
[투자 나침반]
단기적으로는 구글의 칩 자체 독립 생태계 확장에 따른 핵심 가치 사슬(ASIC 설계, HBM 메모리, OCS 광통신 부품)에 강하게 베팅하여 수익률을 극대화하십시오. 그리고 중장기적으로는 이 고성능 에이전트들이 안정적으로 돌아갈 수밖에 없게 만드는 물리적 기반(전력 인프라, 액체 냉각 시스템)과 새로운 폼팩터(온디바이스 부품주)로 자산을 차분히 분산 배치하는 전략이 가장 영리하고 지혜로운 투자 지도입니다.
시장의 패러다임이 바뀔 때 부의 지도도 함께 재편됩니다. 철저한 기술 분석과 냉철한 투자 안목으로 이번 거대한 머니무브의 기회를 반드시 아시아의 주역으로서 선점하시길 바랍니다.
지난 2026년 5월 15일(금요일), 대한민국 금융 역사에 영원히 기록될 기념비적인 사건과 동시에 공포스러운 대폭락이 하루 만에 펼쳐졌습니다. 장중 코스피 지수가 역사상 처음으로 코스피 8000 포인트를 돌파하며 환호성이 터져 나왔으나, 축포의 여운이 가시기도 전에 시장은 급격한 투매 장세로 돌아서며 결국 전일 대비 6.12% 폭락한 7493.18 포인트로 장을 마감했습니다. 고점 대비 무려 8.4%가 하루 만에 밀려버린 초유의 변동성 장세였습니다.
여기에 글로벌 증시의 나침반 역할을 하는 미국 시장 역시 기술주 중심의 차익실현 매물이 쏟아지며 나스닥이 1.54% 하락했고, S&P500 지수도 1.24% 밀리며 주말을 맞이한 투자자들의 밤잠을 설치게 만들었습니다.
오늘 2026년 5월 18일 월요일 개장을 불과 몇 시간 앞둔 지금, 우리는 이 현상을 어떻게 바라봐야 할까요? 30년 이상 시장의 산전수전을 모두 겪은 베테랑 애널리스트의 시각을 빌려, 이번 폭락의 본질적인 원인을 해부하고 오늘 아침 당장 주목해야 할 단기 체크포인트와 향후 하반기를 관통할 중장기적 대응 전략을 뼈대부터 상세히 분석해 드리겠습니다.
본 글은 거시경제 지표, 시장 내부 수급, 섹터별 모멘텀을 입체적으로 다룬 초장문 리포트입니다. 천천히 정독하시며 오늘 시장을 맞이할 강력한 무기를 얻어 가시길 바랍니다.
1. 5월 15일 폭락 장세의 본질과 원인 분석
이번 대폭락을 단순한 ‘묻지마 폭락’이나 ‘공포에 의한 투매’로만 치부해서는 앞으로의 시장에서 살아남을 수 없습니다. 시장이 왜 코스피 8000이라는 심리적 마디 지수(Round Figure)를 찍자마자 이토록 차갑게 돌아서야만 했는지, 세 가지 핵심 원인을 먼저 짚어보겠습니다.
① 과속에 따른 피로 누적과 ‘탐욕 구간’의 피크아웃
가장 근본적인 원인은 ‘속도’에 있었습니다. 코스피 지수가 7000 포인트를 돌파한 지 불과 일주일 남짓한 시간 만에 단숨에 8000 포인트까지 치고 올라왔습니다. 기술적 분석 관점에서 볼 때, 이동평균선과의 괴리율(이격도)이 역사적 최고 수준에 도달해 있었으며, 투자심리선과 RSI(상대강도지수) 등 대부분의 보조지표가 ‘극단적 과열(Extreme Greed)’을 가리키고 있었습니다.
주식 시장에서 가장 큰 악재는 ‘과도하게 오른 주가’ 그 자체입니다. 코스피 8000선 돌파라는 상징적인 목표가 달성되는 순간, 장기 보유자들과 기관들의 강력한 차익실현(Profit-taking) 욕구가 분출되었고, 이것이 프로그램 매도세와 결합하면서 도미노식 투매를 유발했습니다.
② 외국인의 역대급 수급 이탈과 원/달러 환율 1,500원 돌파
금요일 하루 동안 유가증권시장(코스피)에서 외인은 약 5.5조 원이라는 사상 유례없는 규모의 순매도를 기록했습니다. 외인들이 이토록 거세게 물량을 던진 배경에는 급격하게 요동친 원/달러 환율이 있습니다.
당일 원/달러 환율은 전 거래일보다 급등하며 단숨에 1,509.6원으로 마감, 심리적 마지노선이었던 1,500원선을 상방으로 뚫어버렸습니다. 환율이 이처럼 치솟으면 외국인 투자자 입장에서는 주식 자체에서 수익이 나더라도 환차손(FX Loss) 위험이 커지기 때문에 일차적으로 한국 자산을 매도해 달러로 바꾸려는 유인이 강해집니다. 외인의 매도가 환율 상승을 부추기고, 상승한 환율이 다시 외인의 매도를 부르는 ‘악순환의 고리’가 금요일 오후 장을 지배했던 것입니다.
③ 반도체 투톱의 높은 지수 지배력과 내부 노이즈
최근 코스피 8000선 근처까지 올 수 있었던 일등 공신은 단연 AI 메가 트렌드의 중심에 선 반도체 대형주, 즉 삼성전자와 SK하이닉스였습니다. 이 두 종목이 코스피 전체 시가총액에서 차지하는 비중은 최근 40%를 상회할 정도로 비대해진 상태였습니다.
그러나 지수가 극점에 달한 순간, 삼성전자의 노사 갈등과 파업 우려라는 내부적 잡음(Noise)이 시장에 노출되었습니다. 안 그래도 차익실현 명분을 찾던 매도 세력에게 이 뉴스는 완벽한 트리거가 되었습니다. 결국 금요일 종가 기준으로 삼성전자는 8.61%, SK하이닉스는 7.66% 폭락하며 지수 전체를 밑바닥으로 끌어내렸습니다. 시총 상위 주도주가 무너지니 코스피 지수가 6% 넘게 밀리는 것은 필연적인 결과였습니다.
2. 5월 18일 월요일 개장 전 단기적 관점 (이번 주 핵심 체크포인트)
안개 속을 걸어가는 듯한 오늘 아침, 투자자가 장 초반 체결창과 뉴스 화면에서 가장 먼저 확인해야 할 세 가지 단기 나침반을 제시합니다.
① 외국인 매도세의 진정 및 환율 1,500원선 안착 여부
오늘 장 시작과 동시에 가장 먼저 확인해야 할 지표는 주가창이 아니라 ‘원/달러 환율’과 ‘외국인 수급 가집계’입니다.
긍정적 시나리오: 환율이 1,500원대 초반이나 1,490원선으로 빠르게 하향 안정화되고, 외인의 순매도 규모가 수천억 원 수준으로 급감한다면 시장은 금요일의 낙폭을 과도한 해프닝으로 인식하고 빠르게 지지선을 구축할 것입니다.
부정적 시나리오: 개장 직후 환율이 1,510원을 돌파하며 상승세를 이어가고, 외인이 장 시작 30분 만에 수천억 원의 매도 우위를 보인다면 지지는 유예되고 추가적인 하방 테스트가 진행될 수 있습니다. 이 경우 무리한 물타기보다는 관망이 유리합니다.
② 삼성전자·SK하이닉스의 기술적 반등과 하방 경직성
반도체 투톱의 시초가 형성과 장중 흐름은 오늘 코스피 방향성의 90%를 결정할 것입니다. 금요일의 7~8%대 폭락은 대형주 기준으로 분명 과매도 구간에 진입했음을 시사합니다.
오늘 장 초반 개인 투자자들의 강한 저가 매수세(반발 매수)가 유입될 가능성이 높습니다. 그러나 진정한 바닥 확인은 개인이 아니라 기관과 외국인이 매도세를 멈추고 사서 바쳐주는 흐름(하방 경직성)이 나타날 때 비로소 완성됩니다. 장중 두 종목의 호가창이 단단하게 지지되는지 반드시 관찰하십시오.
③ 매크로 외부 변수: 미 국채 금리와 WTI 국제유가
주말 사이 마감한 미국 증시의 하락 뼈대를 보면 미 국채 10년물 금리가 4.6% 선을 위협하고, 서부텍사스산원유(WTI)가 배럴당 100달러 선을 압박하는 등 ‘인플레이션 재점화 우려’가 핵심이었습니다.
오늘 아침 발표되는 아시아 시장에서의 미 국채 선물 금리 추이와 국제 유가 움직임을 체크해야 합니다. 유가가 지속적으로 고공행진을 펼친다면 국내 정유·화학 섹터 등 일부 방어주로의 수급 쏠림이 일어날 수 있으며, 이는 기술주와 성장주에는 지속적인 압박 요인이 됩니다.
3. 하반기를 관통할 중장기적 관점 (포트폴리오 리밸런싱 전략)
단기적인 변동성에 일희일비하기보다 30년 차 애널리스트가 강조하는 중장기 펀더멘탈의 변화를 이해해야 거대한 자산을 지키고 불릴 수 있습니다. 향후 수개월간 이어질 중장기 시장의 핵심 축을 설명합니다.
구분
주요 특징 및 전망
추천 대응 전략
시장 성격
대세 하락 전환이 아닌, 과열 해소를 위한 ‘건강한 기간 조정’
패닉 셀링 지양, 현금 비중 확보 후 우량주 분할 매수
주도주 변화
반도체 원툴(One-tool) 쏠림 현상의 완화 및 다변화
AI 모멘텀 유지하되, 밸류에이션 부담 없는 소외주 발굴
매크로 환경
고물가·고금리 장기화(Sticky Inflation) 우려 존재
현금 흐름이 우수하고 배당 성향이 높은 안정적 가치주 혼합
① 대세 상승장의 훼손인가, 건강한 조정인가?
많은 투자자가 가장 두려워하는 질문입니다. “이제 하락장(베어마켓)의 시작인가?” 이에 대한 저의 대답은 “아니다, 이것은 대세 상승 추세 속에서 필연적으로 거쳐야 할 건강한 숨고르기(조정)이다”입니다.
과거 코스피가 역사적 마디 지수를 돌파할 때의 궤적을 보면, 단 한 번도 멈춤 없이 전진한 적이 없습니다. 급격하게 차오른 거품과 과열을 시원하게 터뜨려 주어야만 장기적으로 더 높은 고지를 향해 갈 수 있는 에너지가 축적됩니다. 글로벌 AI 수요와 국내 기업들의 수출 이익 체력(펀더멘탈)이 부러지지 않았기 때문에, 이번 조정은 시장의 붕괴가 아니라 지나치게 비싸진 주가를 다시 매력적인 가격대로 되돌려 놓는 과정으로 해석해야 합니다.
② 시장 집중도 완화와 섹터 순환매 도래 (반도체 ➔ 밸류업·배당주)
그동안 코스피 지수는 몇몇 반도체 초대형주가 끌고 가는 ‘착시 장세’였습니다. 이로 인해 수많은 중소형 우량주와 타 섹터 종목들은 소외감을 느껴야 했습니다.
지수가 7,000~7,500선 사이에서 기간 조정을 거치는 동안, 시장의 자금은 그동안 가격 메리트가 발생한 다른 곳으로 눈을 돌릴 것입니다. 특히 정부가 강력하게 추진해 온 기업 밸류업 프로그램 수혜주(금융주, 자동차, 대형 지주사)와 안정적인 월배당·고배당 매력을 가진 자산들이 훌륭한 대안처가 될 것입니다. 주도주가 다변화되는 과정은 시장 전반의 기초체력을 오히려 튼튼하게 만듭니다.
③ 고금리·고물가 장기화에 따른 ‘이익 체력’ 중심의 종목 장세
미국의 연착륙 시나리오는 유효하지만, 인플레이션의 하방 경직성 때문에 금리 인하의 시기나 폭은 당초 시장의 기대보다 뒤로 밀릴 가능성이 큽니다. 이러한 매크로 환경에서는 부채 비율이 높고 미래 성장성만으로 버티던 성장주들은 힘을 쓰기 어렵습니다.
중장기적으로는 자체적인 현금 창출 능력이 뛰어나고, 무차입 경영에 가깝거나 이자 보상 배율이 높은 기업, 즉 ‘이익의 질(Quality of Earnings)’이 검증된 기업들로 포트폴리오를 압축해야 합니다. 철저한 실적 중심의 종목 차별화 장세가 하반기의 핵심 키워드가 될 것입니다.
4. 경제 블로거와 투자자를 위한 최종 제언
“시장의 탐욕 속에서 공포를 느끼고, 시장의 공포 속에서 탐욕을 가져라.”
워런 버핏의 이 오랜 격언은 오늘 같은 날 가장 빛을 발합니다. 지난주 코스피 8000을 돌파할 때 눈이 멀어 무리하게 레버리지를 일으켰던 투자자들은 큰 대가를 치렀을 것입니다. 반대로 오늘 아침 공포에 질려 눈앞의 우량한 자산을 바닥 가격에 던져버리는 실수를 범해서도 안 됩니다.
요약
서두르지 마십시오: 오늘 오전 장은 금요일의 충격 여파로 변동성이 극대화될 것입니다. 최소한 오전 11시 이후 시장의 수급이 안정을 찾는 모습을 확인하고 움직여도 결코 늦지 않습니다.
환율을 이정표로 삼으십시오: 원/달러 환율이 1,500원 밑으로 내려앉는 타이밍이 곧 시장의 단기 저점 신호가 될 것입니다.
체질 개선의 기회로 삼으십시오: 반도체 일변도의 포트폴리오였다면, 이번 조정을 활용해 이익 체력이 튼튼한 고배당주나 밸류업 수혜주로 분산 투자하는 리밸런싱을 단행하십시오.
시장의 흔들림은 일시적이지만 기업의 본질적 가치는 영원합니다. 냉정함을 유지하며 리스크 관리에 만전을 기하는 현명한 투자자가 되시기를 응원합니다. 본 분석이 여러분의 성공적인 투자 여정에 든든한 길잡이가 되기를 바랍니다.
이란-미국 전쟁 이후 최근 전 세계 금융 시장이 그야말로 발칵 뒤집혔습니다. 사상 최고치를 경신하며 거침없이 랠리를 이어가던 뉴욕 증시와 코스피가 갑작스러운 폭락장을 맞이했기 때문입니다. 많은 언론에서는 단순히 “중동 리스크로 인한 고유가와 인플레이션 우려”라는 표면적인 이유만 읊조리고 있습니다.
하지만 과연 그게 전부일까요?
오늘 포스팅에서는 우리가 눈앞에서 목격하고 있는 미국 증시 폭락의 진짜 원인부터, 뉴스 행간에 숨겨진 미국의 기축통화(페트로 달러) 방어 전략, 세계 최대 중질유 매장국인 베네수엘라 전격 장악의 비밀, 그리고 이 거대한 혼돈 속에서 중국과 BRICS 진영이 던지는 AI 반격 카드와 한국의 독보적인 실리적 생존 전략까지, 낱낱이 파헤쳐 보겠습니다.
호흡이 다소 길지만, 이 글을 끝까지 읽으시면 현재 글로벌 경제와 지정학적 위기를 바라보는 완전히 새로운 눈을 갖게 되실 겁니다.
목차
글로벌 정세 브리핑: 오늘 미 증시와 한국 증시가 폭락한 이유
풀리지 않는 의문: 세계 최대 산유국 미국, 왜 자국 물가를 통제하지 못할까?
거대한 체스판 (Grand Chessboard): 이란 전쟁과 베네수엘라 장악은 계산된 시나리오인가?
BRICS와 중국의 다음 스텝: 죽어가는 경제를 살릴 ‘소버린 AI’ 반격 카드
결론: 거대한 균열 속 ‘올라운더 제조 강국’ 한국이 취할 독보적 실리
1. 글로벌 정세 브리핑: 오늘 미 증시와 한국 증시가 폭락한 이유 (이란-미국 전쟁 이후 최근 전 세계 금융 시장)
시장의 폭락은 예고 없이 찾아왔습니다. 최근 글로벌 증시를 지배하던 낙관론(유포리아)을 단번에 무너뜨린 핵심 악재들을 정리해 드립니다.
🚨 유가 100달러 돌파와 인플레이션 재가속 쇼크
미국과 이란 간의 종전 협상이 불확실성으로 치닫고, 전 세계 원유 물동량의 동맥인 호르무즈 해협(Strait of Hormuz)의 봉쇄 우려가 현실화되면서 WTI(서부텍사스산원유) 가격이 배럴당 100달러를 돌파했습니다. 이로 인해 간신히 잡혀가던 글로벌 물가가 다시 튀어 오를 수 있다는 ‘인플레이션 쇼크’가 시장을 엄습했습니다.
📈 미국 국채 금리 급등 및 ‘금리 인상’ 베팅 대두
물가 지표(PPI)가 예상보다 뜨겁게 나온 상황에서 미국의 산업생산 및 제조업 지수마저 견조하게 발표되자, 연준(Fed)의 올해 금리 인하 기대감은 완전히 소멸했습니다.
오히려 CME 페드워치 등 선물시장에서는 2026년 내에 금리를 추가 인상해야 할 수도 있다는 극단적인 매파적 베팅이 급증했습니다.
이로 인해 시장 밸류에이션의 척도가 되는 미국 10년물 국채 금리가 1년 만에 최고치인 4.6%선까지 급등하며 기술주들의 멀티플을 사정없이 깎아내렸습니다.
📉 엔비디아 중심의 AI·반도체 고평가 대형주 차익 실현
새로운 연준 의장(케빈 워시) 체제 출범에 따른 통화정책 불확실성까지 겹치자, 자금은 위험자산에서 빠르게 이탈했습니다. 그동안 시장을 홀로 견인하다시피 했던 엔비디아(Nvidia)를 비롯한 대형 AI 기술주와 반도체 섹터가 가장 먼저 타격을 입으며 낙폭을 주도했습니다.
🇰🇷 어제 한국 증시(코스피)가 급락한 내막
한국은 에너지 수입 의존도가 절대적으로 높아 중동발 고유가 충격의 직격탄을 맞았습니다.
미국 국채 금리 급등으로 달러 강세(원화 약세) 압력이 커지자 외국인 투자자들이 한국 시장에서 무차별적인 ‘바스켓 매도’를 단행했습니다.
특히 코스피가 장 중 사상 처음으로 8,000선을 돌파하며 단기 고점 부담이 극에 달했던 터라, 글로벌 악재가 터지자마자 차익 실현 욕구가 패닉 셀링으로 이어졌습니다. (외신들은 주 초반 있었던 청와대의 ‘AI 국민배당금 구상’ 등 국내 정책적 불확실성도 투자 심리 위축에 한몫했다고 분석합니다.)
2. 풀리지 않는 의문: 세계 최대 산유국 미국, 왜 자국 물가를 통제하지 못할까?
여기서 우리는 아주 상식적이고 본질적인 의문을 던져야 합니다.
“미국은 셰일 혁명 이후 세계 최대의 원유 생산국이자 순수출국인데, 왜 중동에서 전쟁이 났다고 자국 내 주유소 기름값이 폭등하고 인플레이션으로 고통받는가? 그냥 자국에서 캐낸 기름을 자국민에게 싸게 공급하면 되는 것 아닌가?”
대단히 합리적인 질문입니다. 하지만 미국이 자국 내 유가를 통제하지 못하고 글로벌 고유가 쇼크를 그대로 흡수하는 데는 자유시장경제의 구조적 메커니즘과 치명적인 기술적 한계(미스매치)가 자리 잡고 있습니다.
① 원유 시장의 ‘글로벌 단일화’와 차익거래 (Arbitrage)
원유는 전 세계에서 가장 활발하게 거래되는 글로벌 단일 상품(Commodity)입니다. 미국의 석유 기업들은 국가 소유가 아닌 민간 기업(ExxonMobil, Chevron 등)이며, 이들은 철저히 이윤 극대화를 위해 움직입니다.
국제 유가(브렌트유 등)가 배럴당 100달러를 넘어가면, 미국 민간 산유 기업들은 굳이 미국 내수 시장에 기름을 싸게 팔 이유가 없습니다. 더 비싼 값을 주는 유럽이나 아시아로 수출하면 되기 때문입니다. 결국 미국 내 정유사나 소비자가 자국산 원유를 인도받으려면 국제 시장 가격만큼의 비용을 지불해야만 합니다. 개방된 자유무역 체제 하에서는 자국산 원유라고 해서 내수 가격을 인위적으로 낮출 수 있는 방화벽이 없습니다.
② 미국 정유 시설의 구조적 미스매치 (경질유 vs 중질유)
이 부분이 기술적으로 가장 핵심적인 요인입니다. 미국이 세계 최대 산유국이 된 것은 땅속 깊은 암석층을 깨서 기름을 캐내는 ‘셰일 혁명’ 덕분입니다. 그런데 여기서 치명적인 성질의 불일치가 발생합니다.
미국이 생산하는 기름 (경질유): 셰일 가스전에서 나오는 원유는 황 함량이 적고 가벼운 ‘초경질유(Light Sweet Crude)’입니다.
미국 정유 공장이 원하는 기름 (중질유): 미국의 대규모 정유 시설(미 걸프만 연안 등)은 수십 년 전 설계될 당시 중동, 베네수엘라 등에서 수입하던 황 함량이 높고 끈적끈적하며 무거운 ‘중질유(Heavy Sour Crude)’를 처리하도록 수십억 달러를 들여 최적화되었습니다.
이 때문에 미국은 자국에서 나오는 가벼운 경질유를 정제할 능력이 부족해 해외로 대거 수출하는 동시에, 자국 정유 공장을 돌려 휘발유와 디젤을 만들기 위해 중동이나 캐나다로부터 중질유를 매일 수백만 배럴씩 수입하고 있습니다. 따라서 호르무즈 해협이 막혀 중질유 수입길이 불안해지면, 미국 정유사들의 원가 부담이 급등하여 미국 내 주유소 가격이 폭등하게 되는 것입니다.
③ 민간 주도 시장의 ‘공급 비탄력성’과 주주의 압박
사우디아라비아의 아람코 같은 국영 석유 기업은 국가의 명령에 따라 유가 조절을 위해 증산을 할 수 있습니다. 반면 미국의 셰일 기업들은 과거 유가 급락기 때 무리하게 시설을 늘렸다가 파산했던 트라우마가 있습니다.
현재 미국 석유 기업들의 주주들은 무리한 증산보다는 고유가 상황에서 번 돈으로 배당금을 늘리거나 자사주를 매입해 주가를 올리기를 강력히 요구합니다. 따라서 유가가 오른다고 해서 미국 기업들이 갑자기 공급을 획기적으로 늘려 가격을 다운시키지 않습니다.
3. 거대한 체스판 (Grand Chessboard): 이란 전쟁과 베네수엘라 장악은 계산된 시나리오인가?
이제 한 걸음 더 깊이 들어가 국제정치학적 관점에서 이 현상을 바라보겠습니다. 2026년 초부터 급박하게 돌아간 국제 정세의 타임라인을 연결해 보면, 이번 사태가 단순한 돌발 악재가 아니라 미국의 철저히 계산된 ‘거대 전략(Grand Strategy)’일 수 있다는 강력한 가설이 성립합니다.
📅 2026년 상반기 긴박한 타임라인
1월: 베네수엘라 마두로 정권의 전격적인 교체와 미국의 석유 통제권 확보
2~3월: 미국과 이란 간의 갈등 폭발, 이란 전쟁 발발 및 호르무즈 해협 봉쇄
5월: 글로벌 유가 100달러 돌파 및 미국 대형 석유 메이저들의 역대급 폭리
💡 기획설의 논리: 미국이 얻는 압도적인 실익
1) 베네수엘라와 미국 경질유의 완벽한 퍼즐 완성
앞서 언급한 미국의 치명적인 약점(자국 내 중질유 부족)을 해결하기 위해 미국은 전쟁 직전인 1월, 세계 최대 중질유 매장국인 베네수엘라를 장악하고 그 매각 대금을 미국 통제하의 계좌에 묶어두었습니다.
호르무즈 해협이 막히자 전 세계 산유국 중 이 물동량을 대체할 수 있는 나라가 사라졌지만, 미국은 자국의 경질유를 전 세계에 사상 최고가로 수출하는 동시에, 자국 정유 공장에는 통제권 안에 넣은 베네수엘라의 중질유를 헐값에 가져다 쓰는 구조를 만들었습니다. 공급망의 완벽한 내재화입니다.
2) 페트로 달러 패권의 방어막 구축 (탈달러화 차단)
최근 중국과 인도를 중심으로 “원유 결제 대금을 위안화나 루피화로 하겠다”는 탈달러화(De-dollarization) 움직임이 거셌습니다. 기축통화의 지위를 위협받던 미국은 중동 전체를 전쟁의 화염에 휩싸이게 하고 호르무즈를 봉쇄함으로써 전 세계 유조선들을 미국 항구로 강제 턴시켰습니다. 에너지 공급의 중심을 미국 본토로 이동시키며 “석유를 사려면 결국 미국 달러가 필요하다”는 페트로 달러의 명제를 전 세계에 다시 한번 각인시켰습니다.
⚖️ 미국의 손익계산서: 소탐대실(小貪大失)을 피하기 위한 선택
물론 이 전쟁으로 인해 미국 역시 단기적으로 인플레이션을 겪고, 뉴욕 증시가 폭락하며, 집권 여당(공화당)이 선거에서 표심을 잃는 거대한 고통을 겪고 있습니다. 그럼에도 불구하고 왜 이 길을 용인했을까요?
단기적 손실 (전술적 비용)
장기적 이익 (전략적 생존)
• 국내 주유소 기름값 폭등 (민심 이탈) • 고금리 장기화로 인한 증시 폭락 • 선거에서 집권 여당의 표심 타격
• 페트로 달러 기축통화 지위 사수 • 미국 재정적자/국채 시스템의 파산 막음 • 에너지·금융 공급망의 미국 중심 리셋
미국의 전략가들이 보기에 ‘당장의 선거 패배나 경기 둔화’는 통화 정책으로 추후 회복 가능한 ‘전술적 손실’이지만, ‘달러 패권 상실’은 제국의 영구한 종말을 의미하는 ‘실존적 파산’입니다. 더 큰 가치를 지키기 위해 기꺼이 단기적 고통(인플레이션)이라는 비용을 지불하는 도박을 선택한 것입니다.
4. BRICS와 중국의 다음 스텝: 죽어가는 경제를 살릴 ‘소버린 AI’ 반격 카드
미국이 금융과 에너지라는 전통적인 레버리지로 방화벽을 치자, 허를 찔린 중국과 BRICS 진영 역시 순순히 물러서지 않고 있습니다. 이들이 내놓은 생존을 위한 다음 카드는 바로 ‘디지털 영토(AI 및 반도체)’의 실리 추구입니다.
🇨🇳 중국의 카운터: 첨단 패키징과 AI 공급망 우회 올인
미국의 극심한 GPU 및 반도체 장비 수출 통제 속에서 중국은 사활을 걸고 있습니다. 네덜란드 ASML의 첨단 노광장비(EUV) 수입이 막히자, 중국은 미세 공정 대신 여러 개의 칩을 효율적으로 묶는 3D 패키징 및 CPO(광학 소자 통합) 기술에 천문학적인 자금을 쏟아붓고 있습니다. 기술적 한계를 후공정으로 커버하여 자국 내 AI 인프라를 기어코 완성하겠다는 독기 어린 실리 카드입니다.
📊 BRICS 진영의 AI 불균형과 심폐소생술
현재 러시아의 제재 장기화, 브라질·남아공의 성장 정체 등 BRICS 국가들의 기초 체력은 매우 좋지 않습니다. 이 죽어가는 경제를 살릴 유일한 돌파구가 바로 AI를 통한 산업 효율화입니다. 거시경제 분석에 따르면 BRICS 내 생성형 AI 시장은 2030년까지 6,000억 달러(약 800조 원) 규모로 팽창할 전망입니다.
재미있는 점은 이 과실의 86%를 중국 혼자 독식하고 있으며, 인도(10%), 러시아·브라질 등이 나머지 4%를 겨우 나누어 갖는 기형적 구조라는 것입니다. 이 때문에 중국을 제외한 BRICS 국가들은 미국과의 전면전을 벌이기보다, 철저히 실리를 챙기는 양다리 외교를 펼치고 있습니다.
🌐 ‘소버린 AI(Sovereign AI)’ 시대와 미국 빅테크의 기묘한 공생
지정학적 위기를 보며 전 세계 국가들은 미국 상용 클라우드에 자국의 데이터를 100% 맡기는 것이 얼마나 위험한지 깨달았습니다. 이에 따라 자주적 AI 정체성을 지키려는 ‘소버린 AI’ 붐이 일고 있습니다.
엔비디아, 마이크로소프트 등 미국 빅테크들은 자국 정부의 규제를 준수하면서도 시장을 잃지 않기 위해 기묘한 타협안을 내놓고 있습니다. 중동이나 신흥국에 첨단 칩(Blackwell 등)을 공급하되, 데이터의 소유권과 LLM(대형언어모델) 가중치 제어권은 해당 국가에 온전히 넘겨주는 ‘하이브리드 협력 모델’입니다. 신흥국은 미국의 인프라로 자국 맞춤형 AI를 빠르게 구축해 경제를 살리고, 미국 빅테크는 매출을 올리는 철저한 실리주의 연대가 형성되고 있습니다.
5. 결론: 거대한 균열 속 ‘올라운더 제조 강국’ 한국이 취할 독보적 실리
과거의 전쟁이 석유 파이프라인과 해협을 막는 싸움이었다면, 미래의 전쟁은 데이터 센터의 전력망과 반도체 파운드리의 캐파를 누가 쥐느냐의 싸움입니다. 이 거대한 고래 싸움 틈바구니에서 대한민국은 전 세계에서 가장 흥미롭고 독보적인 실익을 추구할 수 있는 몇 안 되는 ‘치트키’ 같은 나라입니다.
한국은 세계가 멈추지 않기 위해 반드시 사 가야 하는 핵심 하드웨어를 전부 포트폴리오로 가지고 있기 때문입니다.
🚢 조선: 글로벌 에너지 물류망 재편의 최대 수혜
호르무즈 해협 봉쇄로 중동 해로가 막히자, 전 세계 에너지 공급선은 대서양(미국 셰일, 베네수엘라)으로 대전환 중입니다. 이동 거리가 길어질수록 배가 더 많이 필요해지며, 특히 미국산 가스를 실어 나를 LNG/LPG 운반선 수요가 폭발하고 있습니다. 최고 수준의 기술력을 가진 한국의 조선 빅3(HD현대, 한화오션, 삼성중공업)는 선가를 부르는 게 값인 ‘슈퍼 을(乙)’의 지위를 굳혔습니다.
⚛️ 원전: 고유가 시대의 유일한 구원투수 (K-원팀 출범)
배럴당 100달러 시대에 에너지를 자급하기 위한 카드는 원자력발전뿐입니다. 마침 한국 정부는 해외 수주 경쟁력을 극대화하기 위해 한전과 한수원의 역할을 분담한 민관 합동 ‘원전수출기획위원회’를 신설하며 덤핑 논란을 잠재우고 ‘원팀 코리아’로 체제를 개편했습니다. 가성비와 철저한 공기 준수를 무기로 체코, 아시아, 심지어 남미 시장까지 독점할 최적의 타이밍입니다.
💾 반도체와 AI: 대체 불가능한 HBM 공급망
미국이 중국을 아무리 조여도 엔비디아의 차세대 AI 칩(Blackwell, Rubin 등)을 구동하기 위한 HBM(고대역폭메모리)을 대량 생산할 수 있는 나라는 전 세계에 한국뿐입니다. 중국은 우회 수입을 위해 한국의 범용 반도체를 애타게 찾을 것이고, 미국은 자국 생태계 내에 한국의 공급망을 안전하게 묶어두려 할 것입니다. 양쪽 모두에게 한국은 ‘없어서는 안 될 치명적인 거점’이기에 정교한 줄타기를 통해 막대한 실익을 거둘 수 있습니다.
✍️ 포스팅을 마치며: 위기 속에 숨겨진 거대한 기회
지정학적 파도가 아무리 높게 일어도, 그 파도를 넘을 수 있는 단단한 배와 기술을 가진 서플라이 체인의 강자는 살아남습니다. 현재 금융 시장의 단기적인 조정과 폭락은 공포스럽지만, 그 이면에서 요동치는 에너지와 AI 기술 패권의 대전환기를 읽어낼 수 있다면 우리는 남들이 보지 못하는 거대한 투자 기회와 미래 성장 모멘텀을 발견할 수 있을 것입니다.
역사적으로 패권국들은 시스템 위기 때마다 판을 새로 짜왔고, 2026년 현재 우리는 그 역사적 변곡점의 한가운데 서 있습니다. 한국 기업들의 저력과 거시경제의 흐름을 계속해서 예리하게 주시해야 하는 이유입니다.
독자 여러분들은 이번 고유가와 AI 패권 정국 속에서, 한국의 어떤 섹터가 가장 드라마틱한 폭발력을 보여줄 것이라고 생각하시나요? 여러분의 소중한 의견을 댓글로 들려주세요!




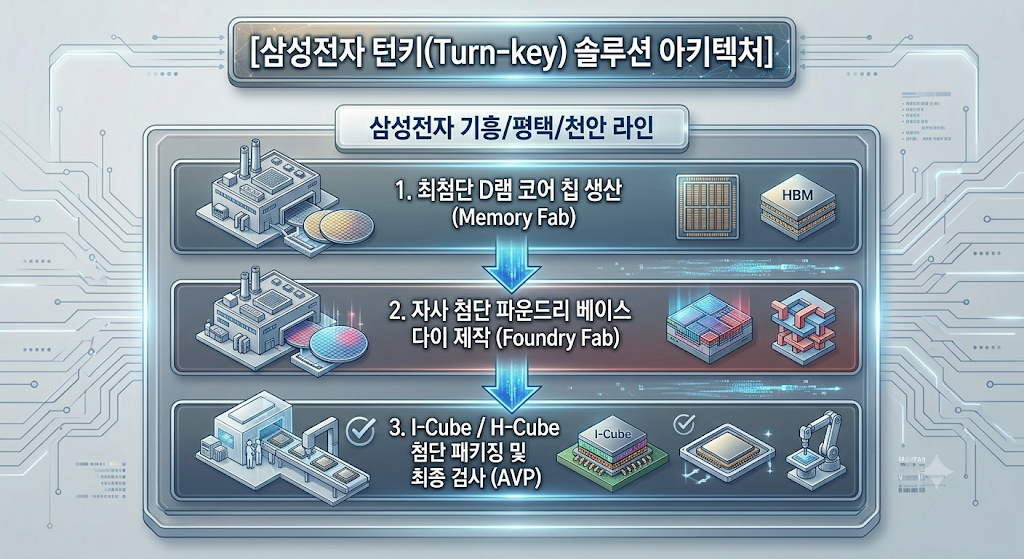

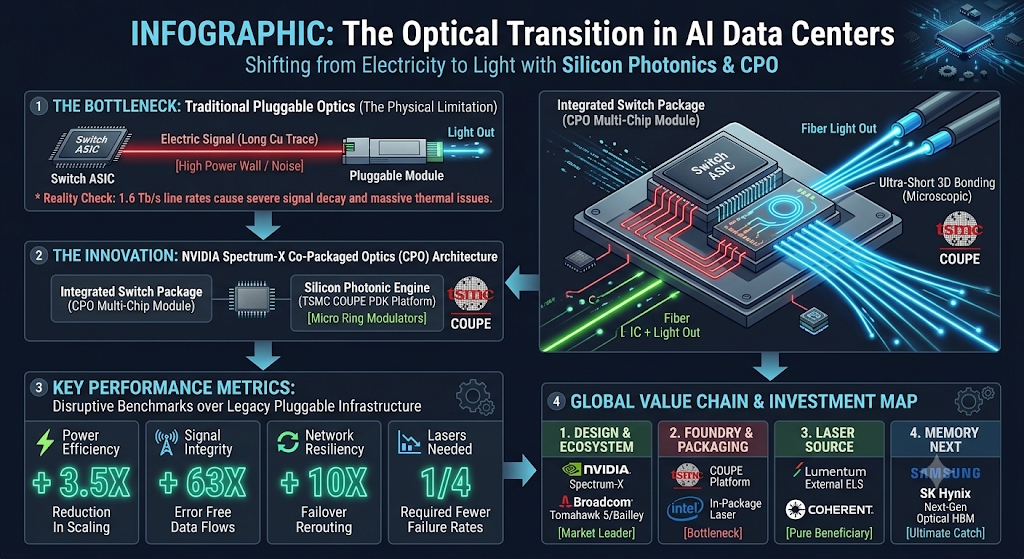

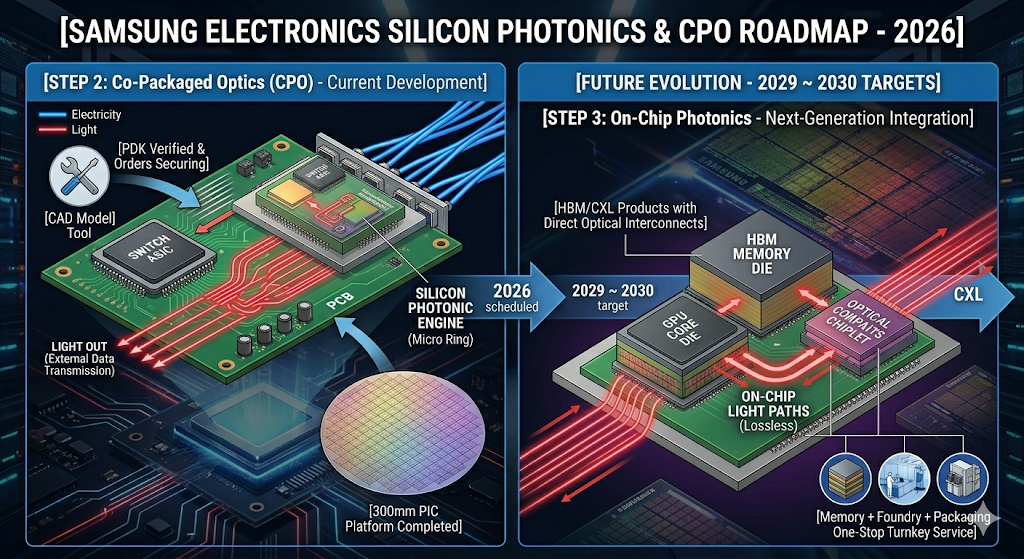
![[Main Title]
"젠슨 황 NVIDIA CEO JENSEN HUANG’S 2026 KOREA VISIT: A PARADIGM SHIFT TO PHYSICAL AI & ON-DEVICE ECOSYSTEMS"
(중앙 상단에 위치한 메인 타이틀로, 젠슨 황의 2026년 방한이 피지컬 AI 및 온디바이스 생태계로의 패러다임 시프트를 의미함을 명시)
[Key Insight]
"KOREAN COMPANIES EVOLVE FROM MEMORY SUPPLIERS TO CORE PARTNERS"
(한국 기업들이 단순한 메모리 공급처에서 핵심 파트너로 진화했다는 애널리스트의 핵심 통찰 제시)
[Section 1: Timeline of Jensen Huang's Visit]
이미지 중앙에는 5월부터 6월까지의 시간 흐름과 방한 행보를 나타내는 화살표 형태의 타임라인 플로우 차트가 시각화되어 있습니다.
May/June 2026 - Buzz & Expectations: 방한 전 수혜주에 대한 시장의 뜨거운 기대감과 대중적 관심(말풍선 아이콘).
Jensen Huang's Visit: 방한 기간 중 이루어진 파격적인 행보들을 아이콘으로 묘사. 성수동 삼겹살 회동(테이블에 둘러앉은 인물들), 홍대 PC방 방문(맥주와 모니터 아이콘), 야구장 시구(투구하는 야구선수 일러스트).
Post-Visit - Oak from Ashes (옥석 가리기): 방한 이후 진짜 실적주와 테마주를 분별하는 시장의 조정기 및 필터링 단계 진입.
[Section 2: Market Perspective (Market Analysis)]
타임라인 우측에서 이어지는 흐름으로, 투자자가 직면한 두 가지 시장 관점을 상하 구조로 분석합니다.
Short-Term (단기적 관점): "Momentum Fading & Volatility" - 재료 소멸에 따라 주가가 하락하는 꺾인 그래프 아이콘과 함께 단기 변동성 경고.
Medium/Long-Term (중장기적 관점): "Structural Growth in Physical AI & Robotics" - 톱니바퀴와 우상향하는 계단식 그래프 아이콘과 함께 피지컬 AI 및 로봇 공학의 구조적 성장 선언.
[Section 3: Core Participating Companies & Technology Deep Dive]
이미지 하단과 좌측에는 엔비디아 가속기 칩셋 아이콘(중앙 부근)을 중심으로 거미줄처럼 회로가 연결된 6개 핵심 참여 기업의 기술 분석 박스가 배치되어 있습니다.
① SAMSUNG ELECTRONICS (SAMSUNG) - 'Total AI Solution' Leverage
Visuals: 신라호텔 아이콘, 3D 구조의 반도체 다이 및 HCB(Hybrid Copper Bonding) 패키징 레이어 일러스트, 반도체 웨이퍼 칩.
Core Tech Bullet Points:
Exclusive Memory + Foundry + Packaging Turn-key (메모리, 파운드리, 패키징을 아우르는 전 세계 유일의 원스톱 턴키 인프라 보유)
HBM4 & Foundry 2nm Sync (차세대 HBM4와 파운드리 2나노 공정의 결합)
Dual Sourcing Key to NVIDIA (TSMC 독점을 깨기 위한 엔비디아의 필수 듀얼 소싱 카드)
② SK GROUP (SK HYNIX / SK TELECOM) - 'AI Kkanbu' Solidification
Visuals: HBM 적층 칩 일러스트 및 촘촘하게 연결된 글로벌 네트워크 노드 아이콘.
Core Tech Bullet Points:
HBM3E/4 Leadership (Advanced MR-MUF) (독보적인 MR-MUF 공정 노하우 기반의 HBM 시장 지배력)
On-Device Memory Chain (LPDDR5X) (RTX 스파크 등 에지 컴퓨팅용 초저전력 모바일 메모리 체인 선점)
Manufacturing AI Services (제조 분야의 AI 인프라 서비스 협력 고도화)
③ LG GROUP - 'Auto & Appliance AI' Leadership
Visuals: 가전용 스마트 로봇(CLOiD 형태), 전기차(EV) 세단 일러스트, 방패 모양의 테크 보안 아이콘.
Core Tech Bullet Points:
EV 전장 (VS) Integration (엔비디아 드라이브 토르 기반의 차량용 중앙 집중형 컴퓨터 시스템 통합 기술)
NVIDIA DRIVE & CLOiD Robot (엔비디아 자율주행 및 Isaac 로봇 플랫폼을 이식한 휴머노이드 로봇)
Vision AI Cameras (LG Innotek) (야간·역광 등 로우 그레이드 환경에서 노이즈를 제어하는 고성능 비전 카메라 모듈)
④ HYUNDAI MOTOR GROUP - 'Smart Factory & SDV' Advancement
Visuals: 컨베이어 벨트와 로봇 팔이 가동 중인 자동화 공장 빌딩, 와이파이 센서가 부착된 자율주행 차량.
Core Tech Bullet Points:
Omniverse Digital Twins (HMGICS) (싱가포르 혁신센터에서 검증된 가상 공간 1:1 디지털 트윈 공정 최적화)
Robot Co-operation (생산 인프라 내에서 스스로 판단하고 움직이는 로봇 협업 시스템)
Level 4 Autonomous Driving (Motional) (모셔널 플랫폼에 엔비디아 소프트웨어를 이식한 레벨 4 자율주행 양산화)
⑤ NAVER - 'Sovereign AI' Infra Partner
Visuals: 정육면체 형태의 데이터 알고리즘 블록, 클라우드 서버 인프라에서 위로 뻗어나가는 업로드 화살표 아이콘.
Core Tech Bullet Points:
Nemotron + HyperCLOVA X Link (엔비디아 오픈 LLM 네모트론과 네이버 하이퍼클로바X의 이종 모델 최적화)
AI Factory for Asia & Middle East (비영어권 국가의 문화와 규제에 맞춘 소버린 AI 및 클라우드 패키지 공동 수출)
⑥ DOUSAN ROBOTICS - 'Robotics Leap'
Visuals: 정밀하게 꺾이는 다관절 산업용 로봇 팔(Manipulator)과 구동 톱니바퀴 일러스트.
Core Tech Bullet Points:
NVIDIA Isaac Platform Integration (엔비디아 로봇 특화 플랫폼 아이작과의 소프트웨어 연동)
Collaborative Robot Control (1mm 이하의 오차 범위 내에서 실시간으로 반응하는 로우레벨 펌웨어 및 정밀 토크 제어)
⑦ GAME INDUSTRY - 'On-Device AI PC' Cycles
Visuals: 총기를 들고 미래형 전투 슈트를 입은 남녀 게임 캐릭터 일러스트(크래프톤의 배틀그라운드 오마주).
Core Tech Bullet Points:
NVIDIA ACE (Digital Humans) (사용자 그래픽카드의 텐서 코어를 활용한 로컬 단에서의 디지털 휴먼 구동)
AI Companions (e.g., KRAFTON) (서버 지연 없는 온디바이스 SLM 기반의 실시간 대화형 AI 동료 시스템 구현)
[Footer - Analyst's Final Advice]
"30-YEAR ANALYST’S FINAL ADVICE: FOCUS ON FUNDAMENTALS, ADJUST DURING CORRECTIONS, CATCH REAL-WORLD ADOPTION"
(이미지 최하단을 가로지르는 짙은 그린색 바의 문구로, 테마성 소음에 흔들리지 말고 기업의 펀더멘털에 집중하며, 시장 조정기를 이용해 비중을 조절하고, 현실 세계에 AI 하드웨어가 실제로 적용 및 채택되는 시점을 포착하라는 30년 차 애널리스트의 최종 조언)](https://econoel-library.com/wp-content/uploads/2026/06/image-19.png)

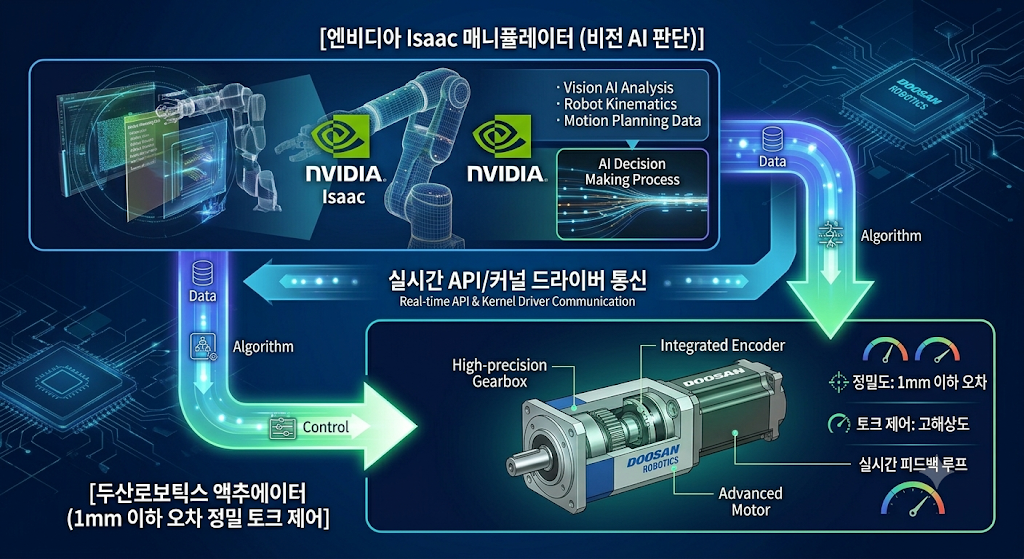

![컴퓨텍스 2026을 기념하여 제작된 반도체 가치사슬(Value Chain) 인포그래픽 이미지입니다. 'IP 아키텍처에서 물리적 AI로의 패러다임 전환'을 주제로, 글로벌 빅테크 기업들이 한국의 하드웨어 및 OSAT(반도체 후공정) 독점 구조에 어떻게 의존하고 있는지 설명하고 있습니다. 다크 블루 배경에 세련된 네온 블루, 그린, 퍼플 컬러가 강조된 프리미엄 미래지향적 디자인입니다.
[상세 구조 및 텍스트 정보]
헤더 영역
상단 타이틀: COMPUTEX 2026 SEMICONDUCTOR INSIGHT
메인 타이틀: The Paradigm Shift: From IP Architecture to Physical AI
서브 타이틀: How Global Big Techs Depend on South Korea's Hardware & OSAT Monopoly
3대 핵심 거시 지표 요약 카드 (상단)
01 HBM4 Monopoly: SK hynix & Samsung lock in Vera Rubin supply chains. (SK하이닉스와 삼성이 엔비디아 베라 루빈 공급망을 선점하고 있음을 명시)
02 CXL 3.1 Breakthrough: Breaking the Memory Wall via PCIe infrastructure standard. (PCIe 인프라 표준을 통해 메모리 벽을 깨는 기술 혁신)
03 Advanced OSAT Expansion: Hanmi Semiconductor's tech controls micro-warpage issues. (한미반도체의 기술이 마이크로 워피지/반전 문제를 제어함)
엔드투엔드 AI 반도체 가치사슬 흐름도 (중앙)
좌측에서 우측으로 갈수록 자본과 기술적 의존도가 흐르는 4단계 구조입니다.
STEP 1: IP & ARCHITECTURE ("The Buyers of Hardware")
NVIDIA: Vera Rubin (VR200), RTX Spark Superchip
INTEL & AMD: Intel 18A (PowerVia), Ryzen AI Max 400
STEP 2: CHIP & MEMORY GIANT ("Pricing Power Keepers")
SK hynix: 16-Layer HBM4 (MR-MUF), TSMC 3나노 Base Die Co-op
SAMSUNG ELECTRONICS: Complete Turn-key Solution, 7th Gen HBM4E & CXL 3.1
STEP 3: PREMIUM OSAT & EDGE ("The Hidden Weapon Masters")
HANMI SEMICONDUCTOR: Wide TC Bonder Monopoly
NEOSEM & EXICON: Next-Gen CXL 3.0 Testers
DEEPX: High-Efficiency Edge NPU
STEP 4: PHYSICAL AI ERA
Robotics, Autonomous Fabs, and Agentic PC (로봇 공학, 자율형 팹, 에이전틱 PC로 연결되는 물리적 AI 시대 기술 적용)
하단 섹션: 자산 배분 전략 및 전문가 평론
RECOMMENDED CXL ASSET ALLOCATION (추천 CXL 자산 배분 바 차트)
NEOSEM (50%), EXICON (20%), ASICLAND (20%), TLB (10%)
하단 주석: 차세대 메모리 병목 현상을 타겟으로 한 다변화된 방어 전략
투자 대가의 직관적 매크로 평론
"Big Techs are rushing to draw the blueprints for Agentic AI, but the real structural wealth is flowing straight into South Korea's Hardware and High-End Back-End Infrastructure Monopoly."
(해석: 빅테크 기업들이 에이전틱 AI의 청사진을 그리기 위해 질주하고 있지만, 실제 구조적인 부는 한국의 하드웨어 및 고엔드 후공정 인프라 독점권으로 곧장 흘러 들어가고 있다.)](https://econoel-library.com/wp-content/uploads/2026/06/image-2.png)
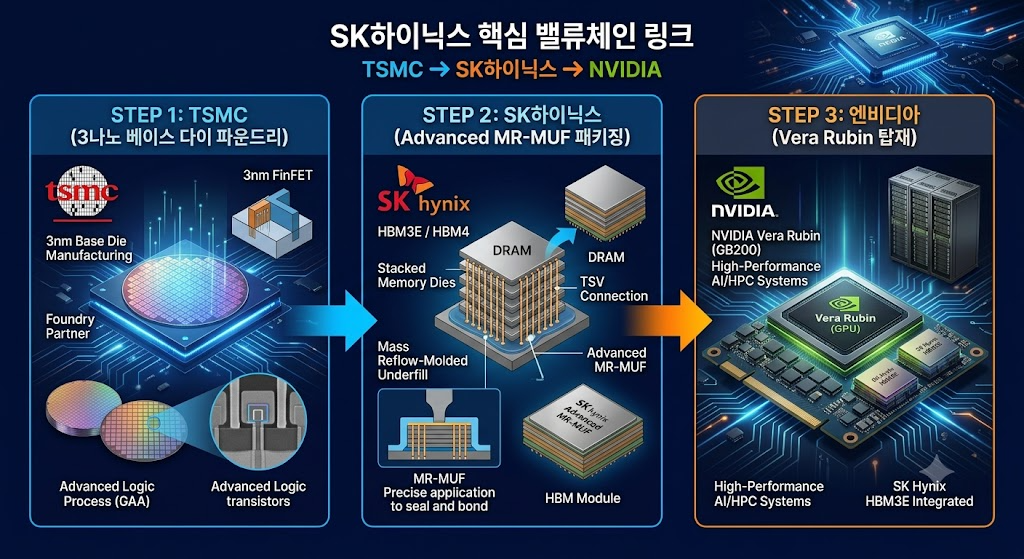
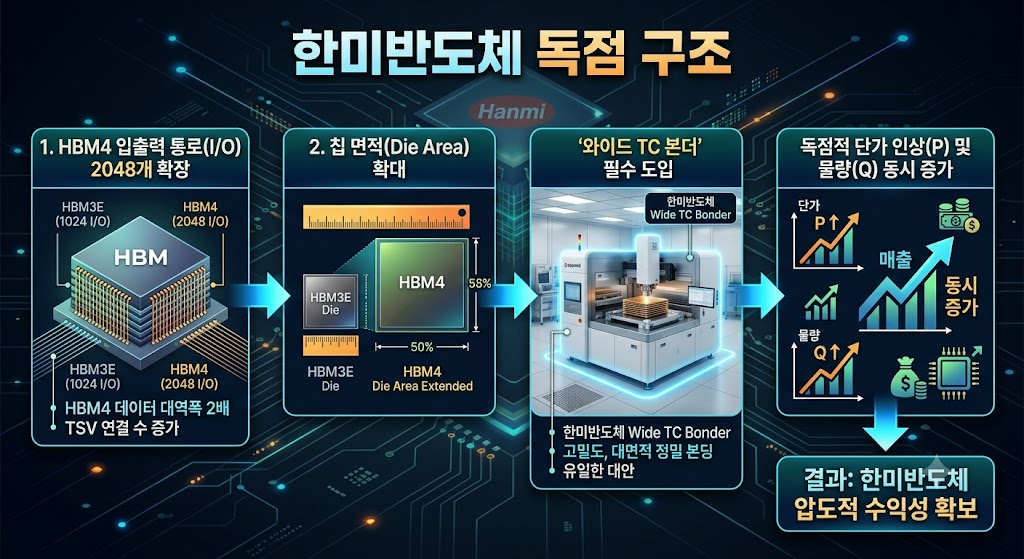
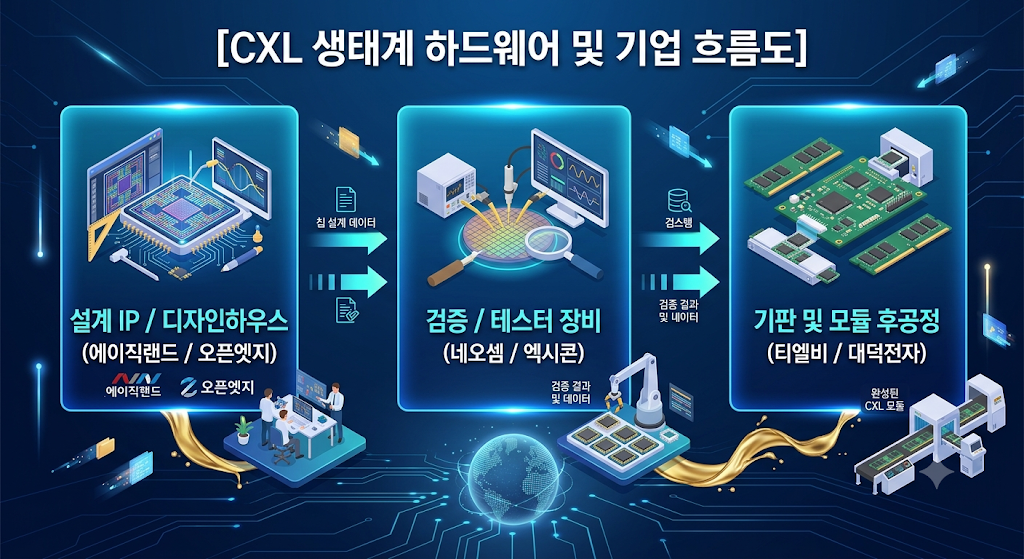
![차세대 HBM 기술 중 HBM4 & HBM4E 기술 비교 및 삼성 혁신 인포그래픽 상세 대체 텍스트
[전체 구성 요약]
이 인포그래픽은 어두운 배경에 파란색, 보라색, 금색 액센트를 사용한 현대적인 디지털 스타일로 디자인되었으며, 크게 네 부분으로 나뉩니다. 상단은 HBM4와 HBM4E의 세대별 성능 및 사양 비교, 중앙은 제조 공정상의 난제('지옥의 레이스'), 하단은 삼성전자의 핵심 혁신 기술(턴키 시너지 및 습식 ALE 하이브리드 본딩), 그리고 최하단은 최근 성과(세계 최초 HBM4E 12단 샘플 출하)를 다룹니다.
[상단: HBM4 & HBM4E 세대별 기술 비교]
두 개의 세로 열이 HBM4(6세대)와 HBM4E(7세대)를 비교합니다.
왼쪽 열: HBM4 (6TH GEN): REGULATORY LEAP (규격의 도약)
아이콘과 텍스트로 구성된 사양 리스트:
2,048-BIT INTERFACE (HBM3E 대비 2배 확장)
핀당 최대 속도 ~10-14 Gbps
단일 스택 대역폭 ~2.5-3.0 TB/s
용량: 36GB (12단) / 48GB (16단)
베이스 다이 공정: 4nm 파운드리 (로직 다이)
일러스트레이션: 4나노 로직 베이스 다이 위에 여러 층의 D램이 쌓여 있는 HBM4 칩 스택 구조. 'Ultra-thin DRAM'과 '4nm Logic Base Die' 라벨이 있습니다.
오른쪽 열: HBM4E (7TH GEN): PERFORMANCE MASTERPIECE (성능의 걸작)
아이콘과 텍스트로 구성된 사양 리스트 (HBM4 대비 향상된 수치는 굵게 표시):
2,048-BIT INTERFACE 기반 최적화 및 속도 향상
핀당 최대 속도 ~16 Gbps
단일 스택 최대 대역폭 ~3.6 TB/s
용량: 48GB (12단) / 최대 64GB (16단)
베이스 다이 공정: 파운드리 4나노 고도화 및 저전력 설계
일러스트레이션: 더 얇은 D램 층이 4나노 베이스 다이 위에 더 촘촘하게 쌓여 있는 구조. 'Ultra-thin DRAM'과 '4nm Base Die' 라벨이 있으며, HBM4보다 더 밀도가 높음을 시각적으로 보여줍니다.
[중앙: PROCESS CHALLENGES ('HELL RACE') - 공정 난제]
두 개의 패널이 기술적 한계를 설명합니다.
왼쪽 패널: ② THICKNESS LIMIT & WARPAGE: 720㎛ (두께 한계 및 휨 현상)
세부 설명: JEDEC 표준 규격 유지 (720㎛), 초고적층(16단)으로 인한 극도의 칩 박막화, 웨이퍼의 종잇장 같은 휨(Warpage) 현상 및 패턴 뒤틀림(Misalignment).
일러스트레이션: 두 개의 얇은 웨이퍼 조각이 서로 다른 방향으로 휘어지는 모습을 시각화한 다이어그램.
오른쪽 패널: ② HEAT DISSIPATION & CMP LIMITS (열 방출 및 CMP 한계)
세부 설명: 촘촘한 적층으로 인한 서멀 스로틀링(과열), 하이브리드 본딩(Cu-Cu)을 위한 CMP 평탄화 공정의 한계.
일러스트레이션: 칩 표면의 구리 패드(Copper pads) 접합 단면 다이어그램. 기존 CMP 공정만 사용 시 구리 패드 표면이 푹 꺼지는 '디싱(Dishing)' 현상을 붉은색 경고선으로 표시했습니다.
[하단: SAMSUNG'S CORE INNOVATIONS - 삼성전자의 핵심 혁신]
두 개의 패널이 삼성의 독창적인 해결책을 설명합니다.
왼쪽 패널: ① TURN-KEY SYNERGY (턴키 시너지)
세부 설명: 자체 메모리(1c D램) + 자체 파운드리 4나노 로직 베이스 다이 + 자체 첨단 패키징(AVP)의 융합 전략.
일러스트레이션: 텍스트 박스들을 화살표로 연결한 프로세스 흐름도: 'IN-HOUSE MEMORY + FOUNDRY 4nm LOGIC BASE DIE'가 'IN-HOUSE 첨단 PACKAGING (AVP)'과 결합합니다. 'IN-HOUSE PACKAGING (AVP)'에서 두 개의 분기 화살표가 성과를 보여줍니다: "Energy Efficiency +16%", "Thermal Resistance +14%".
오른쪽 패널: ② WET ALE (ATOMIC LAYER ETCHING) FOR HYBRID BONDING INNOVATION (하이브리드 본딩 혁신을 위한 습식 원자층 식각)
일러스트레이션 및 텍스트: 중앙에는 'WET ALE' 공정의 분자 수준 식각 메커니즘을 시각화한 다이어그램이 있습니다.
'ENGINEER NOTE' 삽입 박스: 하이브리드 본딩 구리 접합 단면 비교 다이어그램.
왼쪽 (CMP-ONLY (ISSUE)): 물리적 CMP만 사용 시 구리 패드 표면의 디싱(Dishing) 및 절연층(Dielectric) 손상, 빈틈(Void) 발생으로 인한 불량을 보여줍니다.
오른쪽 (CMP + WET ALE (SOLUTION)): ALE 공법 도입 시 원자 단위 평탄화, 구리 표면 거칠기 완벽 제어, 파티클(Minimizes Particles) 감소, 신뢰성 높은 Cu-Cu 본딩을 보여줍니다.
[최하단: RECENT ACHIEVEMENT - 최근 성과]
텍스트: "RECENT ACHIEVEMENT: WORLD'S FIRST HBM4E 12Hi SAMPLE SHIPMENT (May 2026)" (최근 성과: 세계 최초 HBM4E 12단 샘플 출하, 2026년 5월)
일러스트레이션: 작은 지구 아이콘과 함께 전 세계로 뻗어 나가는 성과를 시각화했습니다.
이 인포그래픽은 HBM4와 HBM4E의 차이를 명확히 하고, 공정의 한계를 극복하기 위해 삼성이 어떻게 턴키 역량과 독창적인 ALE 공법을 활용했는지를 논리적으로 보여줍니다.](https://econoel-library.com/wp-content/uploads/2026/05/image-53.png)
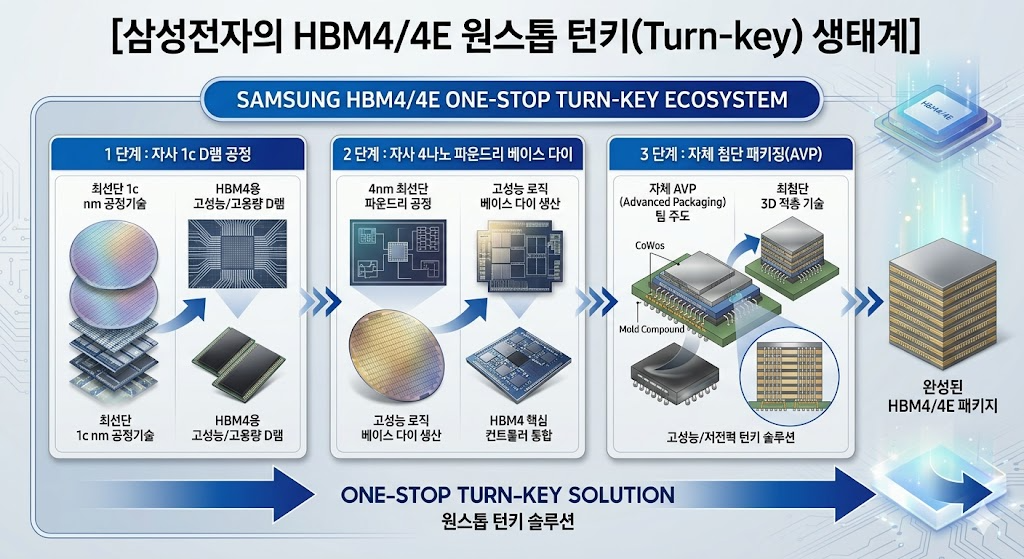
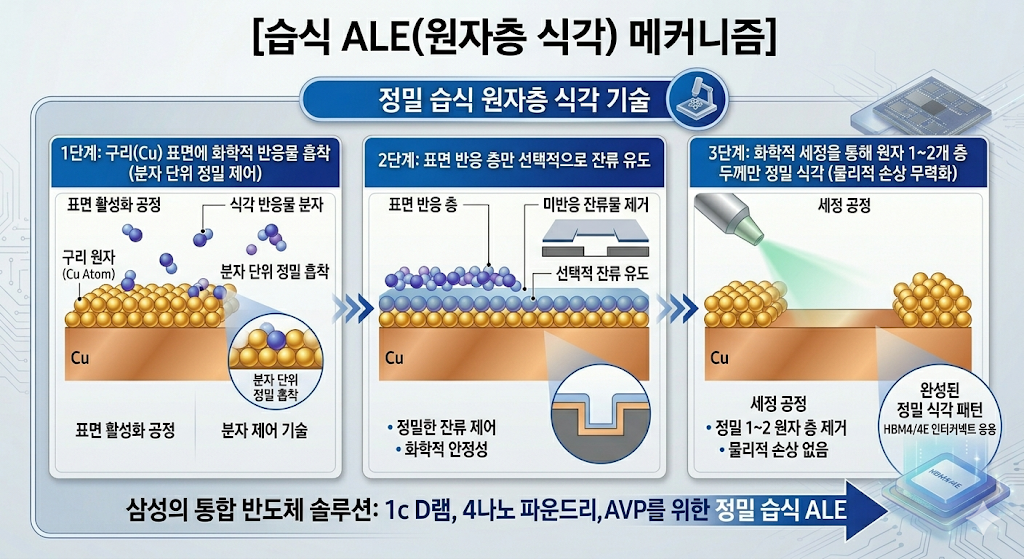

![[인포그래픽 상세 설명]본 이미지는 SK하이닉스의 차세대 iHBM(Integrated HBM) 기술의 구조적 혁신과 발열 해결 메커니즘, 그리고 향후 로드맵을 설명하는 영문 인포그래픽입니다.메인 타이틀: SK hynix iHBM Technology: Solving Heat Issues and Strengthening AI Memory Leadership좌측 핵심 특징:High Bandwidth & Ultra-fast Transfer: AI 연산 속도 향상을 위한 고대역폭 및 초고속 전송 특징을 시계 아이콘으로 시각화.High Design Compatibility: 고객사의 설계 변경을 최소화하는 높은 설계 호환성을 퍼즐 조각 아이콘으로 표현.중앙 아키텍처 다이어그램 (iHBM 구조):HBM5 이상의 16단 고적층 구조(Stack Structure above HBM5)를 나타내며, 기존의 Advanced MR-MUF 공정을 활용함을 명시.3D 칩 구조도에는 최하단에 Interposer와 D2D PHY(물리 계층)가 위치하고, 그 위에 Base Die, 그리고 최상단에 DRAM Core Dies가 적층된 구조가 묘사됨.Base Die 내부의 D2D PHY 영역에서 발생하는 'Hot-spot(열 집중 영역)' 바로 옆에 ICE(Integrated Cooling Elements) 소자가 다이어렉트로 결합되어 있음.Direct Cooling via ICE: ICE 소자가 태양 아이콘으로 표현된 고열을 직접 흡수하여 우회 배출하는 메커니즘을 붉은색 화살표로 시각화.ICE의 상세 정의: 높은 열전도율을 가진 더미 실리콘(Integrated Cooling Dummy Silicon with high thermal conductivity)으로 명시.정량적 효과: 이 구조를 통해 열저항이 30% 이상 감소(Over 30% Thermal Resistance Reduction)하여 안정적인 작동(Stable Operation)이 가능함.우측 핵심 특징 및 정성적 효과:Excellent Mass Producibility: 기존의 공정 인프라를 그대로 활용(Utilization of Existing Process Infrastructure)하여 우수한 양산성을 확보함을 공장 아이콘으로 표현.AI Memory Leadership Consolidation: SK하이닉스 이강욱 부사장의 "글로벌 리더십 강화(Strengthening Global Leadership)" 코멘트와 상승하는 그래프 아이콘을 통해 AI 메모리 시장 주도권 공고화를 강조.하단 HBM 로드맵 타임라인:HBM3E $\rightarrow$ HBM4 $\rightarrow$ HBM5 (iHBM Applied) 순으로 발전하는 로드맵을 보여주며, HBM5 단계부터 iHBM 기술이 본격 적용됨을 주황색 화살표로 강조함.](https://econoel-library.com/wp-content/uploads/2026/05/image-40.png)
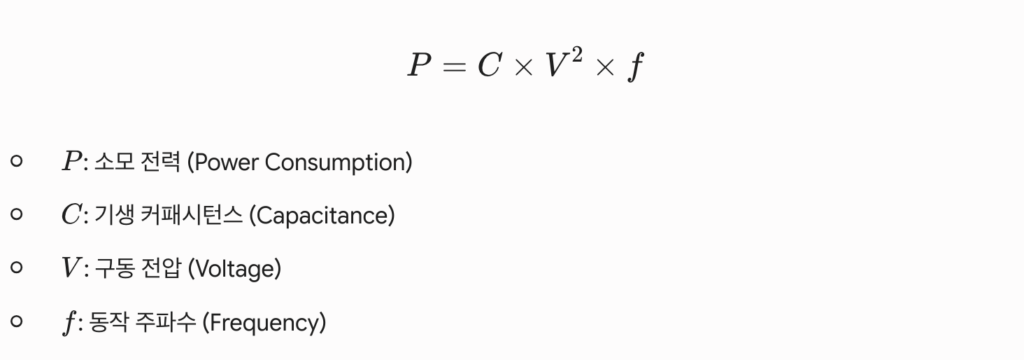
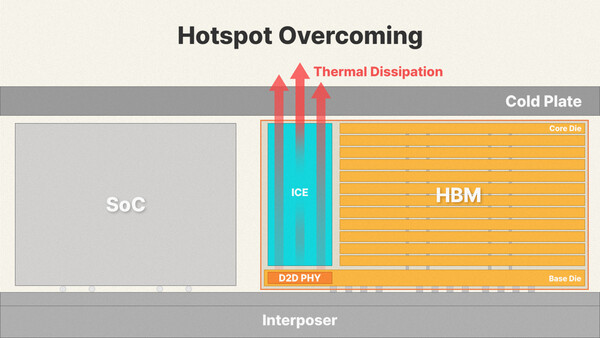
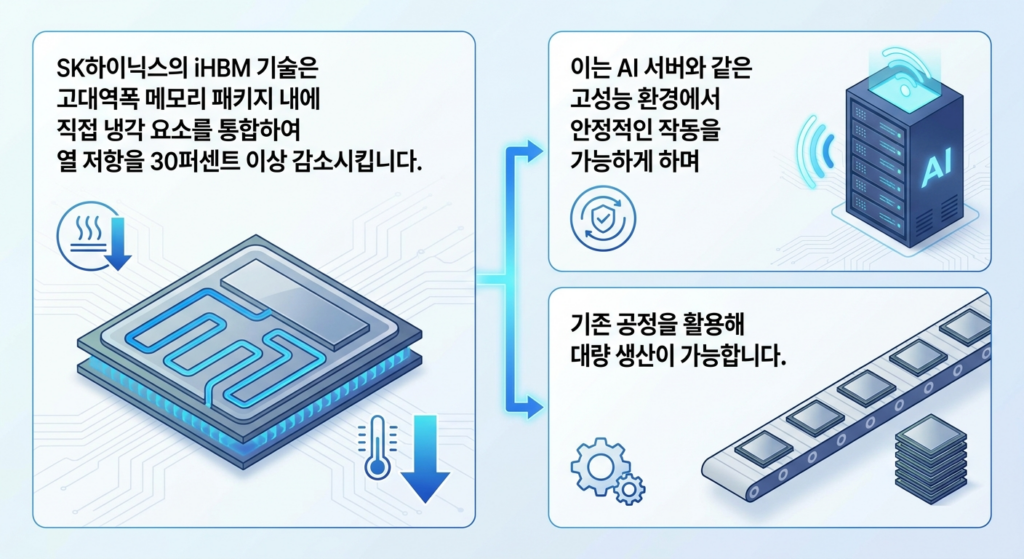
![📊 Infographic Blueprint: 구글 I/O 2026 Core Value Chain
🎨 Design Concept & Theme
Color Palette: Deep Cyber Blue (Background), Neon Cyan (Tech/Hardware), Bright Green (Profit/SaaS), Coral Red (Risks).
Layout: A structured 3-tier vertical flowing chart or a horizontal dashboard that visualizes the transition from "Infrastructure" to "Value".
[Header]
GOOGLE I/O 2026: THE GREAT AI PARADIGM SHIFT
Subtitle: From "Cost-Burning Calculators" to "Profit-Generating Autonomous Agents"
[Section 1] 🚀 Core Technology Pillars
(Visual: Two main blocks side-by-side with minimal architectural icons)
Gemini 3.5 Flash: The Cost Killer
Tech Engine: Knowledge Distillation & Quantization ($FP16 \rightarrow INT8$).
Impact: 4x Faster Speed / 50%+ Cost Reduction.
Gemini Omni: Native Multimodal
Tech Engine: End-to-End single neural network processing.
Impact: Zero information loss / Real-time Video & Audio Remix.
Agentic AI Loops
Workflow: [User Intent] $\rightarrow$ [Reasoning & Planning] $\rightarrow$ [Tool Use / API Calls] $\rightarrow$ [Self-Verification].
[Section 2] 💰 The Investment Map (Value Chain)
(Visual: A timeline or two-column split layout comparing Short-term vs. Mid/Long-term)
⏱️ Short-Term (1–2 Years): The Revenue Accelerators
ASIC & Custom Chips:
🚀 Broadcom (AVGO): Google's co-development partner for TPU 8.
Next-Gen Infrastructure:
🚀 SK Hynix & Samsung Electronics: High-bandwidth memory ($HBM$) suppliers for TPU 8t.
🚀 Lumentum (LITE) & Coherent (COHR): Providers of OCS (Optical Circuit Switches) for 1M-node clusters.
Software Margin Expansion:
🚀 Top SaaS Players (Salesforce, HubSpot): Immediate OPM (Operating Profit Margin) boost due to halved API costs.
⏳ Mid to Long-Term (3–5 Years): Structural Paradigm Shifters
Edge AI & Next-Gen Form Factors:
🌐 Qualcomm (QCOM): Dominant processor player for Smart Glasses.
🌐 LG Innotek & Largan Precision: High-performance, low-power camera modules & AR waveguides.
AI Security & Protocols:
🌐 CrowdStrike, Palo Alto Networks, Adobe: Mainstreaming of AI watermarking (SynthID) and deepfake defense verification.
[Section 3] ⚠️ Critical Investor Risks
(Visual: A warning dashboard or dual-gauge chart indicating hidden operational bottlenecks )
NVIDIA (NVDA) Multiple Cooling:
As Big Tech pivots heavily to internal ASIC ecosystems (like TPU 8), NVIDIA's extreme monopoly margins may normalize over time.
The Power Grid & Cooling Bottleneck:
The real ceiling for a 1-million-chip cluster is Electricity Supply and Thermal Management, not chip performance.
⭐ Hidden Beneficiaries: Constellation Energy (CEG) [Nuclear Power] & Vertiv (VRT) [Liquid Cooling Solutions].
[Footer / Key Takeaway]
📌 "AI has crossed the chasm from spending money to making money. Bet on custom silicon infrastructure in the short term, and pivot to energy, liquid cooling, and edge devices for the long game."](https://econoel-library.com/wp-content/uploads/2026/05/image-19.png)