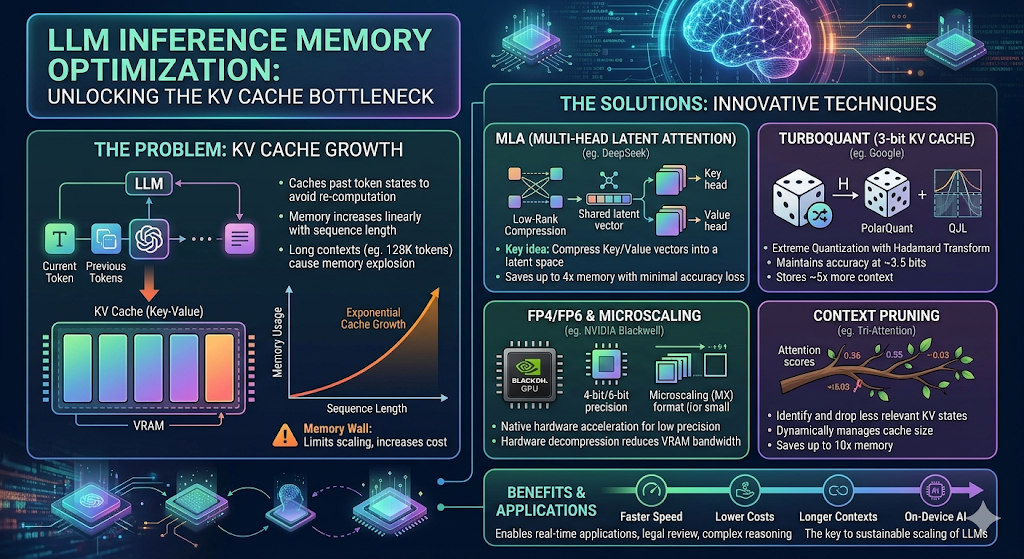
— DeepSeek MLA, Google TurboQuant, TriAttention, NVIDIA Blackwell까지 —
목차
- 서론: AI의 진짜 병목은 GPU가 아니라 ‘메모리’였다
- KV 캐시의 해부학: 왜 메모리를 잡아먹는가?
- 메모리 효율화의 4대 접근법 개요
- DeepSeek MLA: 잠재 공간 압축의 혁명
- Google TurboQuant: 3비트 양자화로 6배 압축
- MIT × NVIDIA TriAttention: 삼각함수로 메모리를 쳐내다
- NVIDIA Blackwell: 하드웨어 레벨의 메모리 혁신
- 구글 컨텍스트 캐싱: 클라우드 인프라로의 확장
- 기술들의 합산 효과와 상호작용
- 왜 지금 이 기술들이 동시에 등장하는가?
- 투자 관점: 승자와 패자의 지형 변화
- 주목해야 할 기업 및 뉴스 상세 분석
- 엔지니어를 위한 기술 스택 가이드
- 결론: 메모리 효율화는 AI 민주화의 진짜 열쇠
1. 서론: AI의 진짜 병목은 GPU가 아니라 ‘메모리’였다
AI 산업을 바라보는 대부분의 시선이 GPU의 성능, 특히 NVIDIA의 독점적 지위에 쏠려 있는 동안, AI 시스템을 실제로 운용해 본 엔지니어들은 전혀 다른 병목을 목도하고 있었다. 그것은 바로 메모리(Memory)다.
놀랍게도, 현대의 LLM(Large Language Model) 추론 시스템에서 실제 연산 속도를 제약하는 요소는 GPU의 부동소수점 연산 처리량(FLOPS)이 아니다. 대부분의 프로덕션 환경에서 LLM 추론은 메모리 대역폭(Memory Bandwidth)에 의해 병목이 결정된다. GPU가 계산을 더 빨리 하고 싶어도, 필요한 데이터를 메모리에서 꺼내오는 속도가 이를 따라가지 못하는 것이다.
이 현상을 가리켜 업계에서는 ‘메모리 월(Memory Wall)’이라고 부른다. AI 컴퓨팅의 발전에서 연산 처리량(Compute)의 성장 속도가 메모리 대역폭의 성장 속도를 훨씬 앞지르면서 생겨난 간극이다. 그리고 이 간극은 모델이 커질수록, 처리해야 할 텍스트 문맥(Context)이 길어질수록 더욱 치명적으로 작용한다.
구체적인 수치를 들어보자. Llama-2 65B 모델을 bfloat16 정밀도로 구동할 경우, 128K 토큰의 문맥을 처리하기 위한 KV 캐시만으로도 335GB의 GPU 메모리가 필요하다. H100 GPU 한 장의 HBM(고대역폭 메모리) 용량이 80GB임을 감안하면, 이는 최소 5장의 H100을 오직 KV 캐시를 위해 소모해야 한다는 의미다. 여기에 모델 가중치 저장용 메모리까지 더하면 비용은 천문학적으로 치솟는다.
바로 이 지점에서 2025년 하반기부터 2026년에 걸쳐 AI 연구의 핵심 전선이 바뀌었다. DeepSeek, Google, MIT와 NVIDIA의 공동 연구팀은 각자의 방식으로 이 메모리 문제를 정면 돌파하기 시작했다. 이 글은 그 기술들의 작동 원리를 해부하고, 이 변화가 투자 지형에 어떤 파급 효과를 만들고 있는지를 함께 살펴보는 종합 분석 리포트다.
2. KV 캐시의 해부학: 왜 메모리를 잡아먹는가?
메모리 효율화 기술들을 이해하기 위해서는 먼저 KV 캐시(Key-Value Cache)가 무엇이며, 왜 이것이 메모리를 폭발적으로 소비하는지를 이해해야 한다.
트랜스포머(Transformer) 아키텍처의 핵심은 어텐션 메커니즘(Attention Mechanism)이다. LLM이 다음 토큰을 예측할 때, 모델은 이전에 입력된 모든 토큰과의 관계를 계산해야 한다. 이 과정에서 각 토큰에 대해 Key(K)와 Value(V) 벡터가 생성된다.
만약 KV 캐시 없이 매번 처음부터 계산한다면, 토큰 하나를 생성할 때마다 그 앞에 있는 모든 토큰의 K, V 값을 재계산해야 한다. 이는 문맥이 길어질수록 계산량이 기하급수적으로 늘어나는 것을 의미한다. KV 캐시는 이 문제를 해결하기 위해 이미 계산된 K, V 값을 메모리에 저장해두고 재사용하는 방식이다.
문제는 이 캐시의 크기다. KV 캐시의 메모리 사용량은 다음 공식을 따른다:
KV 캐시 크기 = 2 × 레이어 수(L) × 헤드 수(H) × 시퀀스 길이(T) × 헤드 차원(D) × 데이터 정밀도
70B 파라미터 모델에서 128K 토큰의 문맥을 FP16(16비트)으로 처리한다면, KV 캐시 하나만으로 약 40GB의 VRAM이 사라진다. 여기서 ‘VRAM의 절반을 모델 가중치가 차지하고 있다’는 사실을 더하면, H100 두 장이 KV 캐시에 잠식당하는 상황이 현실이 된다.
더욱 심각한 것은 긴 추론(Long Reasoning) 모델의 등장이다. OpenAI의 o1, DeepSeek-R1 같은 chain-of-thought 추론 모델들은 하나의 쿼리에 대해 수만 토큰의 중간 사고 과정을 생성한다. 이 경우 KV 캐시 문제는 추론의 길이에 정비례하여 폭발적으로 증가한다.
이것이 바로 전 세계 최고의 AI 연구기관들이 일제히 KV 캐시를 압축하는 방법에 집중하게 된 이유다.
3. 메모리 효율화의 4대 접근법 개요
현재 연구와 산업계에서 시도되는 LLM 메모리 효율화 전략은 크게 네 가지 범주로 분류할 수 있다.
① 아키텍처 수준 재설계 (Architecture-Level Redesign) 모델을 처음부터 메모리 효율을 염두에 두고 설계하는 방식이다. DeepSeek의 MLA(Multi-Head Latent Attention)가 대표적이다. KV를 저장하는 구조 자체를 바꿔 근본적으로 캐시 크기를 줄인다.
② 양자화 기반 압축 (Quantization-Based Compression) 저장되는 데이터의 비트 수(정밀도)를 줄이는 방식이다. Google의 TurboQuant가 이 범주에 속하며, KV 캐시를 16비트에서 3비트로 압축한다. NVIDIA의 FP4 지원도 같은 맥락이다.
③ 토큰 프루닝 (Token Pruning) 중요하지 않은 토큰에 대한 KV 값을 아예 캐시에서 제거하는 방식이다. MIT·NVIDIA의 TriAttention이 이 방법의 최신 사례다. 중요하지 않은 토큰을 판별하는 정밀도가 이 기술의 핵심이다.
④ 시스템 레벨 최적화 (System-Level Optimization) GPU 메모리 관리 방식을 개선하거나, 클라우드 서버의 캐싱 인프라를 활용하는 방식이다. Google의 컨텍스트 캐싱(Context Caching)과 NVIDIA의 PagedAttention이 이에 해당한다.
이 네 가지 접근법은 상호 배타적이지 않으며, 실제로는 여러 기법을 조합함으로써 훨씬 큰 압축 효과를 달성할 수 있다. 예를 들어 TriAttention과 TurboQuant를 동시에 적용할 경우, AMD GPU에서 약 6.8배의 KV 캐시 감소 효과가 보고되고 있다.
4. DeepSeek MLA: 잠재 공간 압축의 혁명
4-1. MHA의 한계와 MLA의 탄생
기존의 MHA(Multi-Head Attention) 방식은 각 어텐션 헤드마다 독립적인 Key와 Value를 전체 차원으로 저장한다. 이는 표현력은 강하지만 메모리 사용량이 헤드 수에 정비례하여 늘어나는 구조적 한계를 지닌다.
이 문제를 개선하기 위한 이전의 시도들, 즉 GQA(Grouped Query Attention)와 MQA(Multi-Query Attention)**는 여러 쿼리 헤드가 동일한 K, V를 공유하도록 하여 메모리를 줄였다. 그러나 이 방식은 성능 저하라는 대가를 치러야 했다. 공유함으로써 각 헤드가 갖던 독립적인 표현 능력이 약화되기 때문이다.
DeepSeek은 이 딜레마를 정면으로 돌파하는 완전히 다른 아이디어를 제시했다. 그것이 바로 MLA(Multi-Head Latent Attention)다. 이 기술은 DeepSeek-V2 논문에서 최초로 제안되었고, DeepSeek-V3와 R1에 이르러 그 효과가 증명되어 업계 표준으로 자리잡기 시작했다.
4-2. MLA의 핵심 원리: 저랭크 압축과 잠재 공간
MLA의 핵심 아이디어는 저랭크(Low-Rank) 분해다. 전체 차원의 K, V 텐서를 그대로 저장하는 대신, 훨씬 작은 잠재 표현(Latent Representation)으로 압축하여 저장하고, 계산이 필요할 때 이를 복원하는 방식이다.
구체적인 작동 과정을 단계별로 살펴보자:
Step 1 — Key-Value 압축 (Compression) 입력 토큰의 K, V 텐서를 저차원 잠재 벡터 c_KV로 사영(projection)한다.
c_KV = W_DKV × h_t
여기서 W_DKV는 다운-프로젝션 행렬이며, h_t는 원래의 히든 스테이트 벡터다. 잠재 벡터의 차원은 원래 K, V의 차원보다 훨씬 작기 때문에, 이 단계에서 메모리 사용량이 극적으로 줄어든다. KV 캐시에는 이 압축된 잠재 벡터만 저장된다.
Step 2 — Key-Value 복원 (Decompression) 어텐션 계산이 실제로 필요한 시점에, 저장된 잠재 벡터로부터 K, V를 복원(decompression)한다.
K = W_UK × c_KV
V = W_UV × c_KV
W_UK와 W_UV는 업-프로젝션 행렬로, 잠재 벡터를 원래의 K, V 차원으로 되돌린다. 이 과정은 저랭크 근사(Low-Rank Approximation)이므로 완전히 동일한 결과를 내지는 않지만, 실험 결과에 따르면 표현력의 손실이 GQA보다 훨씬 작다.
Step 3 — RoPE와의 통합 (Position Encoding 처리) MLA에서 까다로운 부분은 **RoPE(Rotary Position Embedding)**의 처리다. RoPE는 위치 정보를 K 벡터에 직접 인코딩하는 방식인데, 이는 잠재 공간에서의 저장과 충돌한다. DeepSeek은 K 벡터를 콘텐츠 성분(content component)과 위치 성분(positional component)으로 분리하여 이 문제를 우아하게 해결했다:
K = [K_content, K_rope]
K_content = W_UK × c_KV (잠재 벡터에서 복원)
K_rope = RoPE(W_KR × h_t) (별도 위치 인코딩 처리)
4-3. MLA의 성능: 수치로 보는 효과
MLA가 달성하는 메모리 효율화 수준은 놀랍다. DeepSeek-V2 기준, MLA는 표준 MHA 대비 KV 캐시를 약 4H/9 수준으로 압축한다(H는 헤드 수). 이는 동일한 성능을 유지하면서 메모리를 수십 퍼센트 줄인다는 의미가 아니라, 구조적으로 전혀 다른 방식으로 캐시 자체를 재설계한 것이다.
더 중요한 것은 성능 저하 없이 이 효율을 달성한다는 점이다. KU Leuven의 하드웨어 중심 분석 논문(2026)에 따르면, MLA는 디코딩 단계에서 메모리 대역폭 요구량을 대폭 낮추는 동시에, 표현력은 MHA 수준을 유지하거나 일부 태스크에서 그 이상을 보인다.
GQA/MQA가 ‘성능 저하를 감수한 메모리 절충’이었다면, MLA는 ‘성능을 유지하면서 메모리를 줄이는 진보’에 가깝다. 이것이 MLA가 현재 LLM 아키텍처의 패러다임 전환으로 평가받는 이유다.
4-4. MLA의 확산: TransMLA와 MHA2MLA
MLA의 파급력은 DeepSeek 자체 모델에서 그치지 않는다. TransMLA 논문은 기존에 MHA로 훈련된 모델을 추론 시에 MLA로 전환하는 방법론을 제시했다. MHA2MLA 연구는 GPT, LLaMA 계열 등 기존 모델들도 MLA의 혜택을 받을 수 있도록 하는 전환 기법을 제안한다.
이는 MLA가 단순히 DeepSeek의 경쟁 우위 요소를 넘어, 업계 전체의 어텐션 메커니즘 설계 표준으로 자리잡아가고 있음을 의미한다. 비전-언어 모델(VLM)에 MLA를 적용한 MHA2MLA-VLM 연구도 등장하며, 멀티모달 AI에도 이 기술이 빠르게 침투하고 있다.
5. Google TurboQuant: 3비트 양자화로 6배 압축
5-1. TurboQuant의 등장과 시장 충격
2026년 3월 24일, Google Research는 TurboQuant를 공개했다. 이 알고리즘의 주장은 단순하면서도 충격적이었다: KV 캐시를 3비트로 압축하면서 정확도 손실 없이 메모리를 6배, 연산 속도를 최대 8배 향상시킨다.
이 발표는 즉각적으로 시장에 파장을 일으켰다. 발표 다음 날인 3월 25일 하룻만에 SK 하이닉스 주가가 약 6.2%, 삼성전자가 약 4.7%, Micron이 약 3.4% 하락했다. ICLR 2026 학술대회에서 발표될 예정인 이 논문은 단순한 연구 결과를 넘어 AI 메모리 산업의 투자 논리 전체를 흔들었다.
Cloudflare의 CEO 매튜 프린스는 이를 “구글의 DeepSeek 모먼트”라고 불렀다. DeepSeek이 중국 AI가 서방의 GPU 독점을 소프트웨어 혁신으로 우회한 것처럼, TurboQuant는 AI 메모리 수요 증가라는 ‘상식’을 소프트웨어로 깨트릴 수 있음을 시사했기 때문이다.
5-2. TurboQuant의 작동 원리: 두 단계의 수학적 정교함
TurboQuant는 두 가지 기존 기법을 결합한 통합 프레임워크다. 그 알고리즘의 핵심을 이해하려면 ‘왜 KV 캐시의 단순한 양자화가 어려운가’를 먼저 알아야 한다.
문제: KV 캐시의 극단적 이상치(Outlier)
LLaMA-2-7B를 예로 들면, KV 캐시 값의 상위 1%는 나머지 값들보다 크기가 10~100배 이상 크다. 이러한 극단적 분포 편향(skew) 때문에 단순한 선형 4비트 양자화는 실패한다. 이상치를 수용하도록 양자화 격자를 넓히면, 정상 값들이 몰려있는 범위의 해상도가 극도로 낮아지기 때문이다.
1단계: PolarQuant — 랜덤 직교 회전
TurboQuant의 첫 단계는 PolarQuant 기법을 적용하는 것이다. 각 KV 벡터에 랜덤 직교 변환(Random Orthogonal Rotation)을 적용한다. 이 회전 후에는 각 좌표값이 알려진 통계적 분포(가우시안 분포에 수렴)를 따르게 된다.
이 성질을 이용하면, 이상치의 영향을 분산시키고 전체 분포를 양자화하기 좋은 형태로 평탄화할 수 있다. 사전에 계산된 하나의 코드북(codebook)을 적용할 수 있게 되어, 블록별 정규화 상수를 저장해야 하는 기존 방식의 비트 낭비를 제거한다.
2단계: QJL — 1비트 오류 보정
PolarQuant 적용 후에도 양자화 과정에서 미세한 편향(systematic bias)이 남는다. TurboQuant의 두 번째 단계는 QJL(Quantized Johnson-Lindenstrauss) 기법으로 이를 제거한다. QJL은 Johnson-Lindenstrauss 투영을 이용한 1비트 오류 보정 레이어로, 1단계의 잔류 오류를 수정하여 전체 시스템의 정확도를 근사적 최적(provably near-optimal) 수준으로 끌어올린다.
이 두 단계의 결합 결과, TurboQuant는 좌표당 약 3.5비트를 달성하며, 이는 정보 이론적 왜곡률의 이론적 하한에 2.7배 이내로 근접하는 성능이다.
5-3. TurboQuant의 벤치마크 결과
TurboQuant의 성능은 다음과 같이 검증되었다:
- Needle-in-a-Haystack 테스트: KV 메모리를 6배 이상 압축하면서 완벽한 정확도 달성
- LongBench 스위트: 질의응답, 코드 생성, 요약 등 전 태스크에서 KIVI 베이스라인 동등 또는 초과
- NVIDIA H100 GPU: 4비트 TurboQuant로 어텐션 로짓 계산 속도 최대 8배 향상
- 훈련 불필요: 기존 모델에 추가적인 파인튜닝 없이 추론 시점에 바로 적용 가능
특히 ‘훈련 불필요(Training-Free)’라는 특성은 실무적으로 매우 중요하다. 기존의 GPTQ, AWQ 같은 양자화 기법은 캘리브레이션 데이터셋과 별도의 훈련 과정이 필요했지만, TurboQuant는 배포 시점에 플러그인 방식으로 즉시 적용할 수 있다.
비용 절감 효과는 클라우드 인프라 관점에서도 극명하다. H100 SXM5 2장(시간당 $5.80)으로 70B 모델을 32K 컨텍스트로 서빙하는 경우: TurboQuant 적용 전에는 월 2명의 사용자($2,088/인/월), 적용 후에는 11명의 사용자($380/인/월)를 동일 비용으로 서비스할 수 있다.
6. MIT × NVIDIA TriAttention: 삼각함수로 메모리를 쳐내다
6-1. TriAttention의 문제 의식
TurboQuant가 KV 캐시의 정밀도를 줄이는 양자화 접근이라면, TriAttention은 근본적으로 다른 방향을 택한다. 중요하지 않은 토큰의 KV 쌍을 아예 물리적으로 제거(Pruning)하는 것이다.
이 아이디어 자체는 새롭지 않다. 기존의 토큰 프루닝 방식들은 최근 쿼리의 어텐션 점수를 기반으로 중요도를 추정하고 덜 중요한 토큰을 제거해왔다. 그러나 이 접근에는 근본적인 약점이 있다: RoPE(Rotary Position Embedding) 때문에 쿼리 벡터가 위치에 따라 회전하므로, 오직 가장 최근의 소수 쿼리만이 신뢰할 수 있는 중요도 추정에 사용 가능하다. 관측 창이 너무 좁아 불안정한 프루닝이 일어난다.
6-2. 삼각함수 시리즈의 발견
MIT, NVIDIA, 절강대학교 공동 연구팀이 TriAttention에서 발견한 핵심 통찰은 다음과 같다: RoPE를 적용하기 전의(Pre-RoPE) 쿼리·키 벡터들이 특정 집약(concentration) 성질을 가진다.
연구팀은 MRL(Mean Resultant Length, 평균 결과 길이)이라는 지표로 이 현상을 정량화했다. Qwen3-8B 모델에서 약 90%의 어텐션 헤드가 MRL > 0.95를 보였다. 이는 pre-RoPE 벡터들이 입력에 무관하게 특정 방향으로 강하게 집약되어 있음을 의미한다.
이 발견의 함의는 심오하다. Pre-RoPE 벡터가 집약되어 있다면, RoPE 적용 후의 어텐션 로짓은 위치 거리의 삼각 함수 시리즈(Trigonometric Series)로 모델링될 수 있다. 수식으로 표현하면:
Attention(q_t, k_i) ≈ Σ_r [a_r × cos(r × (t - i)θ) + b_r × sin(r × (t - i)θ)]
이 표현의 핵심적 장점은, 특정 토큰과의 어텐션 점수를 실제로 계산하지 않고도, 그 토큰의 중요도를 위치 정보만으로 오프라인에서 사전 계산할 수 있다는 것이다. 즉, 어떤 토큰이 중요한지를 입력 데이터를 보지 않고도 판별할 수 있다.
6-3. TriAttention의 벤치마크 성과
이 수학적 통찰을 구현한 TriAttention의 결과는 인상적이다:
- AIME25 벤치마크: 정확도(40.8%)를 완전히 유지하면서 KV 메모리를 10.7배 감소
- 처리량: 풀 어텐션(Full Attention) 대비 2.5배 높은 처리량 달성
- R-KV 베이스라인: 동일 정확도에서 성능이 2배 향상
- 모델 범용성: Qwen3-8B, GLM-4.7-Flash 등 GQA와 MLA 아키텍처 모두에서 작동
가장 주목할 만한 실제 응용은 OpenClaw다. TriAttention을 적용한 OpenClaw를 이용하면, 기존에는 메모리 부족으로 실행 불가능했던 32B 파라미터 추론 모델을 단일 RTX 4090(24GB) GPU에서 구동할 수 있다. 이는 온디바이스 AI와 소비자용 GPU의 잠재력을 극적으로 확장시키는 의미를 지닌다.
TriAttention은 또한 AMD GPU의 llama.cpp 포트, Apple Silicon M-시리즈 지원, SGLang 백엔드 통합이 빠르게 이루어지며 오픈소스 생태계 전반으로 확산 중이다.
7. NVIDIA Blackwell: 하드웨어 레벨의 메모리 혁신
7-1. FP4/FP6 지원: 비트를 줄여 데이터를 늘린다
NVIDIA의 접근은 소프트웨어가 아닌 실리콘 레벨에서 메모리 효율화를 해결하는 전략이다. Blackwell 아키텍처(B200)의 핵심 차별화 요소 중 하나는 FP4(4비트 부동소수점) 연산의 하드웨어 지원이다.
기존 GPU들이 기본적으로 FP16(16비트)이나 BF16으로 연산하는 데 반해, Blackwell은 FP4와 FP6 연산을 네이티브로 지원한다. 이 차이는 단순한 숫자 이상의 의미를 지닌다:
- FP4: FP16 대비 4배 더 많은 가중치를 같은 메모리에 저장
- FP6: FP16 대비 약 2.7배 향상된 메모리 밀도
- 연산 처리량: FP4 사용 시 FP16 대비 최대 2배의 FLOPS 달성
실질적인 영향은 모델 서빙 규모에서 나타난다. FP16으로 H100 8장이 필요하던 작업을 B200 2장의 FP4 모드로 처리할 수 있다면, 인프라 비용과 전력 소비가 동시에 절감된다.
7-2. 하드웨어 압축 엔진 (Hardware Decompression Engine)
Blackwell에서 또 다른 주목할 혁신은 전용 디컴프레션 엔진(Decompression Engine)의 탑재다. GPU 내부에 하드웨어로 구현된 이 엔진은 압축된 모델 가중치를 실시간으로 압축 해제하여 계산에 공급하는 역할을 한다.
이 엔진의 의미는 다음과 같다: 모델 가중치를 압축 형태로 HBM에 저장하면 더 많은 데이터를 같은 메모리에 담을 수 있고, 디컴프레션 엔진이 계산 중에 실시간으로 이를 풀어주므로 소프트웨어 단의 압축 해제 오버헤드가 없다. 메모리 용량과 대역폭 모두를 동시에 개선하는 효과다.
7-3. TurboQuant와의 시너지
중요한 점은 NVIDIA Blackwell이 TurboQuant 같은 소프트웨어 양자화 기법의 혜택을 증폭시킨다는 것이다. TurboQuant가 KV 캐시를 3~4비트로 압축하면, Blackwell의 FP4 연산 유닛이 이를 추가 변환 없이 직접 처리할 수 있다. 소프트웨어와 하드웨어 최적화가 맞물리는 구조다.
일부 분석가들이 “TurboQuant는 NVIDIA를 해치지 않는다”고 주장하는 것도 이 때문이다. 오히려 Blackwell은 저정밀도 연산에 최적화된 설계이므로, TurboQuant의 확산은 Blackwell 세대 GPU의 수요를 뒷받침하는 논거가 된다.
8. 구글 컨텍스트 캐싱: 클라우드 인프라로의 확장
8-1. 컨텍스트 캐싱의 작동 방식
TurboQuant가 KV 캐시의 정밀도를 줄이는 알고리즘적 접근이라면, Google의 컨텍스트 캐싱(Context Caching)은 KV 캐시를 서버 인프라 수준에서 재사용하는 시스템적 접근이다.
법률 문서, 기업 매뉴얼, 대형 코드베이스처럼 반복적으로 참조되는 수만 토큰의 문서를 생각해보자. 매 쿼리마다 이 문서 전체를 다시 처리해 KV 캐시를 생성하는 것은 엄청난 낭비다. 컨텍스트 캐싱은 이 불변 컨텍스트의 KV 캐시를 서버 측에 미리 계산하여 저장해 두고, 이후 동일 컨텍스트를 참조하는 쿼리들이 이 캐시를 공유하도록 한다.
Gemini API에서 지원하는 컨텍스트 캐싱은 수백만 토큰 규모의 컨텍스트에도 적용 가능하며, 이를 통해 기업 사용자들은 동일한 대용량 문서 기반으로 반복 쿼리를 처리할 때 비용을 대폭 줄일 수 있다.
8-2. 알고리즘적 압축과 시스템적 캐싱의 조합
TurboQuant와 컨텍스트 캐싱은 상호 보완적으로 작동할 수 있다. TurboQuant로 KV 캐시 자체의 크기를 줄이고, 컨텍스트 캐싱으로 그 압축된 KV 캐시를 여러 세션에 걸쳐 재사용한다면, 메모리 절감 효과는 곱셈 관계로 증폭된다. Google이 Gemini 모델 서비스에서 이 두 기술을 결합하여 적용한다면, 클라우드 AI 서비스의 경제성은 현재와 비교할 수 없을 만큼 개선될 것이다.
9. 기술들의 합산 효과와 상호작용
여기서 핵심적인 질문이 등장한다: 이 기술들을 모두 동시에 적용하면 어떻게 될까?
실험 데이터는 이미 나오기 시작했다:
| 기술 조합 | 적용 하드웨어 | KV 캐시 압축 효과 |
|---|---|---|
| TriAttention 단독 | NVIDIA GPU | ~10.7x |
| TurboQuant 단독 | NVIDIA H100 | ~6x |
| TriAttention + TurboQuant | AMD GPU (ROCm) | ~6.8x (결합) |
| MLA + FP8 양자화 | NVIDIA GPU | ~8x 이상 추정 |
| MLA + TurboQuant + TriAttention | 이론치 | 수십 x 가능성 |
TriAttention의 GitHub 리포지토리에 따르면, TriAttention과 TurboQuant를 함께 적용하는 통합 구현이 이미 커뮤니티에서 진행 중이다. Apple Silicon M-시리즈 지원도 등장하여, 스마트폰과 노트북에서 대형 모델을 구동하는 시나리오가 현실로 다가오고 있다.
기술의 수렴(Convergence) 방향은 분명하다: 아키텍처 수준의 압축(MLA) + 양자화(TurboQuant) + 토큰 프루닝(TriAttention) + 하드웨어 최적화(Blackwell FP4)의 결합이 LLM 추론의 표준 스택이 될 것이다.
10. 왜 지금 이 기술들이 동시에 등장하는가?
이 기술들이 2025~2026년에 집중적으로 쏟아지는 것은 우연이 아니다. 세 가지 구조적 압력이 동시에 작용하고 있다.
① 긴 추론(Long Reasoning) 모델의 주류화
OpenAI o1, DeepSeek-R1, Gemini 2.0 Flash Thinking 등 chain-of-thought 추론 모델들이 경쟁의 전면에 등장했다. 이 모델들은 하나의 쿼리에 수만 토큰의 중간 사고 과정을 생성한다. 문맥 길이가 선형이 아닌 기하급수적으로 늘어나는 추론 패러다임은 기존의 KV 캐시 설계를 완전히 붕괴시킨다.
② 온디바이스 AI의 상용화 요구
Apple, Qualcomm, MediaTek이 온디바이스 AI를 스마트폰에 탑재하는 경쟁이 본격화되고 있다. 스마트폰의 LPDDR5X 메모리는 최대 64GB 수준이며, 여기서 대형 언어 모델을 구동하려면 메모리 효율화는 생존 조건이다. 클라우드 서버에서야 메모리 부족을 GPU를 추가하는 것으로 해결할 수 있지만, 스마트폰에서는 그럴 수 없다.
③ AI 서비스 비용 구조의 재편 압력
GPT-4 수준의 모델을 100만 토큰 컨텍스트로 서비스하는 비용은 아직도 상당하다. 기업 고객들이 AI를 핵심 업무 흐름에 통합하려면 비용이 기존 소프트웨어 솔루션과 경쟁 가능한 수준으로 내려와야 한다. 메모리 효율화는 이 비용 곡선을 끌어내리는 가장 직접적인 방법이다.
이 세 가지 압력이 동시에 연구자들을 같은 방향으로 몰아붙인 결과가, 우리가 지금 목격하고 있는 기술의 동시 다발적 폭발이다.
11. 투자 관점: 승자와 패자의 지형 변화
11-1. TurboQuant 충격과 메모리 반도체 섹터
2026년 3월 25일 TurboQuant 발표 이후 시장의 반응은 즉각적이었다. SK 하이닉스 -6.2%, 삼성전자 -4.7%, Micron -7%, Kioxia -6%의 하락이 하루 만에 발생했다. 이는 “AI는 더 많은 메모리를 요구한다”는 메모리 반도체 섹터의 핵심 투자 테제에 정면으로 도전하는 사건으로 읽혔다.
그러나 시장의 공황 반응이 과도했는가를 냉정하게 판단해야 한다. 애널리스트들의 분석을 종합하면 다음과 같은 반론이 제기된다:
단기 과잉 반응 근거:
- TurboQuant는 KV 캐시 압축만을 다루며, 모델 가중치 저장에는 전혀 영향이 없다 (70B 모델의 가중치는 FP16 기준 140GB로 변화 없음)
- 훈련용 메모리 수요(그라디언트, 최적화 상태, 활성화 값)는 추론용 KV 캐시보다 훨씬 크며, TurboQuant와 무관하다
- KV 캐시 압축이 가능해지면 모델 사업자들은 같은 하드웨어로 더 긴 컨텍스트를 제공하게 되어, 절약된 메모리가 더 큰 서비스로 흡수될 수 있다
- Goldman Sachs는 2026년 DRAM 공급 4.9% 부족을 전망하며, 구조적 수요 우위는 변하지 않았다
- Quilter Cheviot의 기술 연구 책임자 벤 배링거는 “TurboQuant 혁신이 압박을 가하고 있으나, 이는 진화적이지 혁명적이지 않다. 업계의 장기 수요 그림을 바꾸지는 않는다”고 평가했다
장기 구조 변화 근거:
- 효율화 기술이 메모리 하드웨어를 대체하는 역사적 전례가 없다 (SSD가 HDD를 대체했지만, 스토리지 수요는 오히려 증가)
- ‘Jevons Paradox’: 효율화는 비용을 낮추어 사용을 더욱 촉진한다. AI 비용이 내려가면 더 많은 기업과 개인이 AI를 사용하고, 총 메모리 수요는 오히려 증가할 수 있다
- 메모리 공급 증설에는 수년이 걸리며, 현재도 HBM 공급은 수요를 따라가지 못하고 있다
11-2. 투자 관점에서 주목해야 할 기업들
① NVIDIA (NVDA) — 핵심 수혜자
메모리 효율화의 역설은, NVIDIA에게 이것이 실질적으로 이득이라는 점이다. 첫째, Blackwell 아키텍처는 FP4를 중심으로 설계되어 있어 TurboQuant, TriAttention과 같은 저정밀도 기법의 하드웨어 파트너다. 둘째, NVIDIA는 TensorRT-LLM, vLLM, KVPress 등 메모리 효율화 소프트웨어 스택의 핵심 기여자다. 셋째, TriAttention 논문의 공동 저자 중 NVIDIA 연구진이 포함되어 있다. 메모리 효율화 연구를 직접 주도하는 위치에 있다.
투자 관점: 단기 조정 시 매수 기회. Blackwell 세대 수요와 AI 추론 시장 성장이 핵심 모멘텀.
② SK 하이닉스 (000660.KS) — 단기 충격, 장기 기회
SK 하이닉스는 TurboQuant 충격으로 가장 큰 하락을 보였지만, 한국 시장의 HBM 독점적 지위는 훼손되지 않았다. HBM4 로드맵과 NVIDIA와의 독점적 공급 관계가 유지되는 한, 알고리즘 효율화가 즉각적인 수요 타격으로 이어지기 어렵다.
더 중요한 것은, AI가 더 효율적이 될수록 더 많은 기업이 AI를 채택하고, 데이터센터 투자는 오히려 증가하는 ‘Jevons Paradox’가 작동할 가능성이 높다. Micron의 CEO도 인정했듯 메모리는 AI 시대의 ‘전략적 자산’이다.
투자 관점: TurboQuant 충격에 따른 -6% 조정은 중장기 관점에서 매수 기회 가능성. HBM 수급 상황을 지속 모니터링.
③ Micron (MU) — 리스크와 기회의 공존
Micron은 SK 하이닉스, 삼성과 달리 HBM 시장에서의 입지가 상대적으로 약하고, TurboQuant 발표 이후 -7%에서 한 달간 -17% 수준의 가장 큰 낙폭을 기록했다. 2026 회계연도 설비투자 $250억 이상의 공격적 계획이 수요 전망 변화 시 재무적 압박으로 작용할 수 있다.
반면, Micron이 HBM3E를 NVIDIA Blackwell에 공급하는 데 성공했고, 분기 매출 $335억 돌파 등 실적은 여전히 강하다. 주가 조정이 과도하다는 분석도 많다.
투자 관점: 고위험·고보상 포지션. HBM 공급 다변화 시나리오에서 수혜 가능. 설비투자 계획 대비 수요 확인 필요.
④ Alphabet (GOOGL) — 소프트웨어 효율화의 최대 수혜자
TurboQuant는 Google의 직접적인 경쟁 우위를 강화한다. 기술을 발표한 당일 주가가 상승한 것이 이를 반영한다. Google은 Gemini 모델에 컨텍스트 캐싱과 TurboQuant를 통합함으로써, 동일한 인프라로 더 많은 서비스를 제공하거나 클라우드 AI 서비스 마진을 크게 개선할 수 있다.
또한 TurboQuant의 공개 발표는 Google Cloud의 AI 인프라 경쟁력을 마케팅하는 효과도 있다. Azure, AWS 대비 차별화 포인트로 활용될 수 있다.
투자 관점: 메모리 효율화 소프트웨어 혁신의 직접 수혜. 클라우드 AI 서비스 마진 개선 기대. 중장기 긍정 전망.
⑤ Apple (AAPL) — 온디바이스 AI의 최대 수혜자
TurboQuant, TriAttention 같은 기술이 온디바이스 AI를 현실화한다면, 가장 큰 수혜자는 다름 아닌 Apple이다. iPhone, MacBook의 제한된 메모리에서 더 강력한 AI를 구동할 수 있게 되면, AI 기능이 기기 교체의 핵심 동기가 된다. TriAttention의 Apple Silicon M-시리즈 지원이 이미 커뮤니티 수준에서 구현된 것은 이 방향의 신호다.
투자 관점: 온디바이스 AI 사이클의 트리거가 되는 메모리 효율화 기술 진전에 가장 간접적이지만 크게 수혜. 차기 iPhone 사이클 점검 시 AI 기능 강화 여부 주목.
⑥ DeepSeek (비상장) 관련 — 간접 투자 주목 기업들
DeepSeek 자체는 현재 비상장이나, MLA 기술의 확산이 만들어내는 수혜를 볼 수 있는 상장 기업들이 있다. MLA를 자사 모델에 채택하거나 MLA 기반 인프라를 제공하는 클라우드·AI 기업들이 대상이다. 중국 AI 에코시스템의 확장을 우회적으로 포착하는 전략으로서, 관련 ETF(예: KWEB, CQQQ)도 대안이 될 수 있다.
12-1. 투자 관점 핵심 뉴스 타임라인
2026년 3월 24일 — Google TurboQuant 논문 arXiv 공개. ICLR 2026 채택 발표.
2026년 3월 25~26일 — 메모리 반도체 주 급락. SK 하이닉스 -6.2%, 삼성 -4.7%, Micron -7%.
2026년 4월 초 — TurboQuant 충격 ‘과도 반응’ 분석 잇따라 등장. NVIDIA가 수혜라는 반론 부상.
2026년 4월 11일 — TriAttention 논문(MIT·NVIDIA·절강대) 공개. 10.7배 KV 감소, RTX 4090에서 32B 모델 구동.
2026년 4월 이후 — TurboQuant + TriAttention 커뮤니티 구현 통합. AMD ROCm, Apple Silicon 포팅 완료.
지속 주목 포인트:
- NVIDIA Blackwell B200 양산 및 FP4 소프트웨어 스택 완성도
- Google Gemini API의 TurboQuant 공식 통합 여부
- Micron·SK 하이닉스 2026 하반기 주문 동향 (알고리즘 효율화의 실제 수요 영향 확인)
- 온디바이스 AI를 위한 모바일 AP(Qualcomm Snapdragon, Apple M-시리즈)의 메모리 효율화 기술 채택 가속도
13. 엔지니어를 위한 기술 스택 가이드
현재 LLM 메모리 효율화를 실제로 적용하려는 엔지니어라면 다음 기술 스택을 참고하길 권장한다.
추론 프레임워크
- vLLM: PagedAttention과 각종 KV 압축 기법의 통합이 가장 빠르게 이루어지는 오픈소스 프레임워크. TurboQuant, TriAttention 지원이 진행 중.
- SGLang: TriAttention 백엔드를 지원하며, 구조화된 LLM 출력과 복잡한 추론 파이프라인에 적합.
- llama.cpp: 저사양 하드웨어 중심. AMD ROCm용 TriAttention 포트가 커뮤니티에서 완성됨.
핵심 논문 읽기 순서
- DeepSeek-V2 논문 (MLA 원본) — KV 압축의 아키텍처 접근
- TurboQuant 논문 (arXiv 2504.19874, ICLR 2026) — 양자화 압축의 최신
- TriAttention 논문 (arXiv 2604.04921) — 토큰 프루닝의 최신
- MHA2MLA 논문 (arXiv 2502.14837) — 기존 모델에 MLA 적용
개발 시 주의사항
- TurboQuant는
head_dim=64모델에서 WHT 수렴 이슈가 있어, 해당 경우 K 캐시에 자동으로q8_0폴백이 필요함 - TriAttention은 pre-RoPE 벡터 집약도가 낮은 헤드(<0.95 MRL)에서는 정확도 저하 위험이 있으므로 헤드별 선택적 적용 필요
- MLA와 TurboQuant를 결합할 때 압축 후 잠재 벡터의 복원 단계에서 양자화 오차가 누적될 수 있어 품질 평가 필수
14. 결론: 메모리 효율화는 AI 민주화의 진짜 열쇠
우리는 지금 AI 인프라 역사에서 중요한 변곡점을 지나고 있다.
GPU 연산 능력의 발전이 AI의 ‘지능 한계’를 밀어붙였다면, 메모리 효율화 기술의 혁신은 AI의 ‘접근 가능성의 한계’를 밀어붙이고 있다. DeepSeek MLA, Google TurboQuant, MIT×NVIDIA TriAttention, Blackwell FP4가 만들어내는 합산 효과는 단순한 비용 절감을 넘어 다음 세 가지 근본적 변화를 가능하게 한다.
첫째, AI 민주화의 가속. 32B 파라미터 모델을 단일 RTX 4090에서 구동할 수 있다는 것은, 수천만 원의 서버 없이도 개인 개발자가 최전선 모델을 로컬에서 실험할 수 있음을 의미한다. 이는 AI 혁신의 참여자 범위를 극적으로 확대한다.
둘째, 진정한 온디바이스 AI. 스마트폰과 노트북에서의 로컬 AI는 단순한 소형 모델의 배포가 아니라, 실질적인 능력을 가진 모델의 프라이버시 보장 로컬 구동을 의미한다. 메모리 효율화 없이 이 미래는 요원하다.
셋째, AI 서비스의 경제 재편. 메모리 비용이 서비스 단가에서 차지하는 비중이 줄어들면, AI 서비스의 진입 장벽이 낮아지고 더 많은 스타트업이 경쟁 가능한 AI 서비스를 구축할 수 있다. 이는 클라우드 AI의 독과점 구조에도 변화를 가져올 수 있다.
투자자 관점에서 보면, 이 기술 파도는 단순한 메모리 반도체 수요 감소 스토리가 아니다. 오히려 효율화→비용 하락→수요 확대→인프라 투자 증가의 선순환 사이클을 만들어내는 AI 성장의 다음 장이다. NVIDIA Blackwell, 저정밀도 연산 기반 소프트웨어 스택의 수혜, 그리고 온디바이스 AI 사이클을 주목하라.
메모리 효율화 전쟁은 이제 막 시작되었다. 그리고 그 전쟁의 승자는 AI를 더 많은 사람이 더 저렴하게 사용할 수 있게 만드는 쪽이다. 기술적으로도, 투자적으로도, 그 방향에 주목해야 할 때다.
이 글은 2026년 5월 기준 공개된 연구 논문, 기술 발표, 시장 분석을 바탕으로 작성되었습니다. 투자 관련 내용은 참고용이며, 실제 투자 결정은 전문 금융 자문가와 상의하시기 바랍니다.
참고 자료
- [2026.05.02경제리포트]2026년 APPLE의 사업 전략과 AI 혁신: 하드웨어 중심의 미래와 새로운 제품 라인업
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (DeepSeek-AI, 2024)
- TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate (Google Research, ICLR 2026, arXiv:2504.19874)
- TriAttention: Efficient Long Reasoning with Trigonometric KV Compression (MIT·NVIDIA·Zhejiang, 2026, arXiv:2604.04921)
- Hardware-Centric Analysis of DeepSeek’s Multi-Head Latent Attention (KU Leuven, arXiv:2506.02523)
- TransMLA: Multi-Head Latent Attention Is All You Need (arXiv:2502.07864)
- Towards Economical Inference: Enabling DeepSeek’s MLA in Any Transformer-based LLMs (arXiv:2502.14837)
- NVIDIA Blackwell Architecture Technical Brief (NVIDIA, 2025)
참고 기사