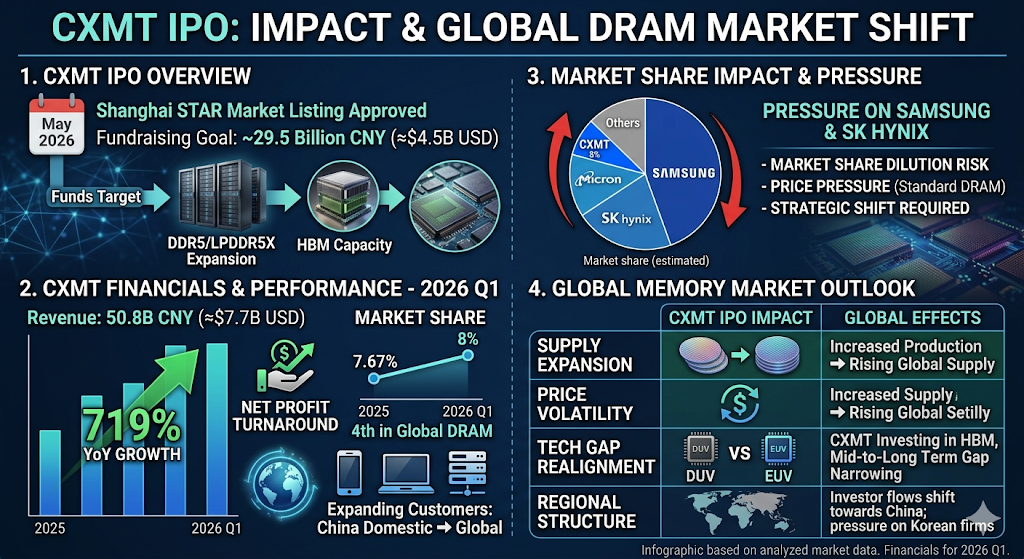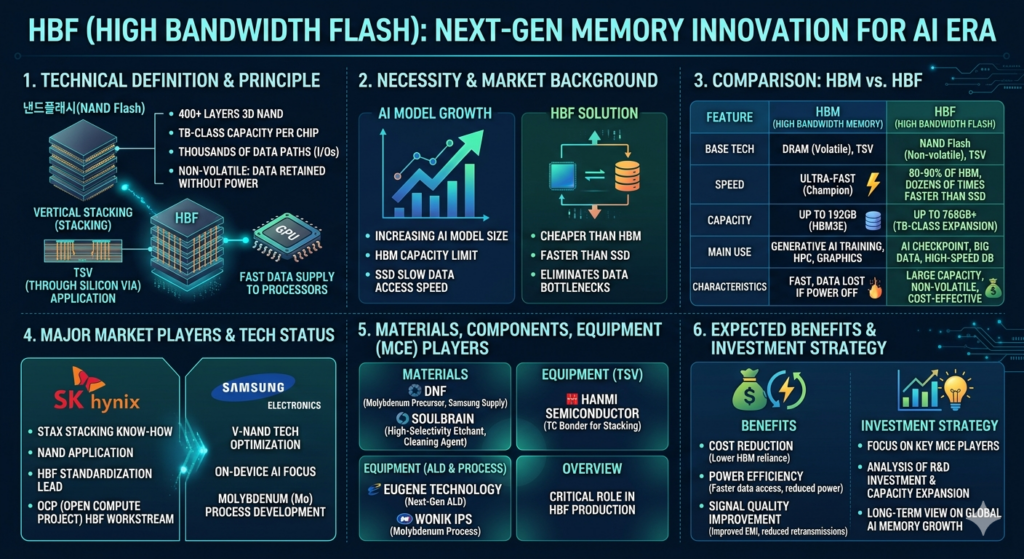
최근 KAIST의 김정호 교수님께서 제안하신 새로운 메모리 로드맵, 특히 세계 최초로 공개된 HBS(High Bandwidth SRAM)와 차세대 게임 체인저로 꼽히는 HBF(High Bandwidth Flash)는 단순히 “새로운 반도체가 나온다”는 수준의 뉴스가 아닙니다.
이것은 인류가 반세기 동안 유지해 온 반도체 연산 아키텍처인 ‘폰 노이만 구조(Von Neumann Architecture)’의 한계, 즉 ‘메모리 벽(Memory Wall)’을 완전히 깨부수겠다는 선언입니다.
투자자분들이라면 이 포스팅을 끝까지 정독하시고, 미래 반도체 패러다임 전쟁의 승자가 누구일지 힌트를 얻어가시기 바랍니다.
👤 1. HBM의 개척자, 김정호 KAIST 교수는 누구인가?
기술의 본질을 이해하려면 그 기술을 제안한 사람의 궤적을 봐야 합니다. 김정호 KAIST 교수는 단순한 학자가 아닙니다. 이론과 실무를 모두 겸비한, 대한민국 반도체 역사의 살아있는 산증인입니다.
- 삼성전자 D램 수석연구원 출신: 현업에서 직접 메모리 칩이 구르고 데이터가 흐르는 실전 공정을 경험했습니다.
- 1996년 KAIST 부임 이후 메모리 외길: 30년 가까이 초고속 패키징과 신호 무결성을 연구해 왔습니다.
- ‘테라랩(Tera Lab)’의 업적: 현재 전 세계 AI 시장을 독점하고 있는 엔비디아 GPU의 필수재인 HBM(High Bandwidth Memory) 아키텍처 10여 개 중 상당수가 바로 이 테라랩의 연구 성과와 가이드라인에서 탄생했습니다.
쉽게 말해, 2000년대 초반 업계 모두가 “비싸서 저걸 어디다 쓰냐”, “공정이 너무 복잡해 불가능하다”라고 고개를 저을 때, HBM의 개념적 기반을 닦고 SK하이닉스와 협력해 2013년 세계 최초 상용화의 기틀을 마련한 장본인입니다. 따라서 그가 던지는 “새로운 메모리 개념”은 단순한 학술적 아이디어가 아니라, 향후 10~20년 뒤 글로벌 빅테크 기업들이 천문학적인 돈을 쏟아부을 산업의 이정표(Milestone)로 봐야 합니다.
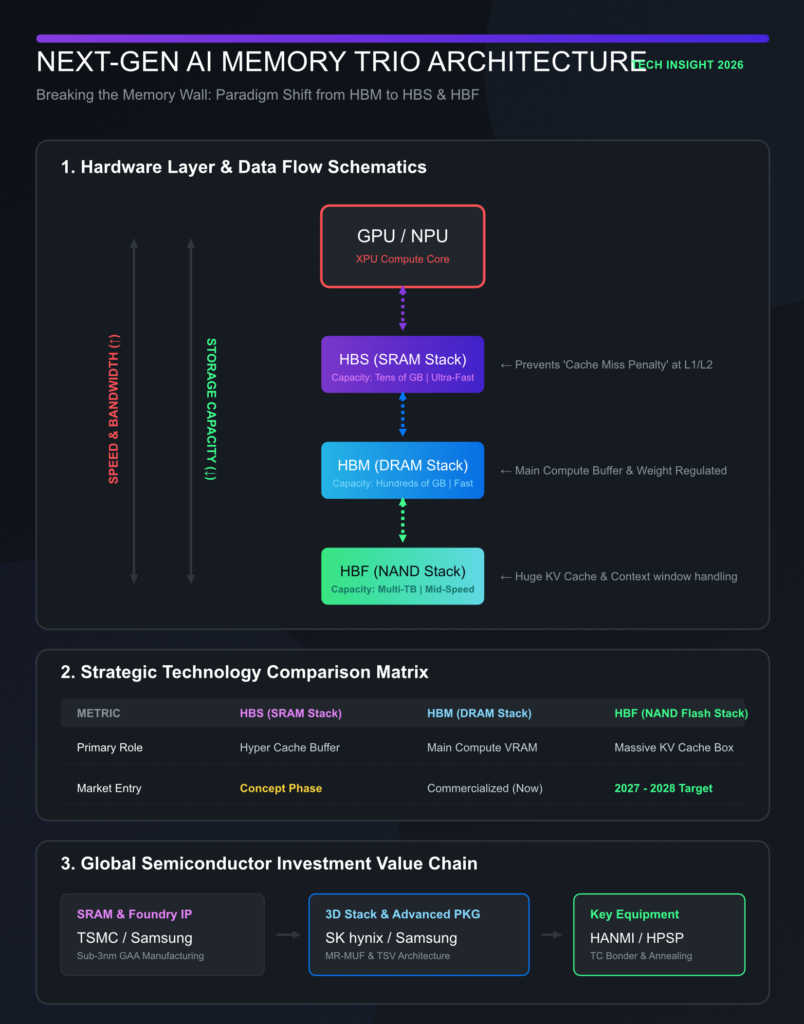
🔬 2. 핵심 기술 심층 분석: HBM, HBF, 그리고 HBS 삼각편대
AI 모델이 고도화될수록 연산 장치(GPU, NPU)의 속도보다 메모리가 데이터를 보내주는 속도가 느려 전체 시스템 성능이 저하되는 ‘메모리 벽(Memory Wall)’ 현상이 심화됩니다. 김정호 교수는 이를 극복하기 위해 기존 HBM을 넘어 HBF, HBS로 이어지는 거대한 3차원 적층 메모리 생태계를 제시했습니다. 각 기술의 본질적 메커니즘을 쪼개어 분석해 보겠습니다.
① HBM (High Bandwidth Memory): 현재의 왕좌와 신호 무결성의 전쟁
HBM은 단순히 D램 칩을 수직으로 쌓아 올린 구조가 아닙니다. 물리적 한계에 부딪힌 데이터 전송 속도를 극복하기 위해 ‘도로의 개수(데이터 버스)’를 극단적으로 늘린 아키텍처입니다. 기존 일반 D램(DDR5 등)이 32개 또는 64개의 도로로 데이터를 주고받았다면, HBM은 1,024개(HBM3 및 HBM4 기준)의 촘촘한 버스를 활용합니다.
이 구조를 가능하게 만드는 핵심 4대 요소는 다음과 같습니다.
- TSV (실리콘 관통 전극): 머리카락 수십 분의 일 굵기로 D램 칩 내부를 수직으로 관통하는 수천 개의 미세한 구멍을 뚫어 전기를 통하게 하는 기술입니다. 와이어 본딩 방식에 비해 데이터 이동 거리를 줄이고 대역폭을 극대화합니다.
- 인터포저 (Interposer): 미세한 회로를 품고 있는 실리콘 판대기입니다. 메인 기판 위에 인터포저를 올리고, 그 위에 GPU와 HBM을 수평으로 아주 가깝게 배치하여 초고속 신호를 중계합니다.
- 로직 다이 (Logic Die / 베이스 다이): HBM 적층 스택의 맨 밑바닥에 위치하는 교통경찰입니다. 위층의 D램들로부터 들어오는 엄청난 데이터 흐름을 제어하고 GPU와 동기화시킵니다.
- 적층 최적화 (SI/PI): 김정호 교수 연구실의 핵심 기여 분야입니다. 칩들이 너무 미세하고 조밀하게 붙어있다 보니, 수 기가헤르츠(GHz)로 구동할 때 전자기학적 잡음인 크로스토크(Crosstalk: 신호 간섭 현상)가 발생해 데이터가 깨집니다. 또한, 전력 공급 시 미세한 저항과 기생 커패시턴스로 인해 신호가 왜곡되는 현상이 일어납니다. 이를 시뮬레이션하고 잡음을 제어해 신호 무결성(Signal Integrity, SI)과 전력 무결성(Power Integrity, PI)을 확보하는 것이 HBM 수율의 핵심입니다.
② HBF (High Bandwidth Flash): 낸드플래시의 대역폭 혁명과 KV 캐시의 구원자
ChatGPT와 같은 대규모 언어 모델(LLM)이 문맥을 이해하고 자연스러운 답변을 생성하려면, 이전에 주고받았던 대화 데이터와 변수들을 실시간으로 기억하고 있어야 합니다. 이를 ‘KV 캐시(Key-Value Cache)’라고 부릅니다.
문제는 트랜스포머(Transformer) 기반 AI 모델의 파라미터가 커지고 문맥 창(Context Window)이 길어질수록 이 KV 캐시 용량이 기가바이트(GB) 단위를 넘어 테라바이트(TB) 급으로 폭증한다는 점입니다. 현재 최고 사양의 GPU에 들어가는 HBM 용량(96GB~141GB 수준)으로는 이 거대한 캐시 데이터를 모두 담지 못합니다. 캐시 메모리가 부족하면 GPU는 데이터를 하드디스크나 일반 SSD에서 가져와야 하므로 연산 속도가 처참하게 떨어집니다. 즉, GPU 성능이 아무리 좋아도 메모리 용량 부족으로 노는 현상이 발생합니다.
이때 구원투수로 등장하는 것이 바로 HBF(High Bandwidth Flash)입니다.
- 구조적 특징: HBM의 적층 메커니즘을 낸드플래시(NAND Flash)에 적용하는 것입니다. 낸드는 D램보다 직접도가 10배 이상 높아 대용량 구현에 압도적으로 유리하며 가격도 저렴합니다. 낸드를 TSV로 묶고 초고속 인터페이스를 결합해 대역폭을 넓히면, “HBM보다는 느리지만 일반 SSD보다 압도적으로 빠르며, 용량은 HBM의 10배 이상인 거대한 버퍼 메모리”가 탄생합니다.
- 치명적인 과제 – 쓰기 수명(Endurance): 낸드플래시는 셀(Cell) 내부에 전자를 가두거나 빼내는 방식(Floating Gate 또는 Charge Trap)을 사용합니다. 데이터를 쓰고 지울 때마다 절연체 역할을 하는 산화막이 미세하게 손상됩니다. AI 추론 과정에서는 매 순간 KV 캐시가 갱신(쓰기 작업)되므로, 일반적인 낸드 공정으로는 몇 달 만에 칩이 수명을 다해 죽어버릴 수 있습니다.
- 해결 책: 이를 극복하기 위해 쓰기 수명이 상대적으로 매우 긴 SLC(Single Level Cell) 캐싱 레이어를 융합하거나, 데이터 분산 저장 효율을 극대화한 고도화된 웨어 레벨링(Wear Leveling) 컨트롤러 아키텍처 기술이 HBF의 성패를 가를 절대적 열쇠가 될 것입니다.
- 상용화 타임라인: 김정호 교수는 2026년 현재 고성능 샘플 공급이 시작되어, 2027~2028년에는 엔비디아나 AMD의 차세대 GPU 인프라에 HBF가 본격 탑재될 것으로 전망합니다. 궁극적으로 2030년대 초반에는 HBM과 HBF가 하나의 패키지 안에서 결합한 하이브리드 제품이 등장하고, 추론 중심 시장이 폭발하는 2038년경에는 HBF의 시장 규모가 HBM을 추월할 것이라는 충격적인 예측을 내놓았습니다.
③ HBS (High Bandwidth SRAM): 미세화의 한계를 깨는 세계 최초의 초초고속 아키텍처
김정호 교수가 이번 인터뷰를 통해 최초로 외부에 공개한 개념인 HBS(High Bandwidth SRAM)는 반도체 엔지니어들에게 전율을 일으키는 아키텍처입니다.
SRAM(Static RAM)은 전류만 공급되면 데이터가 유지되는 플립플롭 구조(통상 6개의 트랜지스터로 1비트 구성)로, 전하를 충전하는 방식이라 주기적으로 리프레시(Refresh)를 해줘야 하는 D램과 다릅니다. 지연 시간(Latency)이 나노초(ns) 미만으로 반도체 중에서 가장 빠르기 때문에 CPU와 GPU 내부의 핵심 캐시(L1, L2, L3 캐시)로 사용됩니다.
하지만 큰 문제가 있습니다. ‘SRAM 스케일링 저하(Scaling Out)’ 현상입니다.
반도체 미세 공정이 3나노, 2나노 이하 초미세 영역으로 진입하면서 연산 트랜지스터의 크기는 극적으로 줄어들고 있지만, SRAM 셀의 크기는 물리적 전력 누설과 간섭 문제로 인해 거의 줄어들지 않고 있습니다. 이 때문에 온칩(On-chip, 프로세서 다이 내부)에 대용량 SRAM을 넣으려고 하면 GPU 전체 면적이 너무 커져 생산 수율이 박살 나고 단가가 천문학적으로 치솟습니다. 엔비디아의 블랙웰(Blackwell) 같은 칩 내부 구조를 보면, 연산 장치만큼이나 넓은 면적을 SRAM 캐시가 차지하고 있는 이유가 바로 이 때문입니다.
김정호 교수가 제시한 돌파구는 단순 명쾌하면서도 파괴적입니다. “안 줄어들면, 밖으로 빼서 위로 쌓는다”는 것입니다.
- 메커니즘: 프로세서 다이 내부에 구겨 넣던 SRAM 캐시를 과감히 분리하여, HBM의 검증된 3D TSV 적층 기술을 통해 밖에서 수직으로 쌓아 올립니다. 이를 초고속 인터포저 위에서 GPU 코어와 동기화시키는 구조가 바로 HBS입니다.
- 기대 효과: SRAM의 낮은 구동 전압과 극도의 스위칭 속도를 활용해 TSV 인터페이스를 극한으로 가속하면, HBM을 가볍게 짓밟는 수 테라바이트($\text{TB/s}$) 수준의 울트라 대역폭을 확보할 수 있습니다. 면적 제약으로 수백 메가바이트(MB) 수준에 갇혀있던 온칩 캐시 용량을 수십 기가바이트(GB) 급의 ‘초대형 하이퍼 캐시(Hyper Cache)’로 확장할 수 있게 됩니다.
- 캐시 미스 페널티(Cache Miss Penalty)의 소멸: 연산 코어가 데이터를 찾을 때 내부 캐시에 없으면 외부 D램(HBM) 영역으로 나가야 하는데, 이때 막대한 시간 지연인 캐시 미스 페널티가 발생합니다. HBS는 코어 바로 옆에서 기가바이트급의 초고속 완충 지대 역할을 수행하여 연산 유닛(ALU)의 가동률을 100%에 가깝게 유지해 줍니다.
🧠 3. 미래 AI 연산 시스템 메모리 계층도 (HBS-HBM-HBF 삼각편대)
HBS와 HBF가 상용화되면 미래의 AI 데이터센터 및 추론 가속기는 완벽하게 재편된 4단계의 메모리 하이러키(Hierarchy) 구조를 가지게 됩니다. 데이터의 흐름과 역할 분담을 직관적으로 도식화해 보겠습니다.
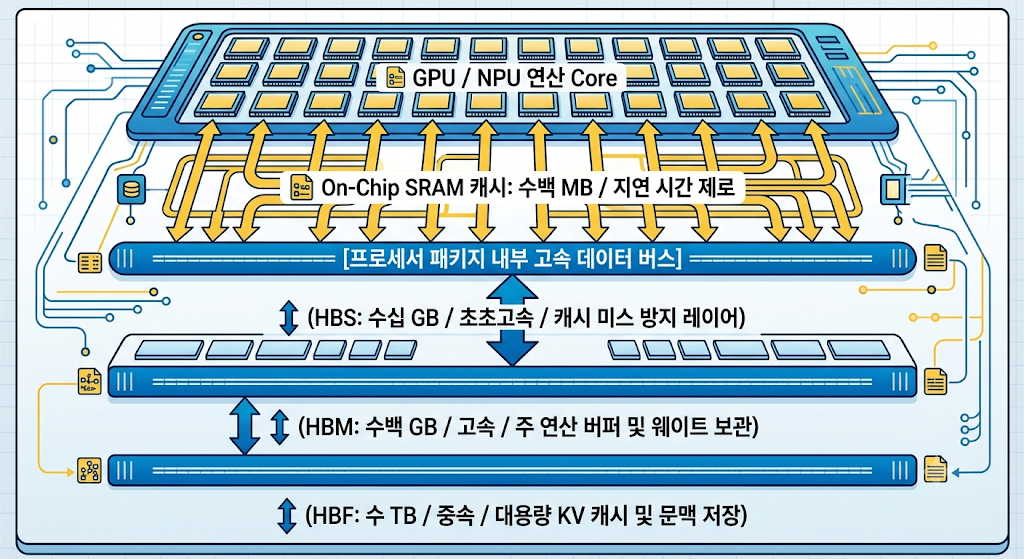
🔄 실제 AI 추론 연산 시 데이터 흐름 시나리오
- HBF (낸드 적층): 거대한 초거대 AI 모델의 전체 가중치(Weight) 파라미터와 전 세계 수만 명의 사용자가 유발하는 대규모 KV 캐시 데이터를 테라바이트 단위로 대량 저장해 둡니다.
- HBM (DRAM 적층): 현재 연산 사이클에 당장 필요한 활성화 함수 데이터와 일부 레이어의 가중치 데이터를 HBF로부터 고속으로 퍼 올려 연산 대기 상태를 만듭니다.
- HBS (SRAM 적층): GPU 코어가 수 나노초(ns) 내에 처리해야 하는 핵심 변수 및 반복 재사용 데이터들을 HBM에서 아주 미세하게 쪼개어 실시간으로 받아 가며 연산 병목을 원천 차단합니다.
🚀 4. AI 인공위성과 우주 엣지컴퓨팅 비전
김정호 교수의 로드맵 중 가장 미래지향적이면서 스페이스X 일론 머스크의 비전과 맞닿아 있는 부분이 바로 ‘AI 인공위성(우주 마이크로 데이터센터)’ 프로젝트입니다.
현재 위성 기술은 단순히 우주에서 고해상도 지형 사진이나 데이터를 촬영하여 지상국으로 원시 데이터(Raw Data)를 전송하는 수준에 머물러 있습니다. 하지만 우주와 지상국 간의 통신은 대역폭이 극도로 제한적이며 레이턴시(지연 시간)가 길어, 수 테라바이트의 데이터를 지상으로 다 보내 분석하는 것은 불가능에 가깝습니다.
🌌 우주 환경의 극한 조건과 해결책
위성 내부에서 스스로 판단하고 정보를 처리(Edge Computing)하여 최종 결론만 지구로 쏴주는 시스템이 필수적입니다. 하지만 우주 환경은 지상과 완전히 다릅니다.
- 비트 플립(Bit Flip) 현상: 태양풍이나 우주 방사선(Cosmic Ray)으로 인해 반도체 내부의 데이터 전하가 튀어 $0$이 $1$로, $1$이 $0$으로 바뀌는 소프트 오류가 빈번합니다.
- 제한된 전력(Power Constraint): 위성은 태양광 패널로만 에너지를 자급자족해야 하므로 전력 소모를 극한으로 낮춰야 합니다.
김 교수가 구상하는 세계 최초의 AI 인공위성은 저전력 구조의 여러 XPU(다양한 프로세싱 유닛)와 고대역폭·저전력 특성의 HBM을 초고밀도로 클러스터링(Clustering)하는 아키텍처입니다. 지상국의 제어 명령 없이도 위성 스스로 인공지능 연산을 돌려 데이터 처리 경로를 최적화하고 에너지를 관리하는 구조입니다.
일론 머스크가 추진하는 ‘우주 데이터센터용 위성 100만 개 발사’ 계획의 핵심 인프라가 될 수 있는 기술이며, 한국이 HBM 후공정에서 다져놓은 노하우를 방산 및 우주 항공 분야로 전이할 수 있는 초대형 블루오션 시장입니다.
📊 5. 글로벌 반도체 핵심 기업 투자 분석 & 밸류체인 역학 관계
이 거대한 기술 변화의 시나리오에서 어떤 기업들이 막대한 부를 거머쥐고, 어떤 기업들이 위기를 맞이할까요? 엔지니어의 사실 기반 분석과 함께 투자 매력도를 낱낱이 파헤쳐 보겠습니다.
🇰🇷 SK하이닉스 (000660): 패키징 장인의 선제 타격과 이종 집적 동맹
- 엔지니어적 시각: SK하이닉스가 HBM 시장에서 엔비디아를 사로잡으며 판정승을 거둔 일등 공신은 MR-MUF(매스 리플로우-몰디드 언더필) 공정 기술입니다. 칩을 쌓아 올린 후 칩 사이의 미세한 틈을 액체 형태의 보호재로 채워 열 방출 효율을 높이고 신호 잡음을 잡았습니다. 액체 방열재 제어 노하우와 3D TSV 정렬 기술은 타사 대비 확실한 우위에 있습니다.
- HBF 및 HBS 전략: SK하이닉스는 낸드플래시 원천 기술의 강자인 샌디스크(웨스턴디지털)와 HBF 규격 표준화를 위한 MOU를 선제 체결했습니다. 자신들의 ‘칩을 적층하고 신호를 정렬하는 패키징 노하우’에 샌디스크의 ‘엔터프라이즈급 고성능 낸드 셀 기술’을 접목하여 2027년 최초 양산하겠다는 영리한 전략입니다. 파운드리 라인이 약하다는 한계는 TSMC의 초미세 공정을 활용한 ‘이종 집적(Heterogeneous Integration) 패키징 동맹’으로 돌파할 수 있습니다.
- 투자 매력도: 최우선 주목 (★★★★★)
- 주요 리스크: 메모리 업황 사이클에 따른 이익 변동성, HBM 시장 경쟁 심화로 인한 단가 인하 압박.
🇰🇷 삼성전자 (005930): 인프라는 완벽, HBS 시대의 최종 병기이자 잠재 최강자
- 엔지니어적 시각: 삼성전자의 무서움은 메모리(D램/낸드) 설계 및 제조, 파운드리(위탁생산), 그리고 AVP(첨단 패키징) 사업부까지 한 지붕 아래 모두 보유한 지구상 유일한 종합 반도체 기업(IDM)이라는 점입니다. 미래의 HBM4부터는 맨 밑바닥 ‘로직 다이’를 파운드리 초미세 공정(4nm/3nm)으로 제작해야 합니다. TSMC 외주에 의존해야 하는 경쟁사들과 달리 삼성은 완벽한 수직계열화 인프라를 갖고 있습니다.
- HBS의 치트키: 특히 파운드리 기술이 필수가 되는 HBS(SRAM 적층) 영역에서는 삼성의 가치가 폭발합니다. 고집적 SRAM은 3나노 이하 GAA(Gate-All-Around) 공정 역량이 필수적인데, 삼성은 이를 세계 최초로 상용화한 경험이 있습니다. SRAM 셀 제조부터 TSV 적층, 패키징까지 하나의 ‘턴키(Turn-key) 서비스’로 엔비디아나 AMD에 제공할 수 있는 독점적 잠재력을 가집니다. 최근 전영현 DS부문 부회장이 기술 연구원들을 이끌고 김정호 교수를 주기적으로 방문해 자문을 구하는 행보는 과거의 수율 실패를 인정하고 기초 체력(SI/PI 설계 설계 자산)을 다져 백 투 더 베이직(Back to the basic)하겠다는 강력한 부활의 시그널입니다.
- 투자 매력도: 저평가 매력 및 장기 수혜 (★★★★☆)
- 주요 리스크: 부서 간 유기적 융합과 실전 공정 수율 확보(실행력)의 검증 필요.
🇺🇸 샌디스크 (웨스턴디지털 분사 법인): 낸드 원천 기술과 데이터센터의 키플레이어
- 엔지니어적 시각: 샌디스크는 일본의 키옥시아(구 도시바)와 함께 낸드플래시의 원천 특허와 핵심 생산 공장(Yokkaichi Fab)을 공유해 온 낸드의 명가입니다. 최근 AI 서버용 고용량 엔터프라이즈 SSD(eSSD) 수요 폭발로 데이터센터향 매출이 전 분기 대비 233%나 폭증하며 펀더멘털을 증명했습니다.
- HBF에서의 역할: 이들은 낸드 셀 자체의 물리적 한계인 ‘쓰기 수명 수명(Endurance)’을 칩 제어 레벨에서 극복할 수 있는 고성능 컨트롤러 설계 자산을 보유하고 있습니다. SK하이닉스와의 규격 표준화 주도를 통해 2027년 1분기 최초 출하를 목표로 속도를 내고 있습니다. 다만, 메모리를 초고속 인터포저 위에 얹어 고주파수 환경에서 신호를 정렬하는 후공정 경험은 부족하여 한국 기업들과의 협력이 절대적으로 필요합니다.
- 투자 매력도: 성장 기대주 (★★★★☆)
- 주요 리스크: 웨스턴디지털에서 분사한 지 얼마 안 된 신규 상장사로서 독립 기업으로서의 장기 트랙레코드(실적 신뢰성)가 짧음.
🇹🇼 TSMC: SRAM 초미세 공정의 절대 권력자
- 엔지니어적 시각: HBS가 상용화되면 수혜를 입을 수밖에 없는 파운드리 절대 강자입니다. 3나노 및 2나노 공정에서 고집적 SRAM 셀을 가장 안정적인 수율로 뽑아낼 수 있는 능력을 갖췄습니다. 자체 3D 패키징 플랫폼인 SoIC 기술을 고도화하여 엔비디아의 차세대 가속기 칩 바로 옆에 HBS를 다이렉트로 붙여주는 생태계를 주도할 가능성이 큽니다.
- 투자 매력도: 안정적 패권 유지 (★★★★☆)
🛠️ 후공정 장비 생태계의 영속적 승자: 한미반도체 & HPSP
메모리가 D램(HBM)이든, 낸드(HBF)든, SRAM(HBS)이든 관계없이 “위로 똑바로 정밀하게 쌓고, 결함을 치료해야 한다”는 후공정 대원칙은 변하지 않습니다. 적층 메모리의 종류가 3형제로 늘어난다는 것은 이들 장비 기업에 시장 규모가 복리로 커진다는 뜻입니다.
- 한미반도체 (042700): 칩과 칩을 초정밀로 정렬하고 순간적인 열과 압력으로 접합하는 듀얼 TC 본더(Dual TC Bonder) 기술력은 독보적입니다. HBF와 HBS 적층 라인이 증설될 때마다 수주 모멘텀이 배가됩니다.
- HPSP (403870): 초미세 공정으로 만든 SRAM(HBS) 및 D램 셀은 계면 결함으로 인한 전류 누설이 심합니다. 이를 고압 수소 가스를 통해 저온에서 치유해 주는 고압 수소 어닐링(Annealing) 장비는 초미세 적층 시대의 필수 독점재입니다.
💡 6. 투자 의견 및 핵심 요약 테이블
| 기업명 | 현재 시장 포지션 | 미래 기술 수혜도 (HBF/HBS) | 핵심 투자 매력 | 주요 리스크 요인 |
| SK하이닉스 | HBM 시장 현재 1위 | ★★★★★ (HBF 표준화 선도) | MR-MUF 기반 검증된 패키징 기술, 샌디스크 연합 | 단기 밸류에이션 부담, 메모리 사이클 리스크 |
| 삼성전자 | HBM 추격 및 낸드 1위 | ★★★★☆ (HBS 턴키 잠재력 최고) | 메모리+파운드리+AVP 완벽한 수직계열화 인프라 | 공정 수율 안정화 속도, 실행력 검증 필요 |
| 샌디스크 | 엔터프라이즈 eSSD 강자 | ★★★★☆ (HBF 핵심 파트너) | 낸드 원천 기술 및 고성능 컨트롤러 역량 | 짧은 독립 상용화 트랙레코드, 단독 패키징 불가 |
| TSMC | 글로벌 파운드리 1위 | ★★★★☆ (SRAM 공정 독점력) | 3나노/2나노 고집적 SRAM 제조의 독점적 수율 | 지오폴리틱스(지정학적) 리스크, 높은 주가 단가 |
| 한미반도체 | 후공정 장비 대장주 | ★★★★★ (모든 적층 메모리 수혜) | TC 본더의 압도적 시장 지배력 및 장비 확장성 | 글로벌 설비투자(CAPEX) 사이클 둔화 리스크 |
⚠️ 투자 유의사항: 반도체 섹터는 글로벌 매크로 경기 및 빅테크 기업들의 인프라 투자(CAPEX) 사이클에 매우 민감하게 반응합니다. 특히 HBF와 HBS는 현재 프로토타입 개발 및 개념 공개 단계이므로 상용화 양산까지는 타임라인의 변동성이 존재합니다. 본 포스팅은 기술적 분석과 정보 제공을 목적으로 하며, 특정 종목에 대한 매수/매도 추천이 아닙니다. 모든 투자의 책임은 본인에게 있습니다.
🔮 7. 결론: 패키징 전쟁의 서막, 매크로 투자자가 가야 할 길
무어의 법칙(Moore’s Law: 2년마다 반도체 집적도가 2배씩 증가한다는 법칙)이 물리적, 경제적 한계로 종말을 고하고 있는 2026년 현재, 반도체 산업의 핵심 승부처는 더 이상 “칩 내부를 얼마나 미세하게 깎느냐”가 아닙니다.
이제는 “따로 만든 서로 다른 기능의 칩들을 어떻게 3차원으로 연결하고(TSV), 어떻게 열을 방출하며(MR-MUF/어드밴스드 패키징), 어떻게 전기적 잡음을 제어하여(SI/PI) 하나의 거대한 칩처럼 돌릴 것인가”의 ‘패키징(Packaging) 전쟁’입니다.
김정호 교수가 제시한 HBS-HBM-HBF의 삼각편대 로드맵은 이러한 패러다임 변화를 완벽하게 관통하고 있습니다. 한국의 반도체 기업들이 HBM 시장에서 축적한 적층 기술과 노이즈 제어 인프라는 향후 개화할 HBF와 HBS 시장에서도 강력한 진입장벽이자 거대한 해자(Moat)로 작용할 것입니다.
단기적인 주가의 출렁임과 분기 실적에 연연하기보다는, 어떤 기업이 미래의 HBF 규격 표준을 선점하는지, 그리고 삼성전자의 파운드리-패키징 턴키 전략과 SK하이닉스의 이종 집적 동맹 중 어느 쪽이 빅테크 기업들의 선택을 먼저 받아 실물 프로토타입을 찍어내는지 그 궤적을 추적하는 것이 반도체 섹터 투자에서 승리하는 가장 확실한 나침반이 될 것입니다.
관련 기사: